This article was published as a part of the Data Science Blogathon.
1. Introduction
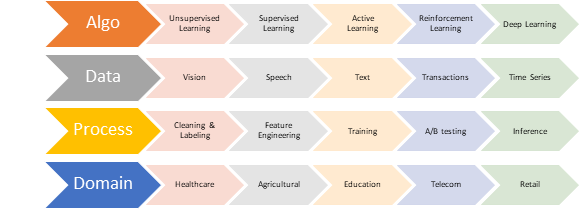
We generally see data science from different perspectives like algorithms, data, process, or domain as shown below in Fig 1.
In this article, we will see data science from an architecture building blocks perspective especially in the context of complex ecosystems. What layers are needed in an end-to-end AI stack for complex ecosystems? These complex ecosystems will be product 3.0 as described in Table 1.

What makes these ecosystems complex?
- Billions of entities: customers, people, devices, sensors, assets, facilities, content, etc.
- Trillions of interactions: sensor, transactions, services, applications, content social network etc.
- Hundreds of inter-dependent metrics: customer, operational, process, business and environmental, societal metrics
- Millions of real-time decisions everyday: pricing, sales & marketing, scheduling, supply-chain, operational controls etc.
- Hundreds of workflows: efficiency workflows, expansion workflows, exception workflow
- In this article, we will see how AI participates in building such complex ecosystems intelligent.
2. AI Stack
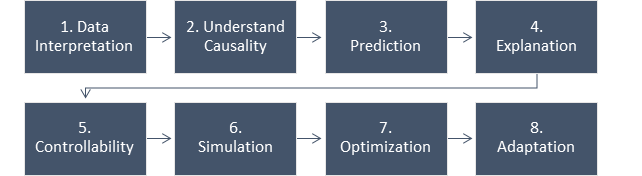
We can imagine AI stack in 8 different layers which start with data interpretation and end with Adaptation (As shown in Fig 2). Each layer serves as a pre-requisite to move to the other layers. Also to note that the machine needs data in digitized format, if in case, data is not present in digital format, then the enterprise should look at that as a pre-requisite. For e.g. Electronic Health Records (HER) – medical records lying in physical paper format get digitized to be consumed by machines for interpretation at scale. Let’s look into each of these layers in detail and understand the full AI stack.
2.0 Digitization
Today, we live in a world of digital-physical data. So, we have physical data like a printed textbook, exam, bubble sheets, QR code, SKU, receipt, etc. These data are getting digitized easily and making them searchable. Companies are shifting from physical-first to digital-first. Now companies keep physical copy only for archival reasons.

2.1 Data Interpretation
The data interpretation layer helps us in interpreting the raw data like images, text, audios, social media profiles, internet pages, genes profile, etc. A lot of AI is focused on interpretation today.
It’s the largest layer in today’s AI stack. It assigns high-level semantics to low-level data. If we are doing Speech2Text, Face2Emotion, Video2Action, or XRay2Anomaly, these all are interpretation layer where we are interpreting the raw data like speech, face, or video and converting them to higher-level semantics. Now there are a lot of machine learning models that are built to take care of this.
When a human system listens to the speech, it just not recognize one thing, it recognizes the speaker, gender, emotion, what the speaker is saying, and that too everything simultaneously. The beauty of the human system is that it can do multiple interpretations from one single input. This is how fanning out of an interpretation layer happens.
However, currently, machines are built to do invariance learning. They are built to master one objective given multiple inputs. For e.g. in an object detection problem, given an image, the machine will not care about the scale, color, illumination, pose, etc. but it will try to find out objects like a car, shirt, dog, etc for which it is tasked.
Examples of interpretation layers in humans and machines are listed in Table 2.

Table 2: Interpretation layers in humans and examples of interpretation layers in the machines
A large class of AI machine learning is used primarily in the interpretation layer. This is one of the most crucial layers in the overall AI stack. Let’s move to the next layer that is the causality layer.
2.2 Understand Causality
Before we start preparing the prediction models, it is important to understand the cause and effect relationship between variables. If we have n things in the system then it is important to understand “what causes what?” and “what is caused by what?”. At this stage, data scientists and domain experts work together to understand the interactions, causality, and correlations. Think of this as a layer of feature engineering where we decide what goes in and what comes out for each model.
