This article was published as a part of the Data Science Blogathon.
What is Kaggle?
Kaggle is a vast online community of professionals and practitioners in the domain of Machine Learning where they meet and share their knowledge. Whether you are a beginner or an expert, Kaggle may have come or might come in handy during your journey in the domain. Kaggle was established in 2010, where it used to host Machine Learning competitions, later acquired by Google.
Using Kaggle gives a variety of features for the user’s help. One can come and show off their skills by participating in competitions which would help them fill their pocket. Kaggle also hosts several fora based on different topics of highly qualified and kind people from the globe. Apart from this, you can learn to code and solve numerous problems available on the platform. One of the leading reasons you may or you might have heard about Kaggle is the number and variety of open-source datasets it hosts. The best part of Kaggle is, even you can host your dataset if it holds a little value to be analyzed or to train one’s model.
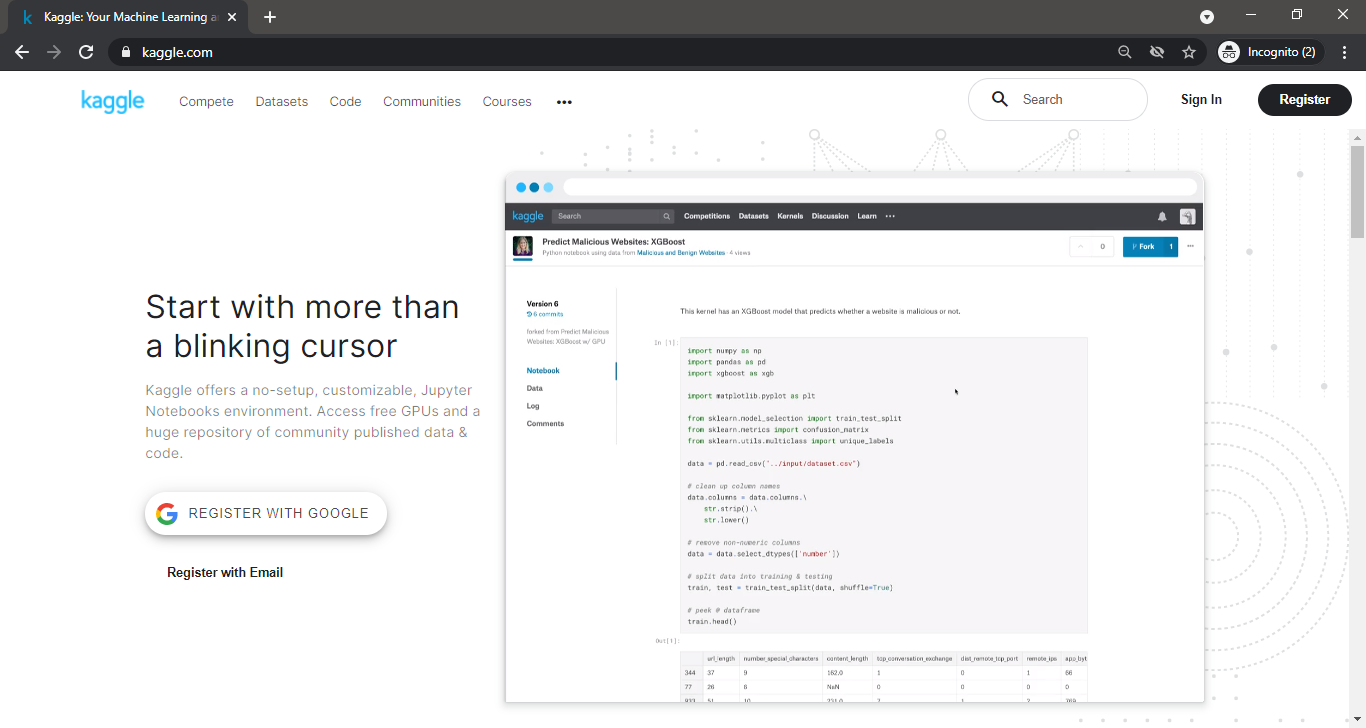
Downloading Kaggle Datasets (Conventional Way):
The conventional way of downloading datasets from Kaggle is:
