This article was published as a part of the Data Science Blogathon.
Data Science without data is similar to fishing without fish.
When we talk about structured data, Database is the word that comes first to mind. There are various types of databases, here we will be looking at the NoSQL database.
For the past few years, one of the most common ways to store data is by using NoSQL Databases. NoSQL databases AKA “non SQL” OR “not only SQL” are those databases that store data in a non-tabular format different from a relational database.
Today, we will be working with MongoDB, a widely used product for NoSQL databases, and learning how to use data inside MongoDB databases, for data science. You can learn more about the NoSQL database on the official site of MongoDB: NoSQL Explained.
Table of Contents:
- Pre-requisites
- Looking at MongoDB Compass
pymongomodule in Python- Getting ready for Data science
1. Pre-requisites
- MongoDB
- Before working with MongoDB Database, we need to install it. Here is the official installation guide for your personal working environment.
- MongoDB Compass
- For a simpler and easier explanation in this tutorial, we will be using the official interactive GUI for MongoDB databases, i.e. MongoDB Compass. Here is the installation guide for it.
- Python 3.7 or above
- Here is the link to install the latest stable Python 3 version.
pymongomodule for working with MongoDB client in Python. Install usingpip install pymongo- Data science libraries according to your particular use case, here I will be using only Pandas to create a DataFrame.
2. Looking at MongoDB Compass
After the successful installation of MongoDB Compass (refer to the link given in the above step), we will briefly explore its interface.
- Startup interface
.png)
NOTE: If you are using it for the first time, you might not see any recent entries.
- Connecting to your local Database
1.png)
.png)
NOTE: Admin, local, and config are the 3 databases that will be present in your MongoDB client by Default. We will be working with the admin database for demonstration purposes.
- Click on the admin database and open it. Most probably you will be seeing nothing in this database. This means that there is no data present in the database, so let’s create a collection (a group of all the documents/ entries in a database are collectively called the collection, it is similar to Relational Database’s Tables), and then inside the collection create few entries (in MongoDB terms: Documents).
Still if you have any doubts, you can quickly glance over the Glossary for MongoDB
.png)
.png)
.png)
- For creating the collection, we are choosing a very famous dataset: Iris Data Set, you can download the
.csvfile from the provided link. Here are the steps to import the dataset into our MongoDB admin database (as Tutorial Collection)
.png)
.png)
Select the iris.csv file that you downloaded from the dataset above.
.png)
Note: Remember to check and change the data type of columns; if necessary before importing.
.png)
Here is how your ‘Tutorial’ collection would look like after the successful import of Iris data from the .csv file.
.png)
3. Pymongo Module in Python
Great!! you have successfully got your hand dirty with MongoDB while creating a new collection in the MongoDB database. Now, let’s explore how to bridge the MongoDB data and Python using pymongo.
To install the module, you need to simply write pip install pymongo in your terminal.
import pymongo
# Getting the access to local MongoDB databases databases = pymongo.MongoClient()
# Getting the access to `admin` database from the group of other databases present admin_db = databases.admin
# Getting the access to 'Tutorial' collection that we just created inside `admin` database tutorial_collection = admin_db.Tutorial
# Now this is where our imported `iris` data is stored.
#To fetch one entry/record/document from the collection we can write:
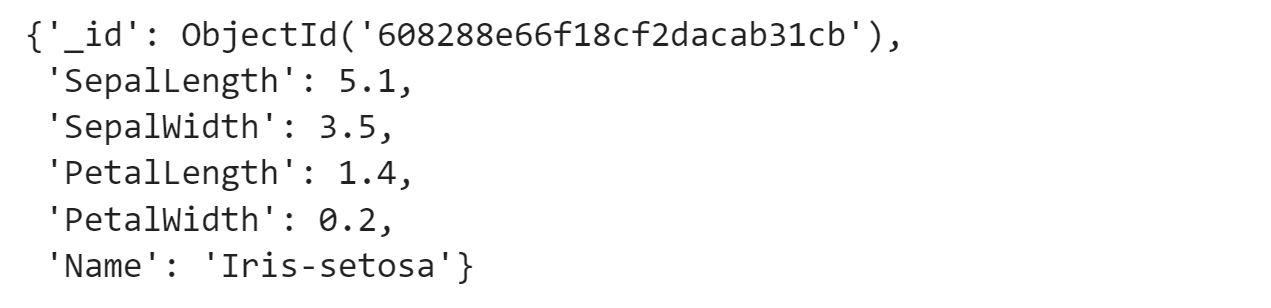
tutorial_collection.find_one({})
tutorial_collection.find({})
Note: pymongo cursor object is iterable, so here we converted it into a list to glance at all the values.
list(tutorial_collection.find({}))

the list goes on till all the 150 values of the iris dataset.
