This article was published as a part of the Data Science Blogathon.
What is DataBricks?
Databricks is a cloud-based analyzing tool that can be used for analyzing and processing massive amounts of big data. Databricks is a product of Microsoft cloud that used Apache Spark for computation purposes. It allows users to combine their data, ELT processes, and machine learning in an efficient manner. Databricks worked on a parallel distributed system, which means the workload is automatically split across various processors as a result it offers high scalability and sharding. Thus indirectly effects in reduced processing time and cost.
FEATURES OF DATABRICKS
- Databricks can be used to process massive, unstructured data in real-time
- Facilitates disseminating of collected big data throughout distributed clusters
- Had provision to collect and store raw data from IoT devices, machines, files, etc.
- Integrates Apache Spark
- Facilitates solution to run on and scale to a large number of machines and systems
- Collected big data can be easily analyzed and processed to build models
- Supports Real-time Batch Processing
- Consolidates, Cleanses, and Normalizes data from multiple disparate sources.
- Helps save storage capacity and improves query performance
- Supports SQL-based analytics functions like Time series, pattern matching, etc.
This Spark-based environment is very easy to use. It gives provisions to use the most commonly used programming languages like Python, R, and SQL. These languages are later converted through APIs to interact with Spark. As a result data processing and computation become an easy task.
Its computing power can be again increased by connecting it with an external database like MongoDB. In this way, we can process the massive amount of data in a short span of time.
What are MongoDB and MongoDB Atlas?
MongoDB
MongoDB is an open-source document database built on a horizontal scale-out architecture.It was founded in 2007 by Dwight Merriman, Eliot Horowitz, and Kevin Ryan, who co-founded MongoDB in NYC. Instead of storing data in tables of rows or columns like SQL databases, each row in a MongoDB database is a document described in JSON formatting language.
Features of MongoDB
- MongoDB is an open-source document database
- Data objects are stored as separate documents inside a collection.
- Each MongoDB instance can have multiple databases and each database can have multiple collections.
- Provides high performance, high availability, and automatic scaling.
- Replication and high availability
- Auto-Sharding
- Server-side JavaScript execution
- GridFS is used for storing and retrieving files.
- High Availability
- MongoDB can control changes in the structure of documents with the help of schema validation.
- Using MongoDB we can create Binary JSON format (BSON) files this will increase efficiency.
- Data stored in BSON can be easily searched and indexed, which tremendously increases the performance.
MongoDB Atlas
MongoDB Atlas is a specialized version of MongoDb that provides easy cluster formation and easy deployments. MongoDb provides a way to store millions of data efficiently.•MongoDB belongs to the NoSQL databases category, while MongoDb Atlas can be primarily classified as hosting that provides an easy way to deploy the cluster. This provides strong authentication and encryption features that ensure data protection.
Features of MongoDB Atlas
- MongoDB Atlas is a fully managed cloud database for modern applications.
- MongoDB Atlas can be primarily classified under “MongoDB Hosting”
- MongoDB Atlas offers many features when compared with local MongoDB
- MongoDB Atlas Atlas comes with MongoDB Atlas Search built-in, making it easy to build fast, relevant, full-text search capabilities on top of MongoDB data.
- No infrastructure on the client-side.
- Easy to use
- Easy to scale up and down.
- .It has strong authentication and encryption features that make sure that developers
- Drivers are available so deployment is easy
- GIves options to upload data in JASON and CSV Format
How to connect MongoDB Atlas with Databricks?
In order to connect databricks with MongoDB, one can make use of some packages available from maven. Some tutorials are already available for connecting Databricks with Mongodb through scala driver. But none of them give a clear picture of connecting MongoDB Atlas and Databricks through Python API.
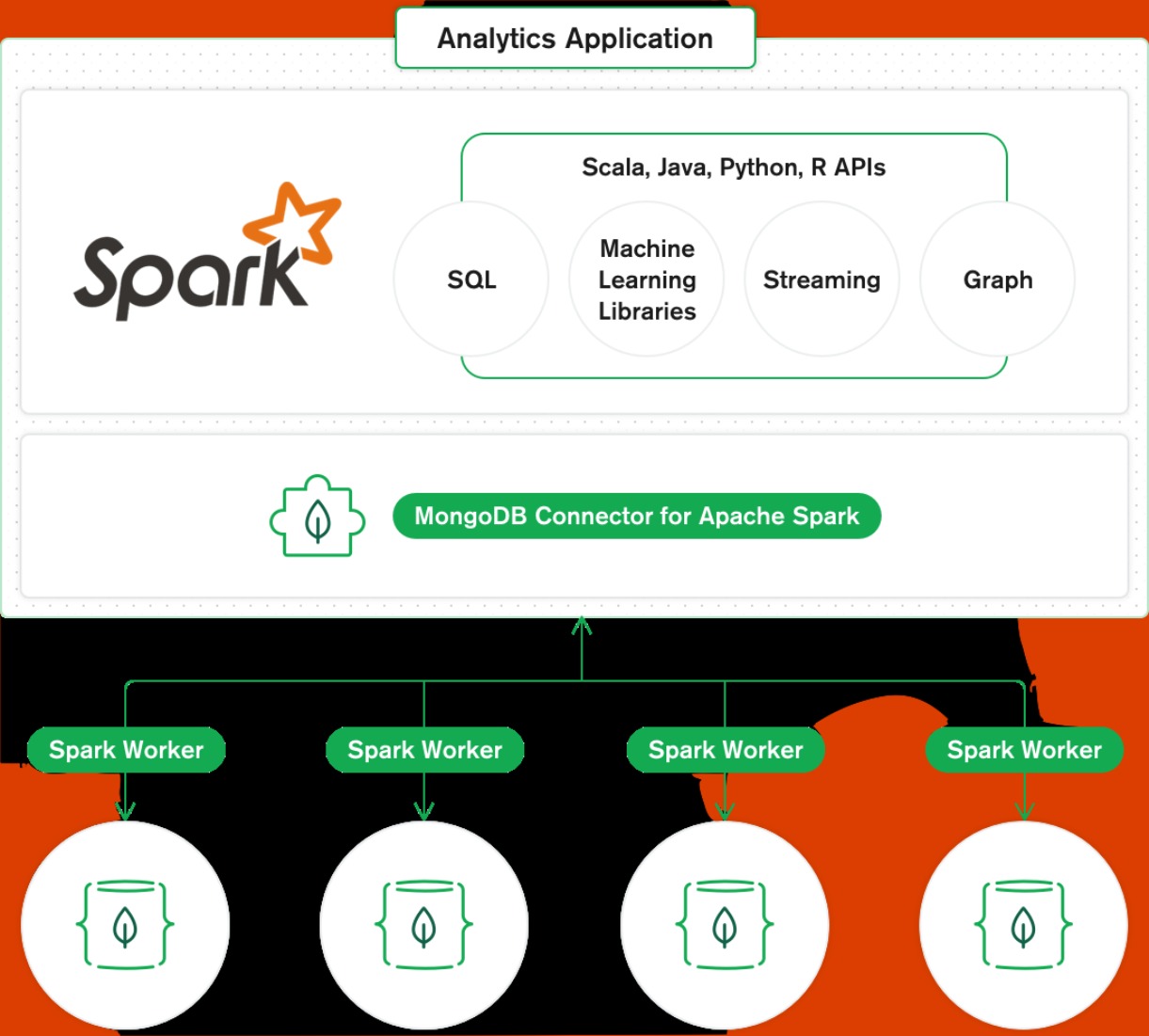
source: google
Let’s have a look at the prerequisites required for establishing a connection between MongoDB Atlas with Databricks.
