Real-world data collection has its own set of problems, It is often very messy which includes missing data, presence of outliers, unstructured manner, etc. Before looking for any insights from the data, we have to first perform preprocessing tasks which then only allow us to use that data for further observation and train our machine learning model. Missing value in a dataset is a very common phenomenon in the reality. In this blog, you will see how to handle missing values for categorical variables while we are performing data preprocessing. Missing value correction is required to reduce bias and to produce powerful suitable models. Most of the algorithms can’t handle missing data, thus you need to act in some way to simply not let your code crash. So, let’s begin with the methods to solve the problem.
“Data is the fuel for Machine Learning algorithms”.
Table of contents
What are Missing Values in a Dataset?
In a dataset, missing values refer to the absence of data for one or more variables or observations. This can occur for various reasons, such as data entry errors, equipment malfunction, or participants failing to provide information. Missing values can affect statistical analyses, leading to biased or incorrect results. Thus, it is important to handle missing values appropriately by removing them or using imputation methods to estimate their values.
Types of Missing Data
- Missing Completely at Random (MCAR): When data is MCAR, the missingness occurs randomly, and there is no relationship between the missing values and the observed data. In other words, the probability of a value being missing is the same for all observations, regardless of their values.
- Missing at Random (MAR): When data is MAR, the missingness is not random, but other observed variables can explain it. In other words, the probability of a missing value depends on the observed data, not the missing data itself.
- Missing Not at Random (MNAR): When data is MNAR, the missingness is not random and cannot be explained by other observed variables. In other words, the probability of a value being missing depends on the missing data, which can lead to biased or incorrect results if not handled properly.
Methods for Dealing with Missing Values in Dataset
Let’s have a dummy dataset in which there are three independent features(predictors) and one dependent feature(response).
| Feature-1 | Feature-2 | Feature-3 | Output |
| Male | 23 | 24 | Yes |
| – – – – | 24 | 25 | No |
| Female | 25 | 26 | Yes |
| Male | 26 | 27 | Yes |
Here, We have a missing value in row-2 for Feature-1.
The popular methods which are used by the machine learning community to handle the missing value for categorical variables in the dataset are as follows:
Step 1: Delete the Observations
If there is a large number of observations in the dataset, where all the classes to be predicted are sufficiently represented in the training data, then try deleting the missing value observations, which would not bring significant change in your feed to your model.
For Example,1, Implement this method in a given dataset, we can delete the entire row which contains missing values(delete row-2).
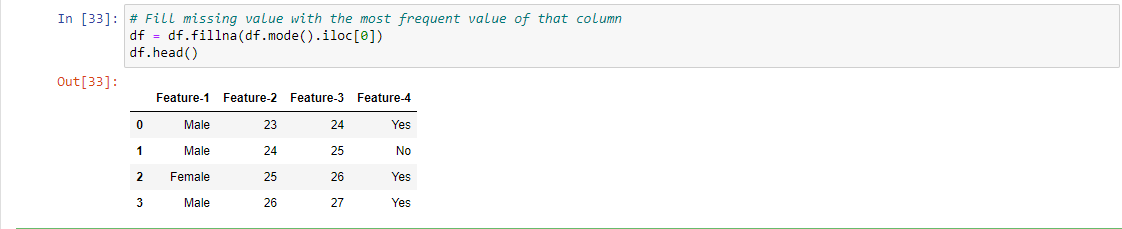
Step 2: Replace Missing Values with the Most Frequent Value
You can always impute them based on Mode in the case of categorical variables, just make sure you don’t have highly skewed class distributions.
NOTE: But in some cases, this strategy can make the data imbalanced wrt classes if there are a huge number of missing values present in our dataset.
– Generally, replacing the missing values with the mean/median/mode is a crude way of treating missing values. Depending on the context, like if the variation is low or if the variable has low leverage over the response, such a rough approximation is acceptable and could give satisfactory results. In this case, since you are saying it is a categorical variable — this step may not be applicable.
For Example, 1, To implement this method, we replace the missing value by the most frequent value for that particular column, here we replace the missing value by Male since the count of Male is more than Female (Male=2 and Female=1).
Step 3: Develop a Model to Predict Missing Values
One smart way of doing this could be training a classifier over your columns with missing values as a dependent variable against other features of your data set and trying to impute based on the newly trained classifier.
Algorithms for Missing Values of Categorical Variables
- Divide the data into two parts. One part will have the present values of the column including the original output column, the other part will have the rows with the missing values.
- Divide the 1st part (present values) into cross-validation set for model selection.
- Train your models and test their metrics against the cross-validated data. You can also perform a grid search or randomized search for the best results.
- Finally, with the model, predict the unknown values which are missing in our problem.
NOTE: Since you are trying to impute missing values, things will be nicer this way as they are not biased and you get the best predictions out of the best model.
For Example, 1, To implement the given strategy, firstly we will consider Feature-2, Feature-3, and Output column for our new classifier means these 3 columns are used as independent features for our new classifier and the Feature-1 considered as a target outcome and note that here we consider only non-missing rows as our train data and observations which is having missing value will become our test data. We have to do the prediction using our model on the test data and after predictions, we have the dataset which is having no missing value.
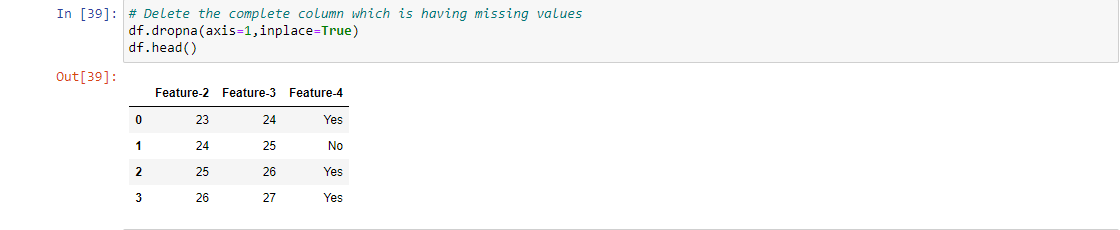
Step 4: Deleting the variable
If there are an exceptionally larger set of missing values, try excluding the variable itself for further modeling, but you need to make sure that it is not much significant for predicting the target variable i.e, Correlation between dropped variable and target variable is very low or redundant.
For Example, 1, To implement this strategy to handle the missing values, we have to drop the complete column which contains missing values, so for a given dataset we drop the Feature-1 completely and we use only left features to predict our target variable.
Step 5: Apply unsupervised Machine learning techniques
In this approach, we use unsupervised techniques like K-Means, Hierarchical clustering, etc. The idea is that you can skip those columns which are having missing values and consider all other columns except the target column and try to create as many clusters as no of independent features(after drop missing value columns), finally find the category in which the missing row falls.
For Example, 1, To implement this strategy, we drop the Feature-1 column and then use Feature-2 and Feature-3 as our features for the new classifier and then finally after cluster formation, try to observe in which cluster the missing record is falling in and we are ready with our final dataset for further analysis.
Implementation in Python
Import necessary dependencies.