4. Getting ready for Data Science
We are onto the final stage that would join this tutorial to further down the line data science/ Analytics tasks.
We need to create a DataFrame using pandas for our MongoDB Tutorial Collection. Let’s see how we can do that in Jupyter notebooks for better interactivity.
import pandas as pd
iris_df = pd.DataFrame(list(tutorial_collection.find({})))
iris_df
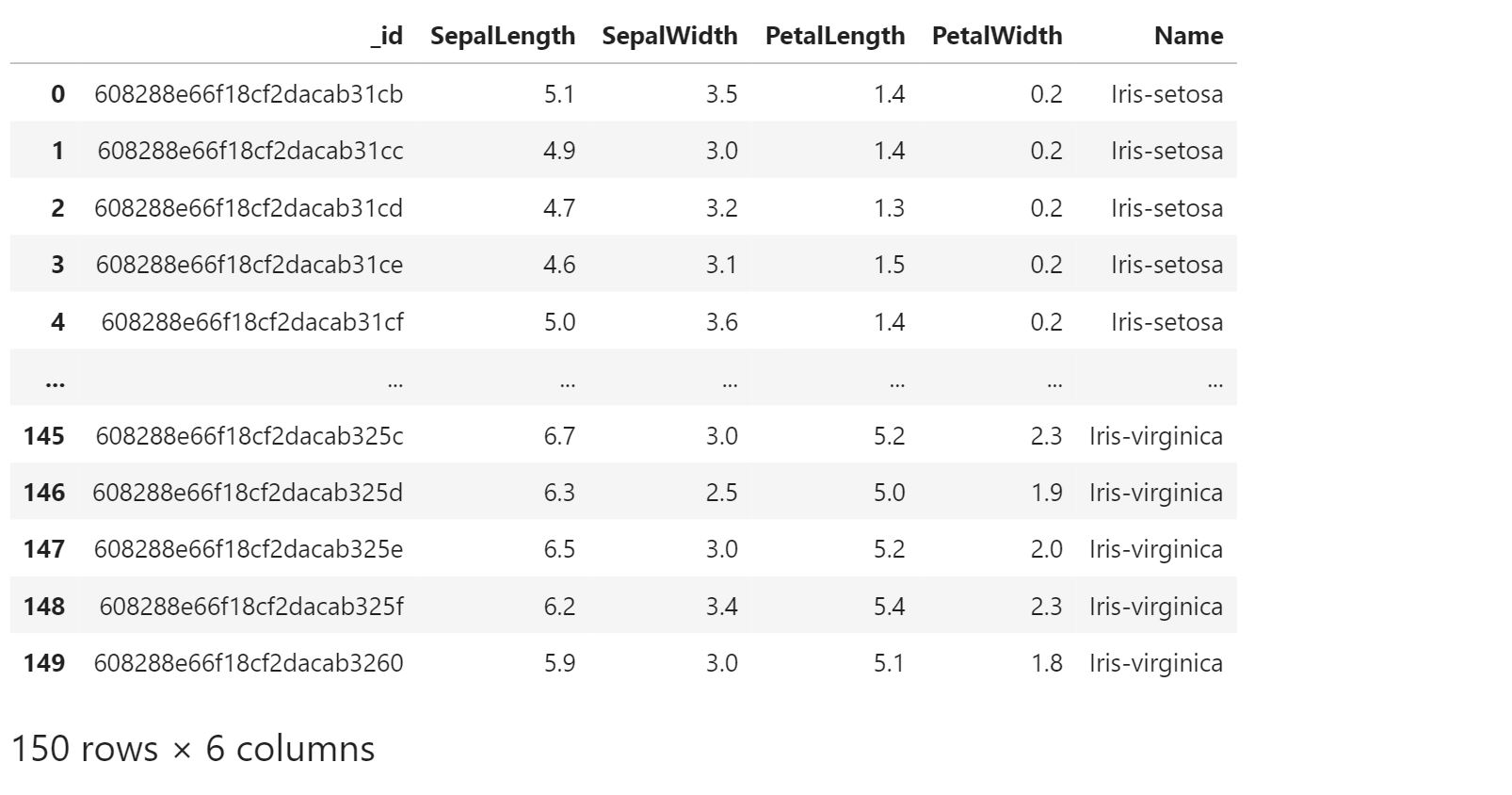
If you don’t want some of the columns you can clean them in 2 ways:
- First is before retrieving the data from database to python code using MongoDB aggregate pipelines(Out of the scope of the tutorial),
- The second is data cleaning after creating the DataFrame of the data.
