This article was published as a part of the Data Science Blogathon.
Creating a machine learning model is a wholesome process involving data collection, manipulation, feature extraction, making sense of the data, or coming up with a predictive/classification model out of the data available. The model created is of no use until it cannot be used by some third-party person for testing or genuine use case.
Integration of machine learning models into an application can be a separate task and may require a different set of software development skills but what if you want to present your findings as soon as possible without any extra effort? What if I tell you that you can create a web-based GUI app with minimal code and it can be deployed to any cloud platform like Heroku like a breeze! That’s where PyWebIO comes to the rescue.

In this article, I will discuss the basics of this library, various options available for input-output, how you can convert a normal Python script to a web-based interface, and finally, how to include machine learning models and deployed it on Heroku.
Introduction to PyWebIO
It is a library that facilitates the frontend implementation for any Python-based script. The best part about its implementation is that the function calls are similar to what you are currently using. Let’s install it first (via pip):
pip install pywebio
Consider a situation:
Suppose you want to create a salary predictor that predicts what will be your expected salary based on some of the initial factors. We will build the machine learning model for this later on but for understanding how this library works, consider that the salary is dependent only on age and the years of experience in the industry.
Therefore let’s set these rules for now (these are hypothetical rules without any valid proof):
| Age | Years of Experience | Expected Salary |
| 16 to 20 | less than 1 | 10000 |
| 21 to 26 | 2 to 5 | 40000 |
| Above 27 | 5 + | 90000 |
The script for these rules would look like this: (without PyWebIO)
.png)
And the terminal output would look like this:

Isn’t this boring? Let’s use PyWebIO for inputs and outputs. (All the codes mentioned in this article are available at my GitHub Repo)
Writing the very first script
We need to import the input function from pywebio.input. Also, we can specify the type of input such as FLOAT, NUMBER, TEXT, PASSWORD, URL, DATE, and TIME. This creates an automatic type checker and doesn’t allow any values other than the specified data type!
We use the print function to get output on the terminal. Here, we will use the put_text function to display results on the webpage. These are the only modifications needed! The new script would look like this:
.png)
When you will run this script, a webpage will open with an input area!
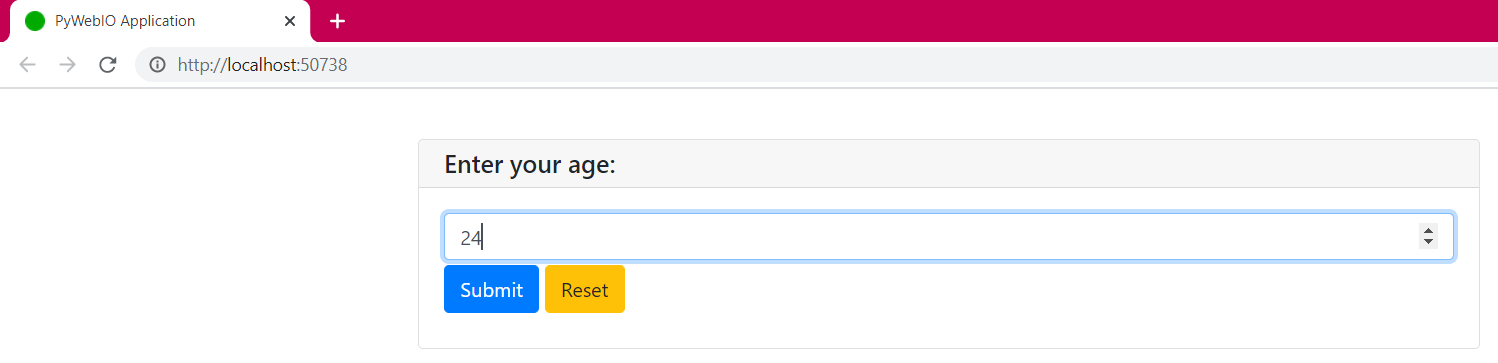
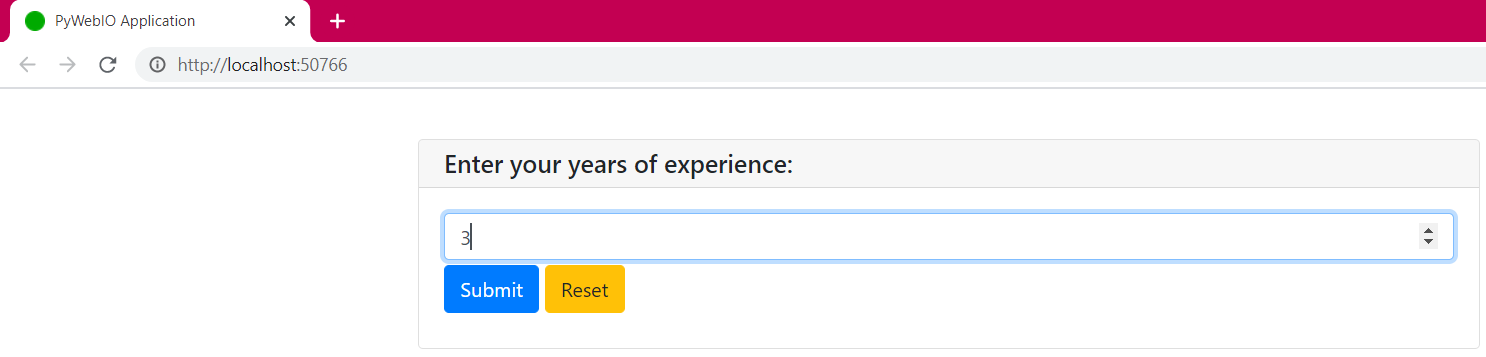
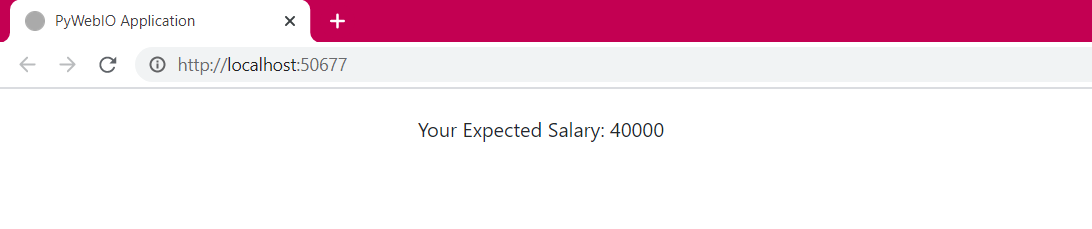
The web interface with buttons and a box area is created automatically for us. One thing you must have noticed is that the inputs are not on the same page. Only one input is available at a time and it can be time-consuming to click submit every time for each input. Let’s group these inputs on one page.