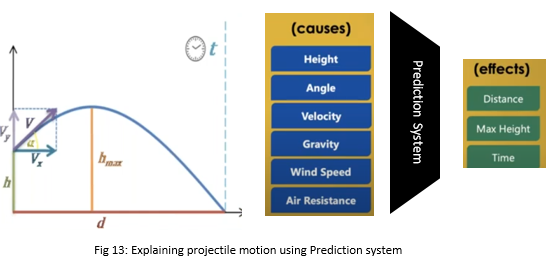
Let us understand it with an example from science. When we throw an object from height (h) and velocity (v) then we want to know how much distance (d) it will cover, for how much time it will remain in the air (t), and what is the maximum height it will attain (hmax)? Now physics will first try to understand what can be measured and the cause and effect relationship amongst them.
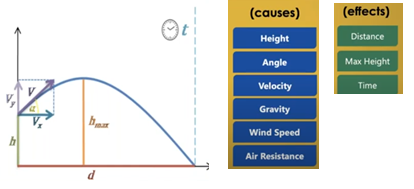
Fig 3: Projectile motion of a throw
Similarly, before we put a model into practice, we need to think about these casualties. For e.g. things like height, velocity, angle, gravity, wind speed, air resistance can affect the outcome of distance, max height, and time. This way we can break down any complex system into causality. There is various type of casualties that drives how we can build the complex system.
2.2.1 Non-causality
Not everything has a cause. Sometimes things are what they are. This is called non-causality. We can just measure it but there is no cause to it. Examples of such non-causality can be seen in fig 4.
2.2.2 Multi-factor causality
Here we talk to domain experts and understand all types of causes for something we take as output. For e.g.
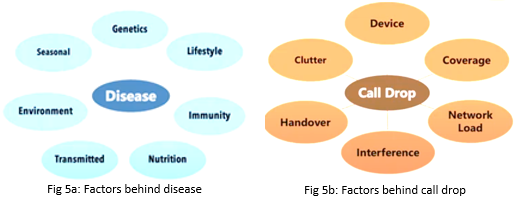
| Example 1: If we look at the disease of a person and build a very comprehensive system that can work as a doctor then we have to look around a person’s genetics, lifestyle, immunity, nutrition intake, etc. as shown in fig 5a. | Example 2: If we talk about call drop in a mobile network then there can be various factors like device type, network load, clutter, etc. as shown in fig 5b. |
2.2.3 Cumulative causality
Another kind of causality is cumulative causality. Essentially it is shown in supply-demand, for e.g. total Uber fleet required in a location today, the total number of products required in a store, total capacity required in a telecom network, etc. Here, each factor as shown in Fig 6a will affect the demand cumulatively.
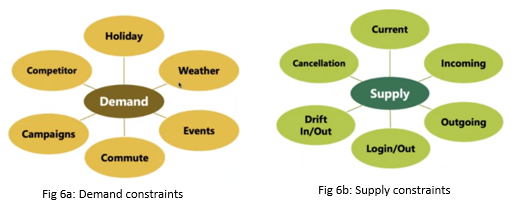
Similarly, if we have to measure supply, for e.g. to estimate the supply of Uber fleet at a location, we need to know how many cabs are currently there, how many cabs are going to reach there in the next 15 mins, how many go out in the next 15 mins, how many drivers login or logout, etc. as shown in fig 6b.
So, in cumulative causation, many factors accumulate together to define the final output.
2.2.4 Dependence based causality
Imagine, you have 2 students. Student A and student B have different levels of proficiency in concepts P, Q, and R. Then their study mix prediction will also be different. This prediction is dependent on the domain knowledge that we have like what concepts are required before learning another concept, what are the prerequisites and how much do they really matter?
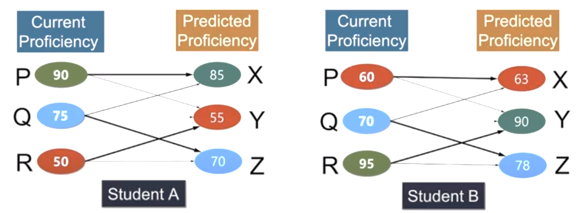
In this scenario, if we have to create a personalized curriculum for each student. Then for student A, we can suggest that he should learn either X or R and student B should learn either Y or P.
2.2.5 Temporal causality
It depends upon what happens in the past leads to what happens in the future. For e.g.