STEP 1
Create Databricks Cluster and Add the Connector as a Library
- Create a Databricks cluster.
- Navigate to the cluster detail page and select the Libraries tab.
- Click the Install New button.
- Select Maven as the Library Source.
Enter the MongoDB Connector for Spark package value into the Coordinates field based on your Databricks Runtime version:
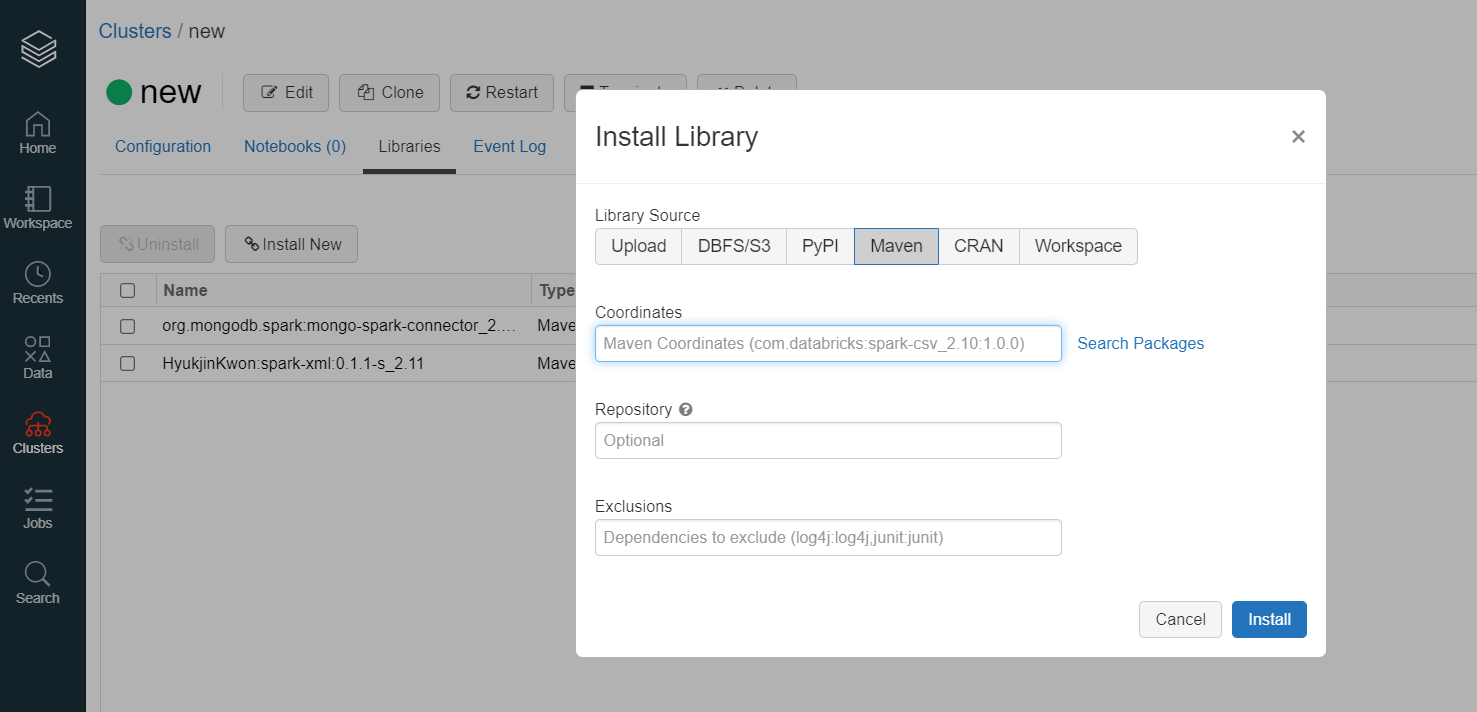
Eg: For Databricks Runtime 7.6 (includes Apache Spark 3.0.1, Scala 2.12)
Select org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 or
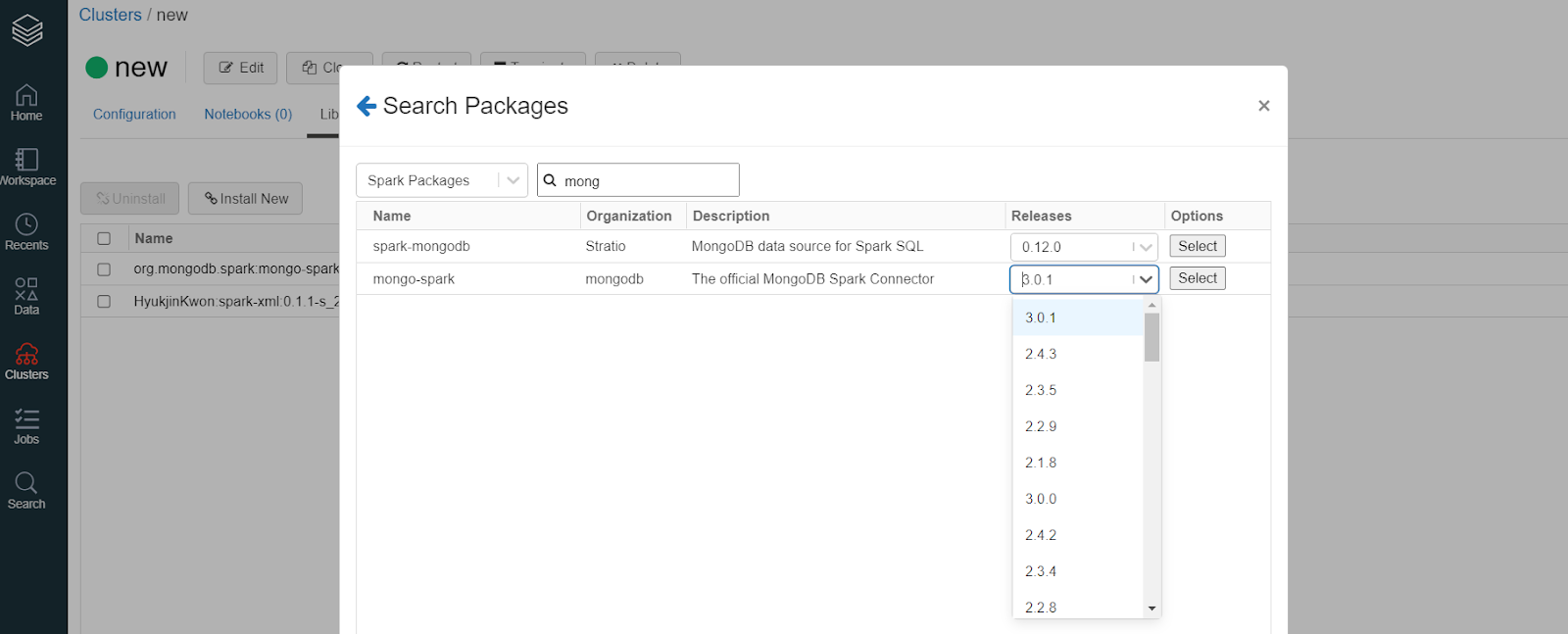
Give extra care to search in packages and find the package that supports your spark and scala version.