1. First, go to Kaggle and you will land on the Kaggle homepage.
2. Sign up or Sign in with required credentials.
3. Then select the Data option from the left pane and you will land on the Datasets page.
4. Now from the variety of domains, select the datasets that match best of your needs and press the Download button.
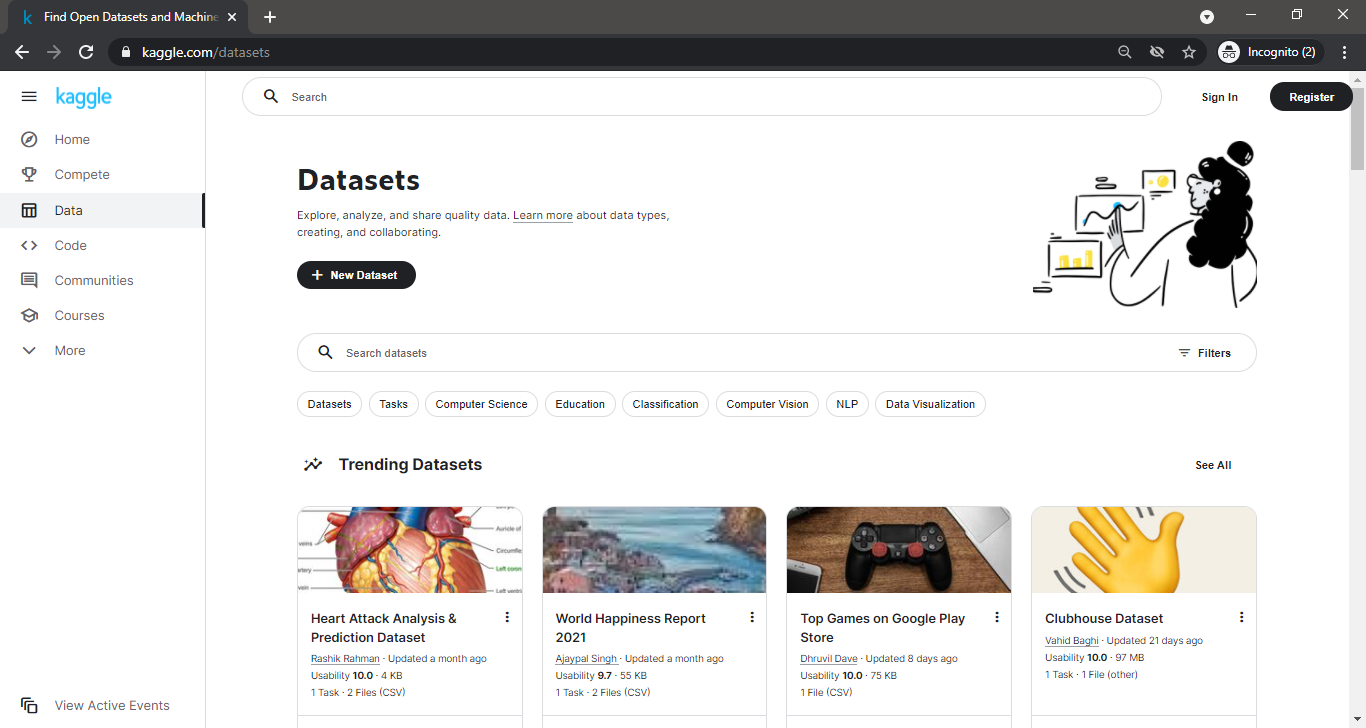
If you are unaware or confused about which dataset you should select, Kaggle has got you covered. Kaggle has several updated lists of Datasets based on the interest of the viewer. For example, when you land upon the Kaggle Datasets page, you will find multiple lists of Datasets, such as Trending Datasets, Popular Datasets, Datasets related to Businesses, Datasets related to COVID, and so on.
Apart from this, if you are specific with the dataset you want, you can always use the Filters and select the file type and the desired dataset’s file size.
Downloading Kaggle Dataset in Jupyter Notebook
Now, let’s look at the new method to download Kaggle Dataset.
Before starting, you need to have the opendatasets library installed in your system. If it’s not present in your system, use Python’s package manager pip and run:
!pip install opendatasets
in a Jupyter Notebook cell. Python’s opendatasets library is used for downloading open datasets from platforms such as Kaggle.
The process to Download is as follows:
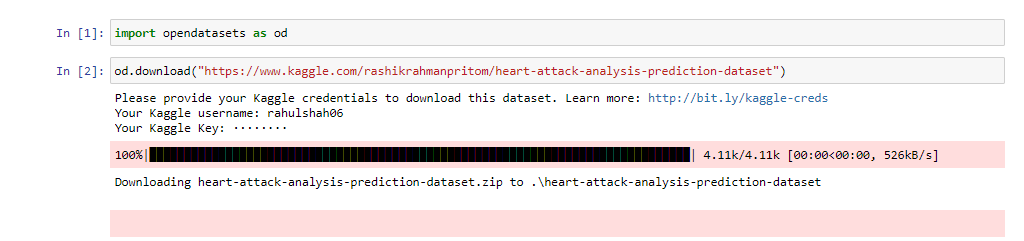
1. Import the opendatasets library
import opendatasets as od
2. Now use the download function of the opendatasets library, which as the name suggests, is used to download the dataset. It takes the link to the dataset as an argument.
For example, If I have selected the Heart Attack Analysis & Prediction Dataset to download. I will select its hyperlink. Now, this hyperlink is used as an argument in the .download() function.
od.download("https://www.kaggle.com/rashikrahmanpritom/heart-attack-analysis-prediction-dataset")
3. On executing the above line, it will prompt for Kaggle username. Kaggle username can be fetched from the Account tab of the My Profile section.
4. On entering the username, it will prompt for Kaggle Key. Again, go to the account tab of the My Profile section and click on Create New API Token. This will download a kaggle.json file.