2.2.6 Structural causality
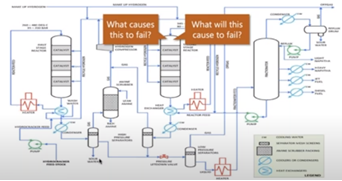
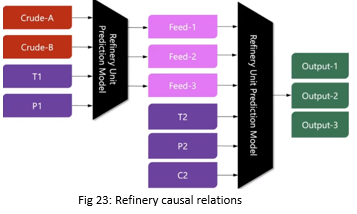
In a complex system like a refinery, there are complex interactions between all the units, the input of one unit is becoming the output of the other. Now, if a particular unit say “Unit 1” is faulty, or not working properly, or about to break down, we can tell 2 things –
- 1. Unit 1 is going to cause something else to breakdown in upstream, or
- 2. Why Unit 1 is having breakdown from down stream
2.2.7 Deep causality
Deep causal structures amongst metrics and actions drive the AI architecture. Let’s take the example of Uber where
- Incentives and offers to drivers and organic supply and demand determine overall supply and demand.
- Given supply and demand, we can measure the availability of cabs, stock out of cabs, pricing, and utilization at different locations.
- This set of variables will cause the next set of variables like whether the customer gets the cab, was he converted or not, how was the customer experience ETA and cab quality, and how efficiently we are running the system?
- These things will further affect customer engagement, ARPU, churn, revenue, and the cost of running the system.
- And lastly, it will impact market share and profitability.
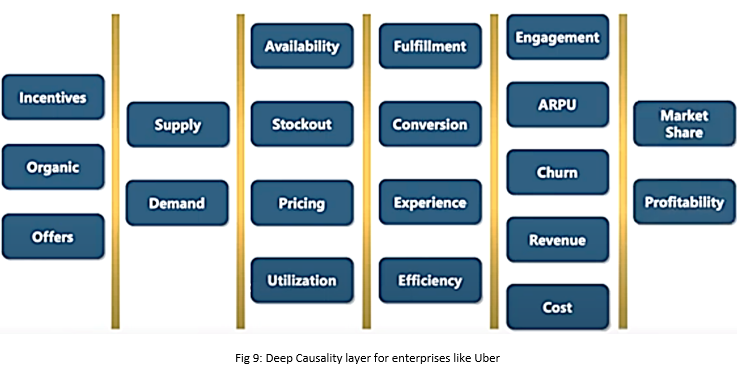
For complex systems or enterprises, we need to draw such deep causality graphs before we build the AI architecture of the business.
2.3 Prediction
Once we understand causality then it’s time to manifest causality into a prediction model. We formulate features into a machine learning problem to predict the outcome.
Let’s take the same science problem where we know the inputs that will cause certain outputs.
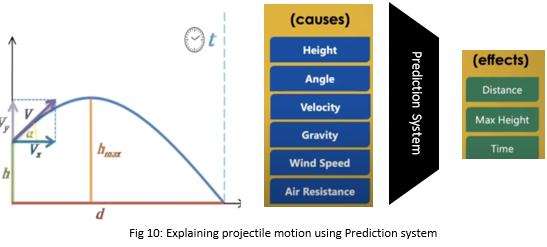
For a physicist, this is a physics problem who will write an equation and gives the answer. However, for a data scientist, it’s a data problem where he will be having inputs and their associated output using which he will develop a prediction model.
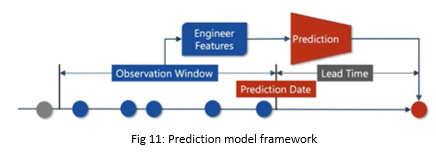
The prediction model is about predicting the future output given the inputs. We look at the observation window, engineer feature, and then predict an event in the future. These predictions can be of different types and depending upon the nature of prediction, prediction models are different. There are multiple classes of prediction models.
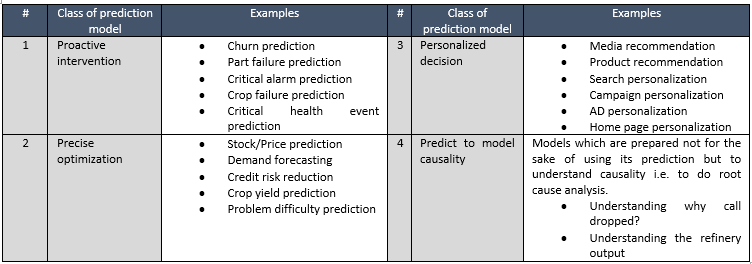
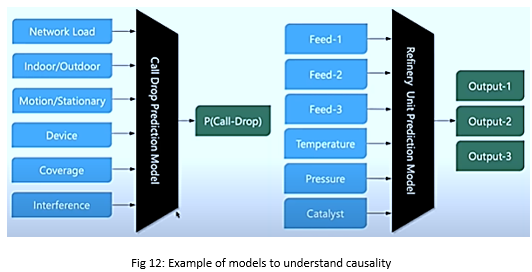
2.4 Explanation
The prediction will provide the score but the user also wants to know the reason for such a score. Understanding why the system made that prediction is the capability this layer will bring in.