STEP 2
Install Spark XML
Install Spark xl from libraries and restart the cluster.
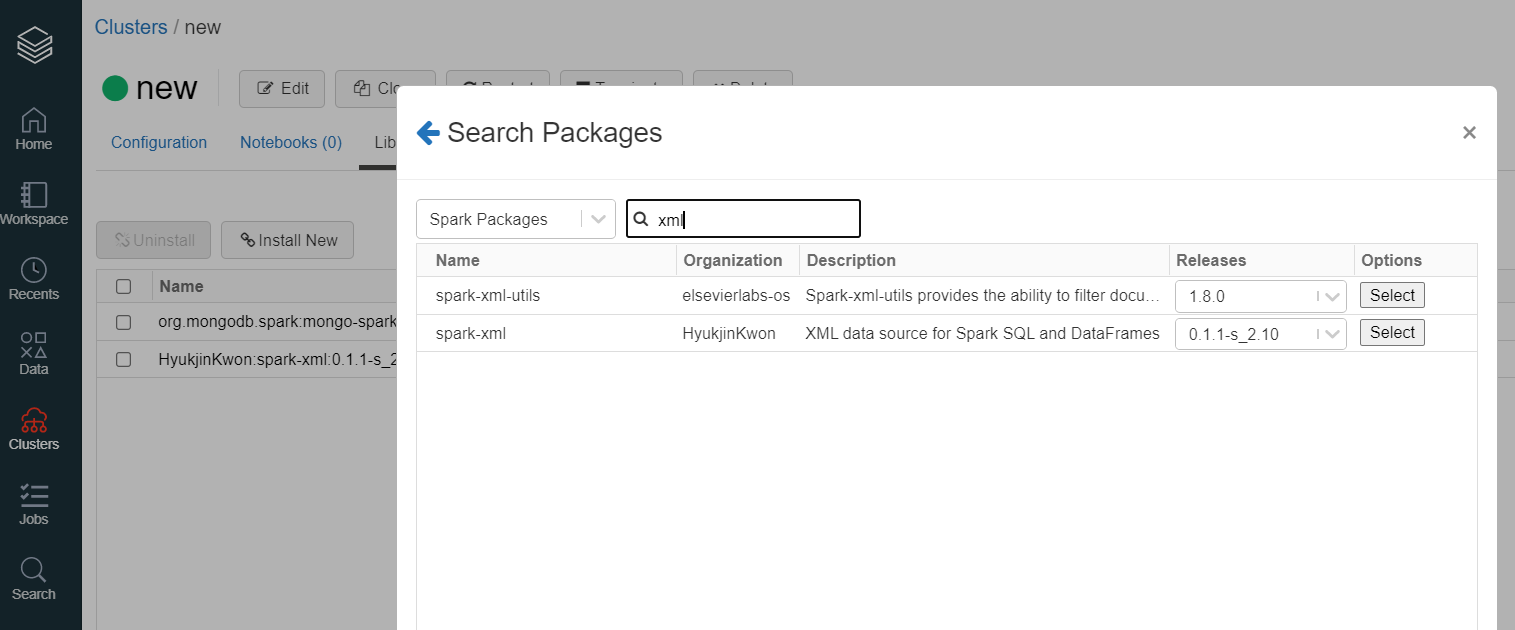
STEP 3
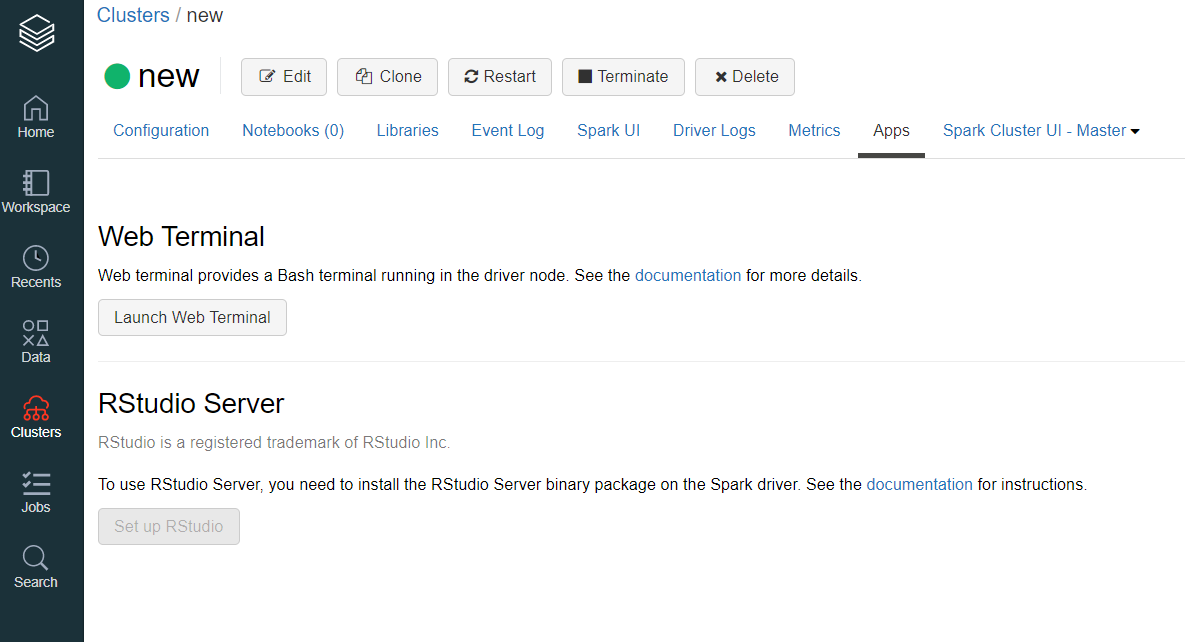
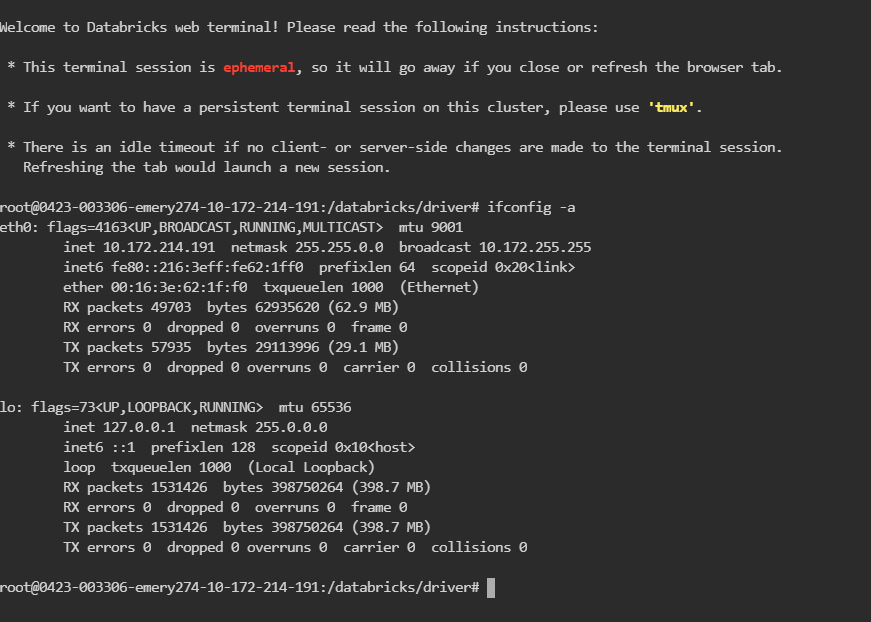
Note down the cluster IP address