# we will clearn the `id` columns by second approach,
iris_df = iris_df.drop("_id", axis=1)
iris_df.head()
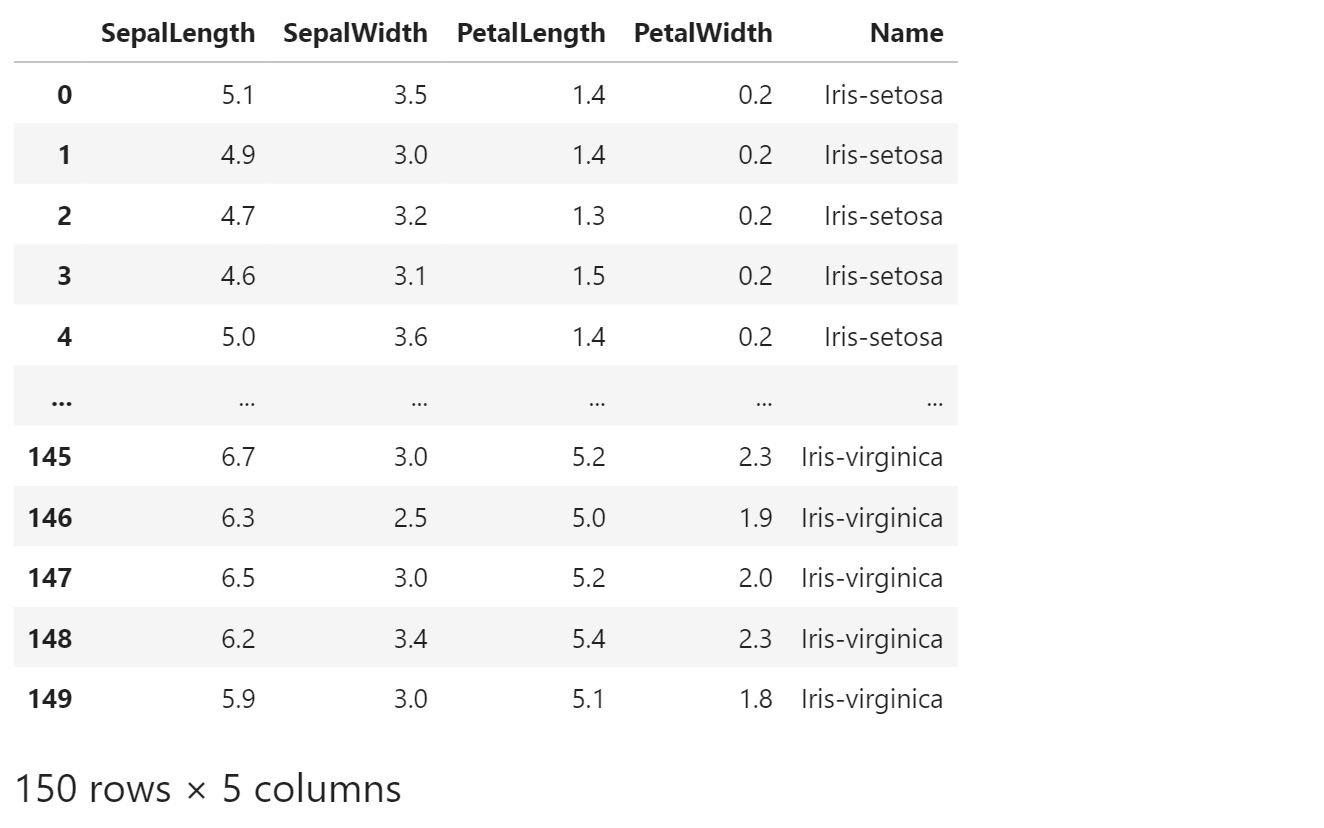
You have reached the end of this tutorial. Now further down the line, you can write the same code as any other data science/analytics task. From this point onwards, you can be as flexible as would want with your data science skills.
Additional Information:
MongoDB offers the functionality of aggregate pipelines (mentioned once above) to filter, pre-process, and in general create use-case-specific data pipelines. With proper logic and built, they can be really powerful to retrieve refined and enriched data from the output of that pipeline. It is several times computationally faster than achieving the same result in python or any interpretable language after creating a DataFrame.
Gargeya Sharma
B.Tech in Computer science (3rd year)
Specialized in Data Science and Deep learning
Data Scientist Intern at Upswing Cognitive Hospitality Solutions
For more information, check out my GitHub Home Page.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






You did a great work gargeya