For example, in our science example, let’s say we know the distance, max height, and time, now can you explain why it happened? Prediction systems have few features that cannot be changed like gravity, wind speed, and air resistance but other features like height, angle and velocity will be used by this layer to explain the distance, max-height, and time.
Now the explanation layer works at 2 level –
- Can I explain the overall cause and effect relationship (overall SHAP values)?
- Can I do it for a single data? For e.g. for customer A, the reason for call drop can be Network Load and Device, however, for customer B, it can be Coverage.
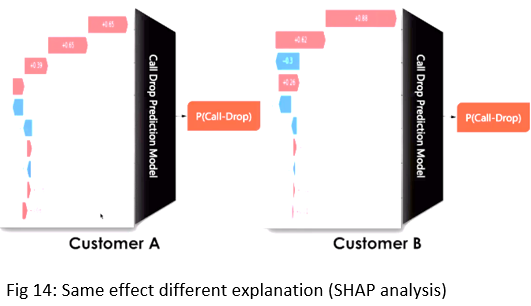
The idea is that knowing the cause of the problem at the individual customer level will help in taking the right action by resolving the root problem. This is done using SHAP analysis.
2.5 Controllability
By now we have the relationship between inputs and output. Now we have to divide our inputs into 2 parts –
- Controllable – set of features that we can control
- Observable – set of features which we cannot control but just can observe.
In our science example (fig. 13), we have height, angle, and velocity as controllable features, and, gravity, wind speed, and air resistance as observables.
Traditionally, we have inputs using which model predict output and SHAP provides the explanation. However, when we bring controllability inputs will be divide into 2 parts as shown in fig 15.
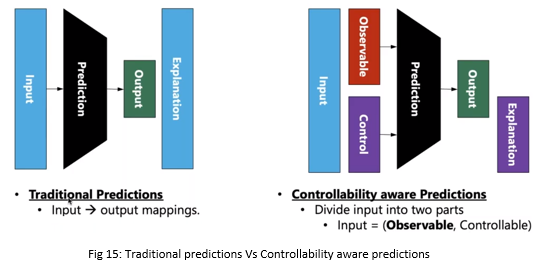
In this framework, we need not explain the output with respect to all input variables, but, with respect to controllable input variables. For e.g. in healthcare, if we know something is happening due to my lifestyle and genomics, I can just control my lifestyle.
2.5.1 Cascaded controllability
In complex systems, we see cascaded controllability. For example,
| Example 1: In refineries, that are not a single unit system, for e.g. in fig 16, we have 2 units where the output of 1st unit is fed into 2nd unit. Each unit has its controllable parameters but in addition, controllable parameters of the 1st unit are indirect controllable parameters for the 2nd unit. So, this level of causality and controllability across different units needs to be explained. | Example 2: In telecom (fig 17), call drop happens. Here we cannot control the network load, the customer is inside or outside, the customer is moving or stationary but we can control the upgrade on the device, coverage, and interference of the network. However, coverage and interference are further dependent on the previous model where we have different controllable features. Hence, end to end causality thinking will help us build such models. |
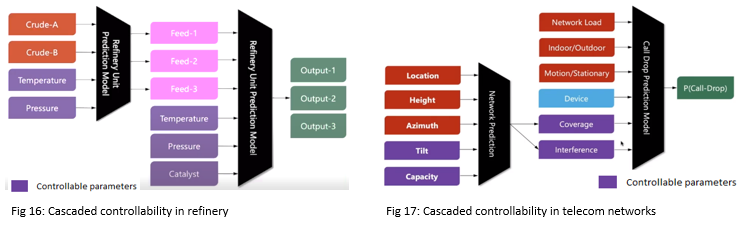
2.5.2 Deep controllability
Let’s add one more layer of complexity. In telecom networks, if we look to optimize churn metrics, then we see customer behavior and their usage can only be observable whereas call-drops, call quality, and throughput can be controlled. However, call-drops are dependent on another set of features of the high device, coverage, and interference can be controlled. Further, to control network coverage and interference, we need to understand what the tilt and capacity should be.