We can take IP address by launching Web Terminal from Apps tab in databricks – Cluster.
Type ifconfig -a in the shell to get the IP address.
STEP 4
1.Prepare a MongoDB Atlas Instance
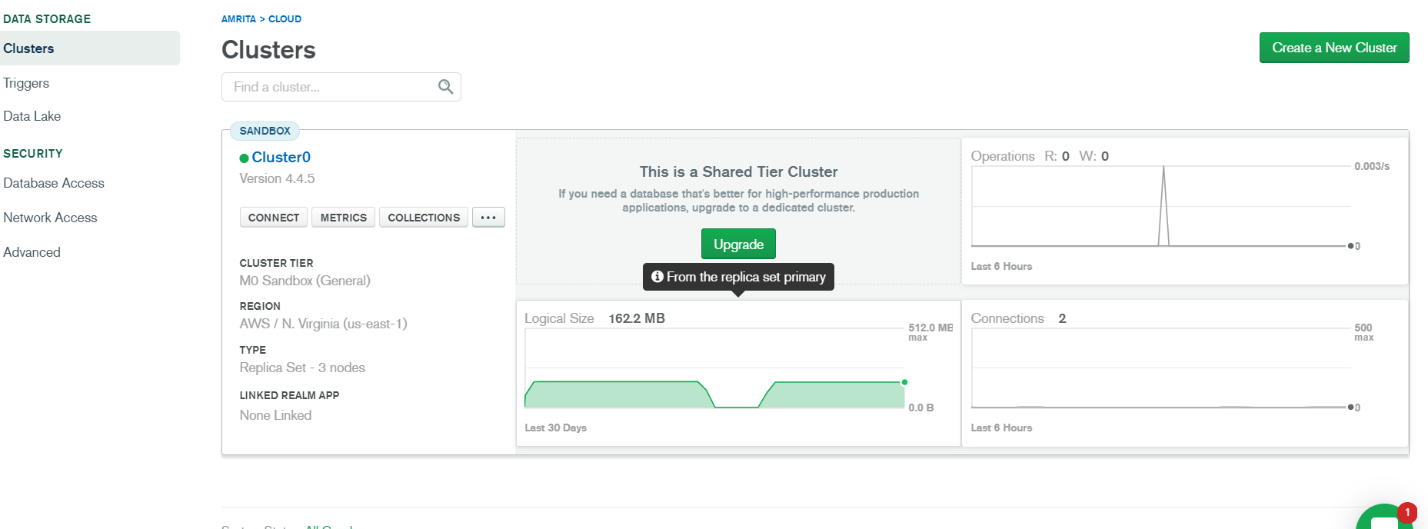
1.Create an account in MongoDB Atlas Instance by giving a username and password.