Load and Read the Dataset.

Find the number of missing values per column.

Apply Strategy-1(Delete the missing observations).

Apply Strategy-2(Replace missing values with the most frequent value).
Apply Strategy-3(Delete the variable which is having missing values).
Apply Strategy-4(Develop a model to predict missing values).
For this strategy, we firstly encoded our Independent Categorical Columns using “One Hot Encoder” and Dependent Categorical Columns using “Label Encoder”.
– Read and Load the Encoded Dataset.
– Make missing records as our Testing data.
– Make non-missing records as our Training data.
– Separate Dependent and Independent variables.

– Fit our Logistic Regression model.

– Predict the class for missing records.
# Predict the class for a missing record
input = [[24, 25, 0]]
ln.predict(input)output :
array([1.])
This completes our implementation part!
End Notes
Missing values in a dataset can be a challenge in data analysis and lead to biased or incorrect results if not handled appropriately. Therefore, it is essential to identify the type of missing data and use appropriate techniques to handle them, such as imputation or exclusion.
If you want to learn more about handling missing data and other advanced data analysis techniques, consider enrolling in our Blackbelt program. You will gain in-depth knowledge of data analysis techniques, data visualization, machine learning, and statistical modeling, equipping you with the skills needed to become a data-driven professional in today’s data-intensive world.
Frequently Asked Questions
Q1. What is a good way to fill in missing values in a dataset?
A. A good way to fill in missing values in a dataset is using imputation techniques such as mean, median, mode, interpolation, or hot-deck imputation. The chosen method should depend on the dataset’s nature and the missing values’ extent.
Q2. What is a missing value in a database called?
A. In a database, a missing value is called a null value or null. It represents the absence of data for a particular observation or variable and can be caused by various factors such as data entry errors or missing information.
Q3. How do you handle missing values in a data frame?
A. To handle missing values in a data frame, one can either remove the rows or columns that contain missing values or fill in the missing values using imputation techniques such as mean or median imputation, interpolation, or hot-deck imputation. The chosen approach depends on the analysis type and the missing data extent.
I am a B.Tech. student (Computer Science major) currently in the pre-final year of my undergrad. My interest lies in the field of Data Science and Machine Learning. I have been pursuing this interest and am eager to work more in these directions. I feel proud to share that I am one of the best students in my class who has a desire to learn many new things in my field.






The analysis/recommendations does not account for the following: 1. Missing Mechanism (MCAR/MAR/ NMAR), 2. Supervised / Unsupervised technique, 3. Importance of understanding business/domain prior to imputing 4. There is no information on how any missing value treatment method can do to the model - like add bias, artificially strengthen relationships, etc. I think the author should do more research on this topic. Thanks, Anand