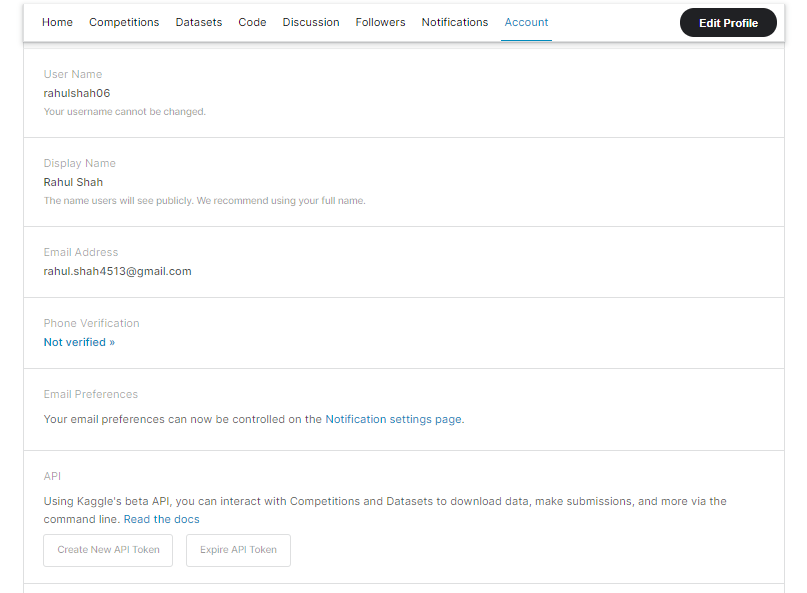
5. On opening this file, you will find the username and key in it. Copy the key and paste it into the prompted Jupyter Notebook cell. The content of the downloaded file would look like this:
{"username":<KAGGLE USERNAME>,"key":"<KAGGLE KEY>"}6. A progress bar will show if the dataset is downloaded completely or not.
7. After successful completion of the download, a folder will be created in the current working directory of your Jupyter Notebook. This folder contains our dataset.
Your Jupyter Notebook should look like this:
NOTE: Remember, that you don’t have to create a new API Token from Kaggle every time you want to download a dataset. You can use the same key for every single download.
The Kaggle Dataset Page
Datasets play a vital role in one’s journey in achieving higher highs in the domain of Machine Learning. Thus, one must know every possible way to fetch the datasets. Kaggle is the most widely used platform for downloading dataset. Thus, you can get large varieties of datasets uploaded by the field experts.
Apart from the title, each dataset in Kaggle has more attributes such as Usability Score, the publisher, the size, and the dataset format. When you open a dataset, you will find these details. The Usability Score is given by certain parameters. For this score, it is not mentioned what range of score is a good Usability Score, but it is always good to start with high Usability Score dataset. Each dataset also shows the size of the dataset to be downloaded. A larger file size would take more time to load in the data frame. For example, the popular dataset US Accidents has about 4.2 Million Rows and has a file size of about 300 MBs. Thus, it would take varied times to load into a dataframe. It also shows the file format in which data is present. Knowing these details of your dataset can also be beneficial.
.png)
One can practice and share their findings in the Code section of Dataset’s page for each dataset. You will find several submissions by Kaggle members on every dataset page. Also, the Publisher of the dataset can post any Task which one can aim and work towards it. Since there is no single solution to any problem in Machine Learning, it is always good to see and learn from others. This may help you in your next projects. For example, the COVID-19 Open Research Dataset Challenge dataset has a file size of 9 GBs and over 1500 Code Submissions.
Selecting perfect data for your need needs time. It may happen several times that you might download a dataset that is not prepared as per your need. Thus it is always propitious to read the Dataset descriptions of what it is offering. For example, if you want to analyse the dataset based on COVID 19 Vaccination Programs worldwide, you will find an enormous number of such datasets fulfilling your interest. In such a situation, it is always helpful to read and select the perfect dataset for you.
Apart from this, Kaggle also provides Free Courses to improve Data Science skills such as Python, Data Cleaning, Data Visualization et cetera. You will get a completion certificate as well on the successful completion of a course.
Conclusion
Thus, opendatasets is a boon for the practitioners who are aiming to excel in the domain. Dataset is an essential part of every Data Science project. Your every bit of analysis starts with the data. Execution of a task in Python can be done most efficiently. And when it comes to downloading datasets, your ultimate task is to get the datasets with the least efforts possible.
Conclusively, the conventional method of downloading the dataset from Kaggle isn’t too difficult to procure, the above-stated Jupyter Notebook method is advantageous relatively in ways such as:
1. You don’t have to necessarily sign in to Kaggle if you are downloading directly from Jupyter Notebook. You can use your username and key when prompted.
2. You save yourself from the hassle of transferring the downloaded file from the browser to copying it to your Notebook’s directory. The file will get downloaded at the current working directory only.
3. It’s always good to know alternate solutions to an existing solution.
Don’t forget to check out my previous article here.
IT Engineering Graduate currently pursuing Post Graduate Diploma in Data Science.






This was such a life saver. Thank you!
Thank you. It is clear steps.