2. Create an Atlas free tier cluster. Click on Connect button.
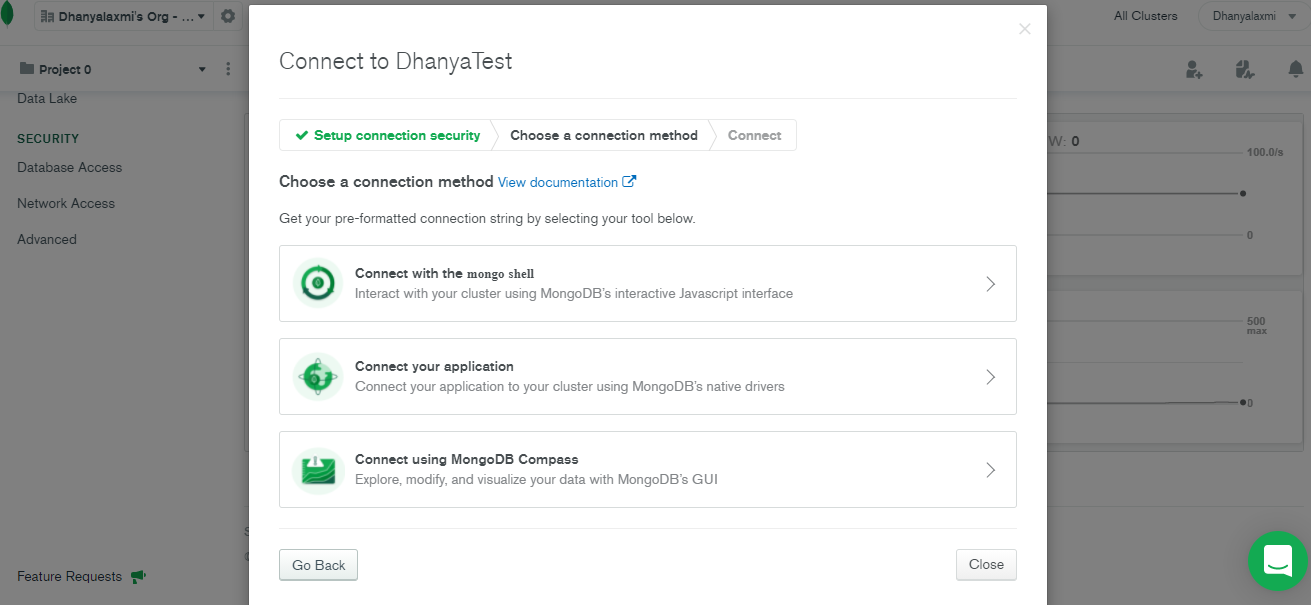
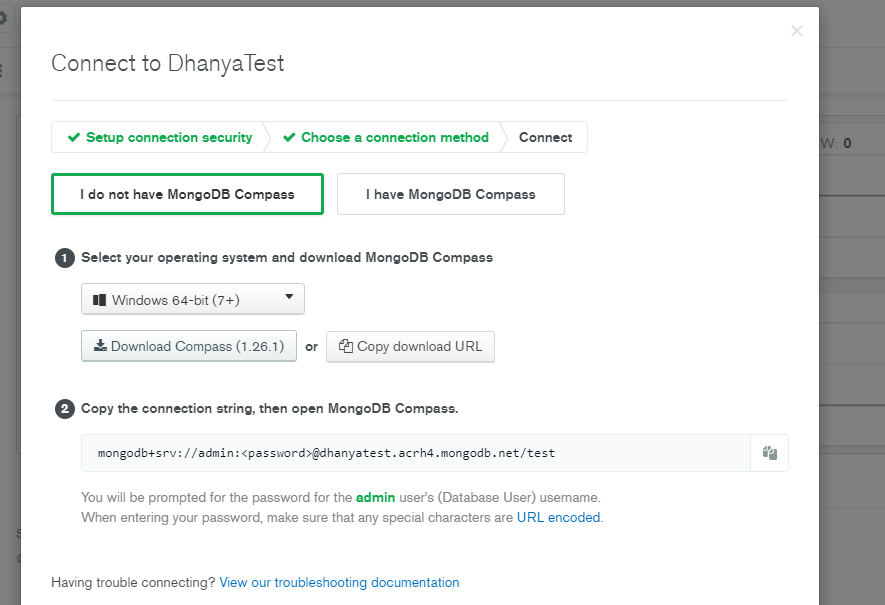
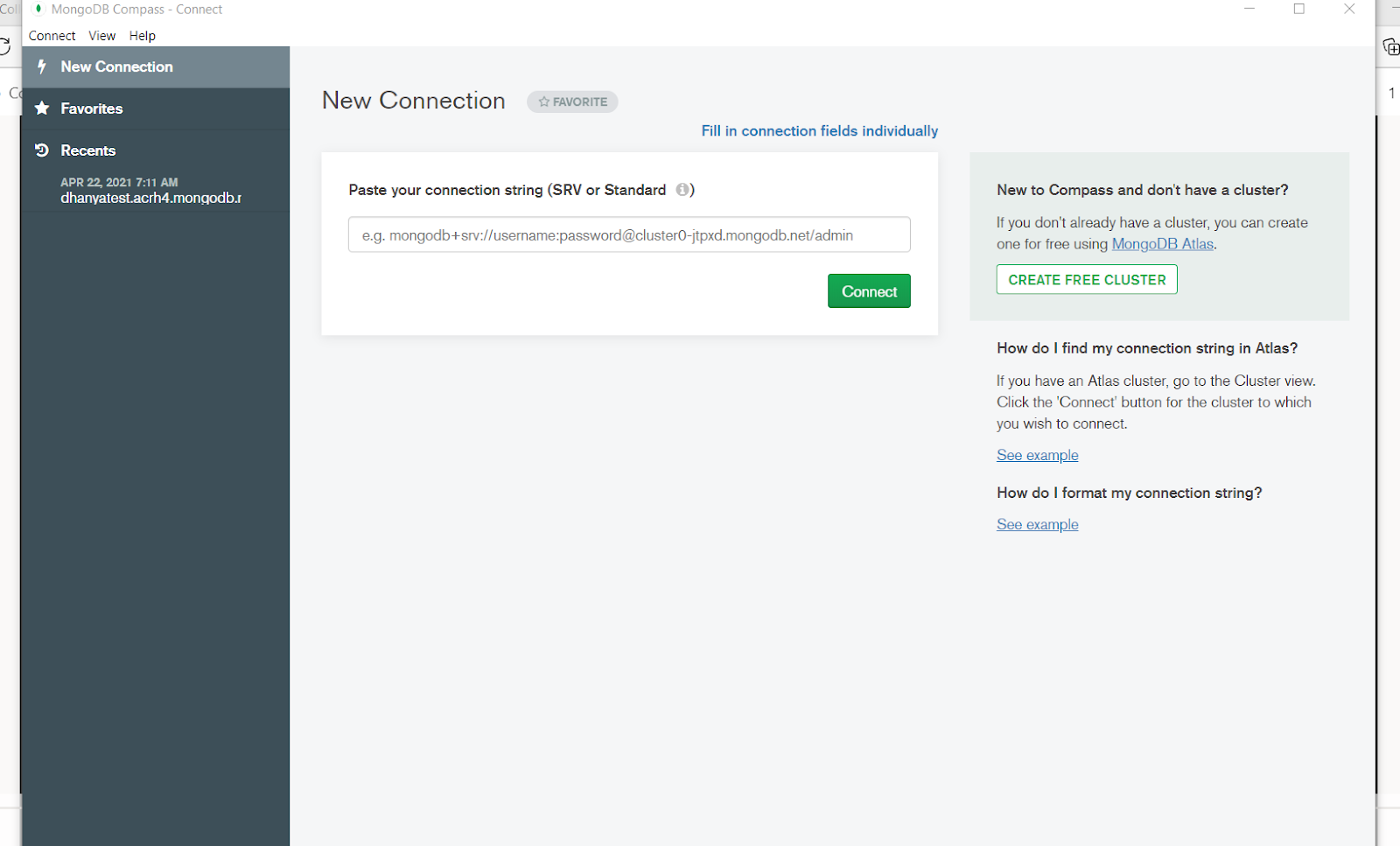
3. Open MongoDB Compass and connect to database through string (don’t forget to replace password in the string with your password).