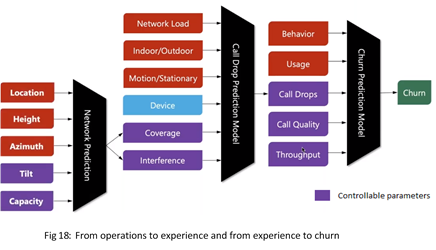
So, think of this causal diagram as a key element of architectural thinking in AI. All these pieces of controllability, observability, and causality are going to play a role in creating such an architecture.
2.6 Simulation
Now after knowing the controllability, we do a lot of what-if analysis to understand if we change feature 1 then how it will affect other things in the system. This is a very important layer in the AI stack especially when we are dealing with complex systems. A strong simulation layer makes it easy to understand the interactions between features in the system and the impact of change of feature on metrics.
This layer will help us understand the effect of changing the control variables on the output. For e.g. in our science example (fig 13), what happens to max height if, for a certain height and velocity as constant, we change the angle?
Similarly, in our refinery example (fig 12), what will happen to Output 3 if feed-2 increased by 2%, temperature drops by 5%, and pressure increased by 1%? Since we have the accurate predictive mode we can tell how the output will change.
2.6.1 Deep simulation
Like we have deep learning and deep causality where we have multiple layers, we can also do deep simulations for complex system architectures. For example,
| Example 1: In refineries (fig 20), if we have to simulate what happens to output 2 where T1 is increased by 5% and P2 is decreased by 5 psi, then we can do end to end simulation. | Example 2: In telecom (fig 21), what will happen to call drop in an area if we decrease the tilt of the cell by 1 degree at this network load for such a customer (indoor, stationary) |
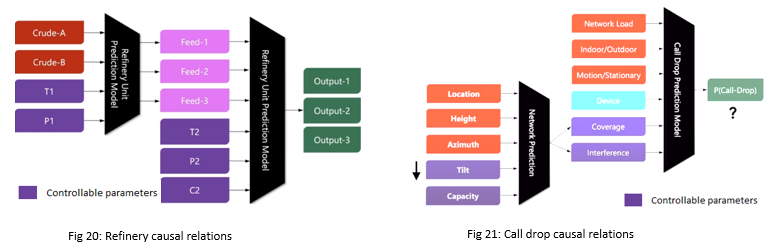
Similarly, to reduce churn, telecom companies can run deep simulations to know in which area the capacity should be increased. To increase profitability for Uber, deep simulations can help optimizing the number of cabs in a location.
2.7 Optimization
Post simulation we understand the impact on metrics due to change in feature space. Now, we can perform optimization on the controllable features to get our desired metric. This layer helps us answering questions like maximizing the utilization or minimize the call drop.
2.7.1 Simple Optimization
Now we have an objective function and instead of thinking of simulation we can go and use the simulation as a function call to do the optimization. For e.g. in our refinery example here we can answer at what temperature, pressure, and catalyst mix should we run the unit to produce, x% of output 1, y% of output 2, and z% of output 3.
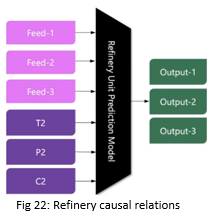
So, now this is a reverse problem, where we know the desired output and the observable features and we want to know the optimized values of controllable feature to get the desired output.
2.7.2 Deep Optimization
In deep optimization, we can run the entire refinery optimization end to end. Now we can control all controllable features of the entire refinery, keeping the crude mix fix on one side and look at the output on the other side and then maximize the profitability by taking the cost into consideration.
Similarly in telecom, to maximize the customer’s experience across the city, where should we add capacity and where should we change tilt can be obtained using deep optimization.
2.8 Adaptation
Finally, this layer is used when relations between observable inputs and output change, and we need to re-optimize and adapt to the changing environment. For e.g. in our science problem (fig 13), if we have to run the same problem at mars or the moon then gravitational force changes, and hence we need to re-optimize the system and adopt the change.
Similarly, in a refinery, if a new type of crude shipment comes into the refinery then we need to re-optimize the entire refinery again.
————————————————————————————————————————–
I will like to thanks Dr. Shailesh Kumar for sharing his thoughts at ODSC-2020 conference and put up this amazing AI stack. This article is inspired from this talk.
Credit: Dr. Shailesh Kumar, ODSC India, Dec’2020 – https://www.youtube.com/watch?v=AB-x0Hjin5o