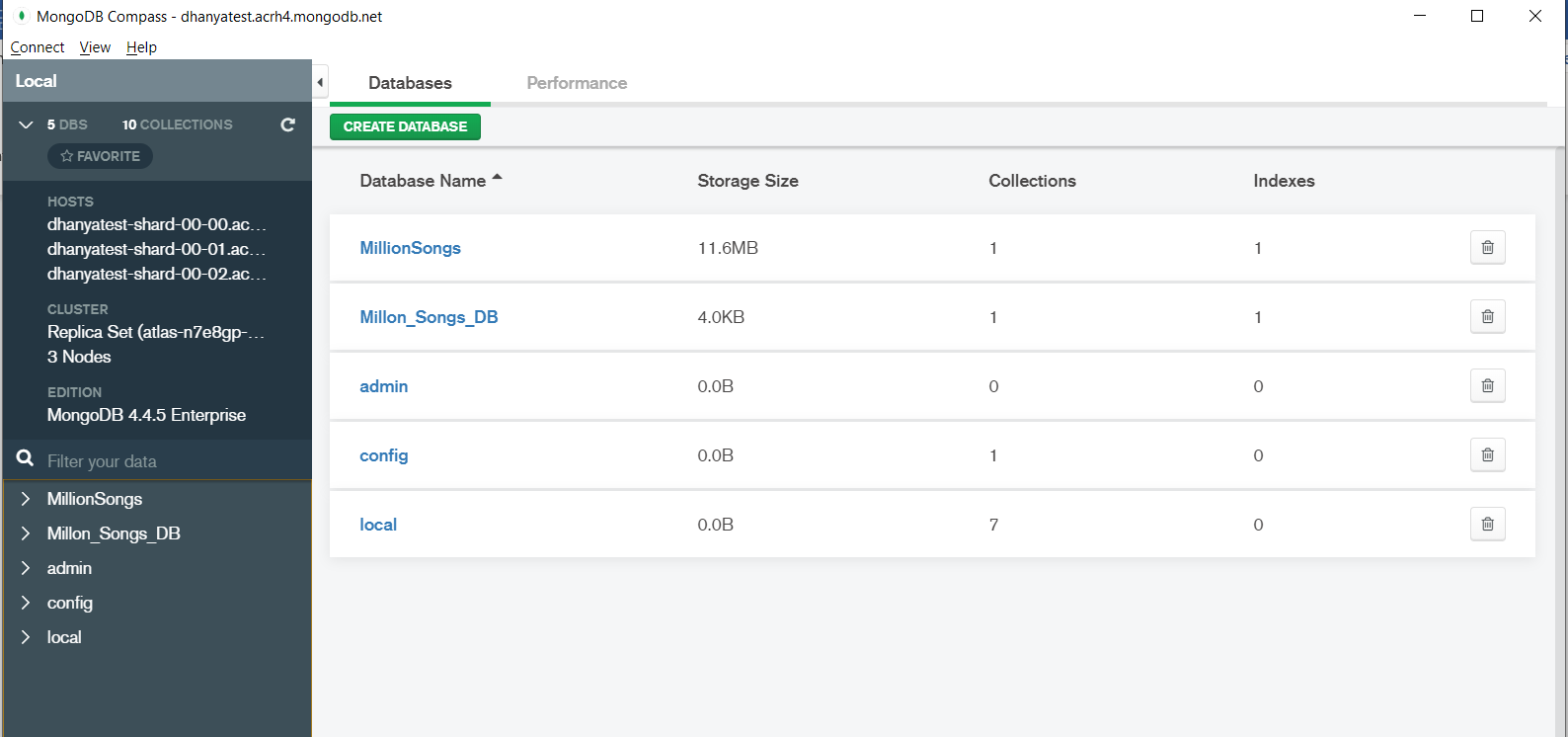
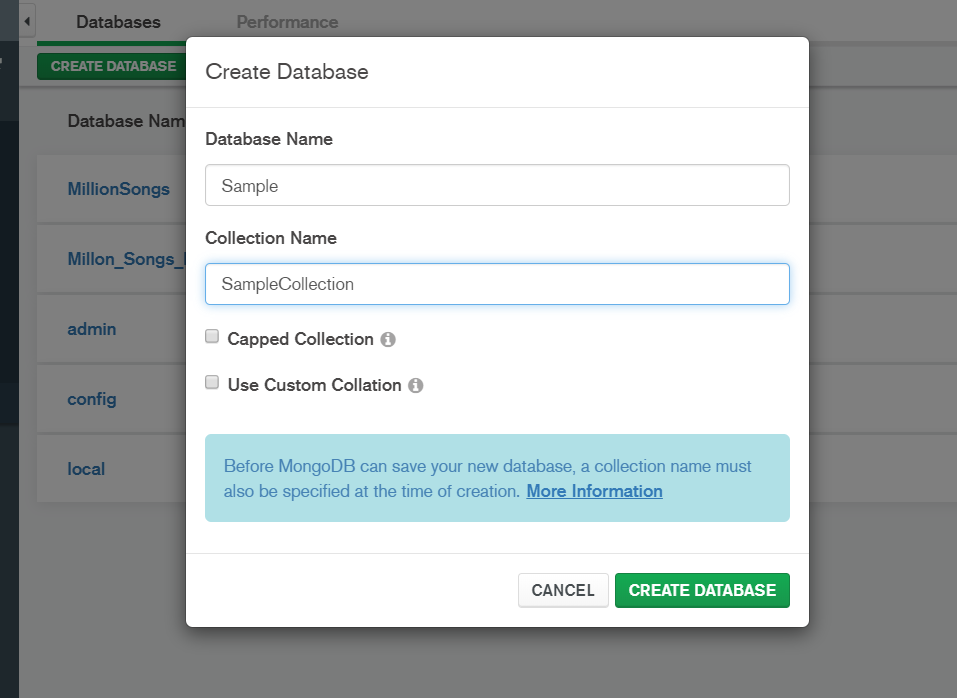
4.Open MongoDB Compass. Create a New database to save your data by clicking on the CREATE DATABASE button.
5.Import your document as a collection by clicking on the Import Data Button.
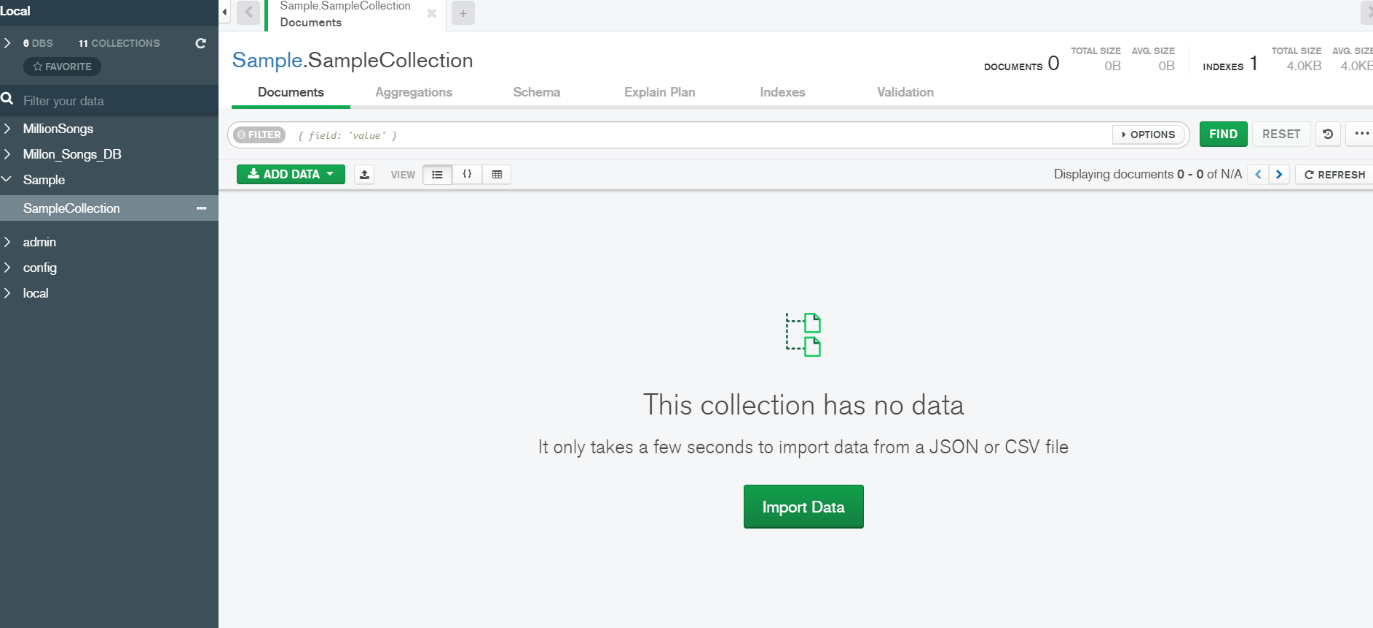
NOTE: To explore and manipulate your MongoDB data easily, install MongoDB Compass by clicking on I do not have MongoDB Compass button. Copy the connection string to connect to the MongoDB Atlas cluster from MongoDB Compass.
String looks like this
mongodb+srv://<user>:<password>@<cluster-name>-wlcof.azure.mongodb.net/test?retryWrites=true
2. Connect MongoDB Atlas with DataBricks
1.Connection with databricks
Enable Databricks clusters to connect to the cluster by adding the external IP addresses for the Databricks cluster nodes to the whitelist in Atlas.
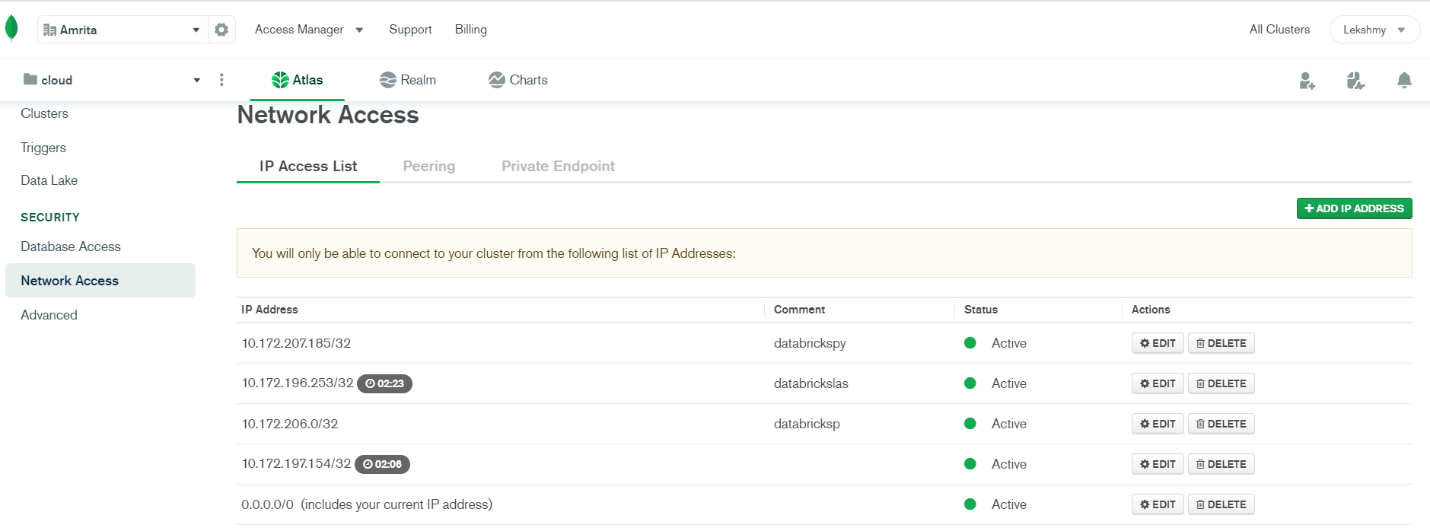
For that take network access on MongoDB and add the Databrick cluster IP address there.
2. Configure Databricks Cluster with MongoDB Connection URI
- Get the MongoDB connection URI. In the MongoDB Atlas UI, click the cluster you have created.
- Click the Connect button.
- Click Connect Your Application.
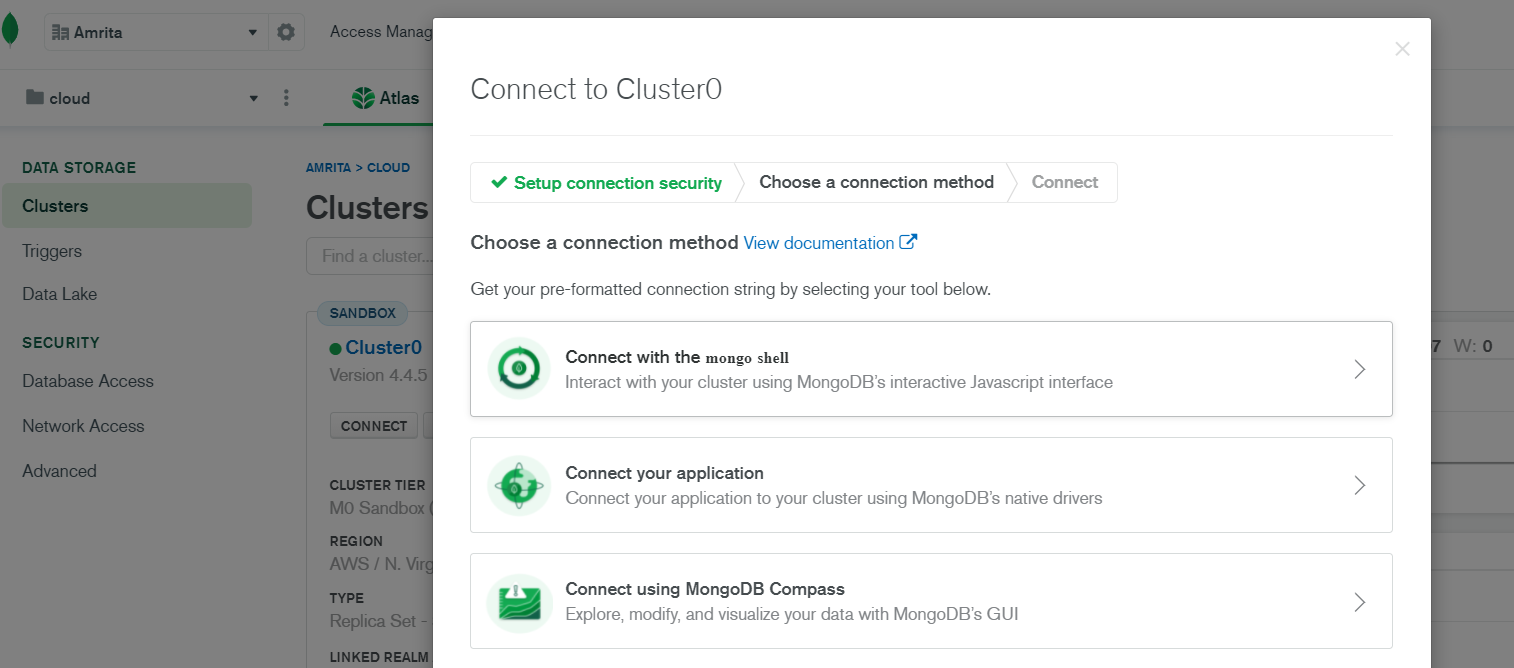
- Select Python in the Driver dropdown according to your Databrick-MongoDB connector configuration(make ensure your scala and spark version are the same)
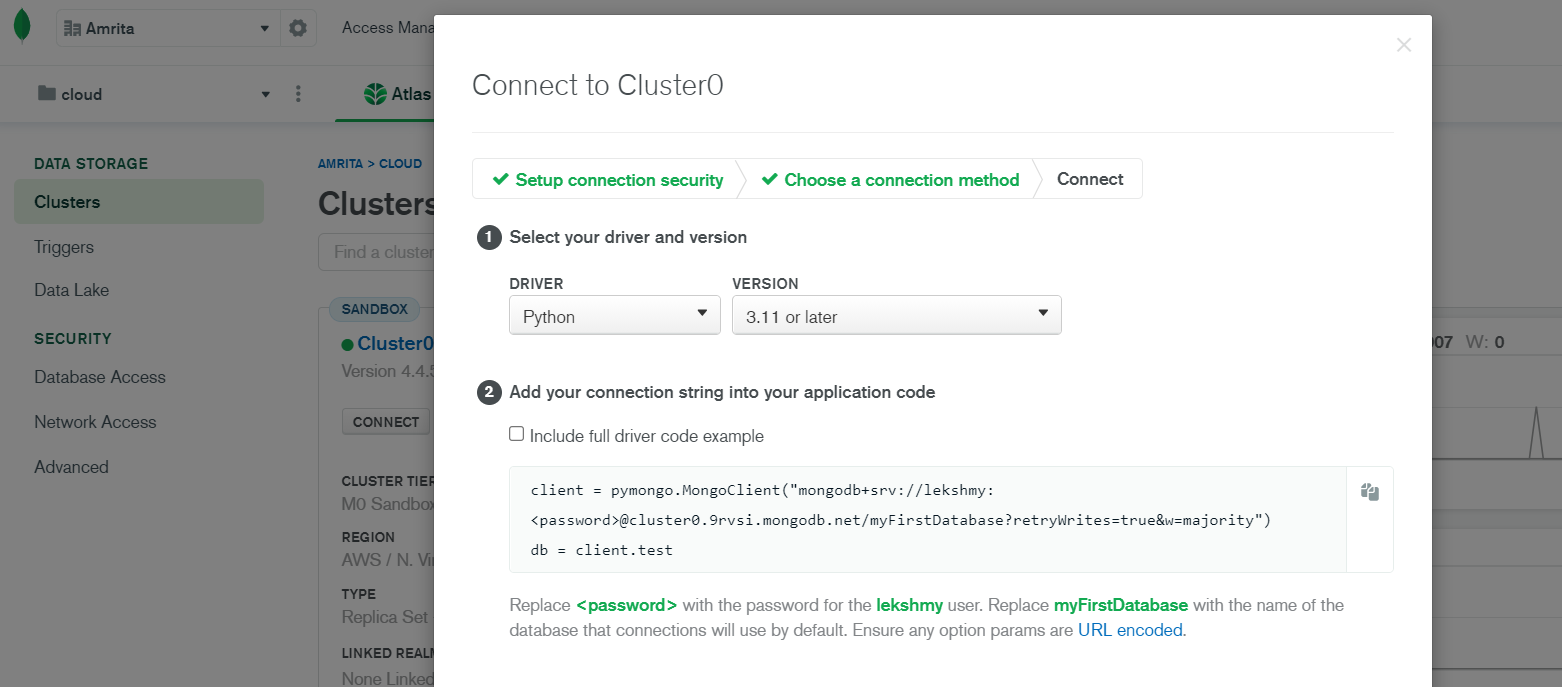
- Copy the generated connection string. It should look like mongodb+srv://<user>:<password>@Firstdatabase-wlcof.azure.mongodb.net/test?retryWrites=true
- Replace password and Firstdata base name with your password and database name.
3. Configuration in DataBricks
METHOD 1
- In the cluster detail page for your Databricks cluster, select the Configuration tab.
- Click the Edit button.
- Under Advanced Options, select the Spark configuration tab and update the Spark Config using the connection string you copied in the previous step: Follow the below format in the config tab
spark.mongodb.output.uri<connection-string>
spark.mongodb.input.uri<connection-string>
Through python notebook, read the file
METHOD 2(More preferable)
Configure settings directly in python notebook through the below code
from pyspark.sql import SparkSession
database = "cloud" your database name
collection = "millionsongs"your collection name
connectionString= copy your connection string here ('mongodb+srv://user:<password>@cluster0.9rvsi.mongodb.net/<database>?retryWrites=true&w=majority')
spark = SparkSession
.builder
.config('spark.mongodb.input.uri',connectionString)
.config('spark.mongodb.input.uri', connectionString)
.config('spark.jars.packages', 'org.mongodb.spark:mongo-spark-connector_2.12:3.0.1')
.getOrCreate()
# Reading from MongoDB
df = spark.read
.format("com.mongodb.spark.sql.DefaultSource")
.option("uri", connectionString)
.option("database", database)
.option("collection", collection)
.load()
The media are shown in this article on ‘How to connect databricks and MongoDB Atlas’ are not owned by Analytics Vidhya and is used at the Author’s discretion.