Grouping different inputs on one page
To get all the input boxes on one page, we need to use input_groups. This function takes the title for the whole input box and the list of inputs to be included. Now one question you must have is that how I will identify and access these inputs? You need to pass a name parameter for every input in the list.
An important note: PyWebIO works in the way that if the name parameter is present in the input function, then it will be included in the input_group else standalone input. Make sure that you define the name parameter only input_group function and not in standalone input.
The input_group returns a dictionary object which can be easily accessed via keys (name in this case). Let’s apply this to our old script:
.png)
The result for this is:
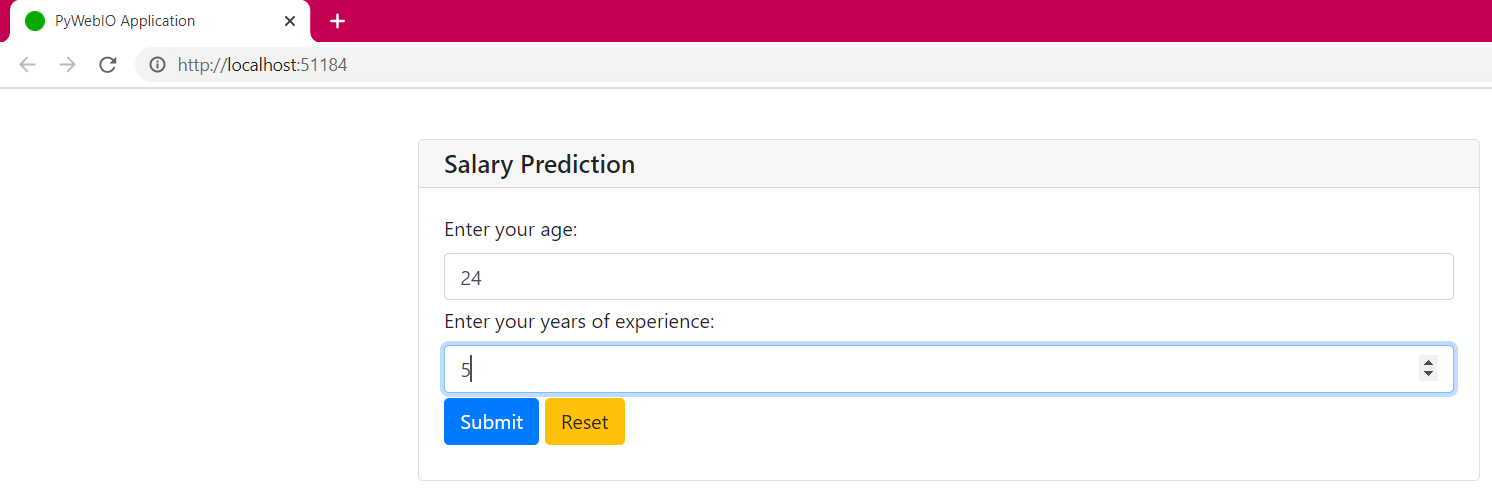
Now all the inputs are visible on one page and providing all of them here will give the result at one go! But as we are building a machine learning model, we also provide labels or categorical data to the model (in encoded form).
The best way to get these types of categories is via dropdown menus as one can make silly mistakes while writing them via text area. Let’s discover some of the available input options in this library.
Various types of Input
(One program for all types of inputs implementation at the end)
1. textarea: As the name suggests, this function is used to get a long text from a user. This can be any paragraph or multiline string input. This can be useful for cases where you need to do text analysis/prediction.
2. select: This function presents the user with a list of options. One can implement this for categorical values as the function defines the labels and the associated value. That means you can have a label of a Software engineer as 2. This way, it will be easy for us to pass the values to the model.
3. checkbox: Checkboxes help in selecting/deselecting values. This can be useful in the case of getting feedbacks as if when you have predicted the topics for a textual paragraph and you present the user with the predicted topics as checkboxes. Now as per the user inputs, you can retrain your model and backpropagate the changes.
4. radio: Radio buttons are useful for getting one definite answer from the user. These can be yes-no questions, gender selection, or any binary type answers. It will be useful in any machine learning model inputs
There are more inputs available in this library but these are the most useful for our use-cases. Let’s implement them in an input_group and present their return values on the web only:
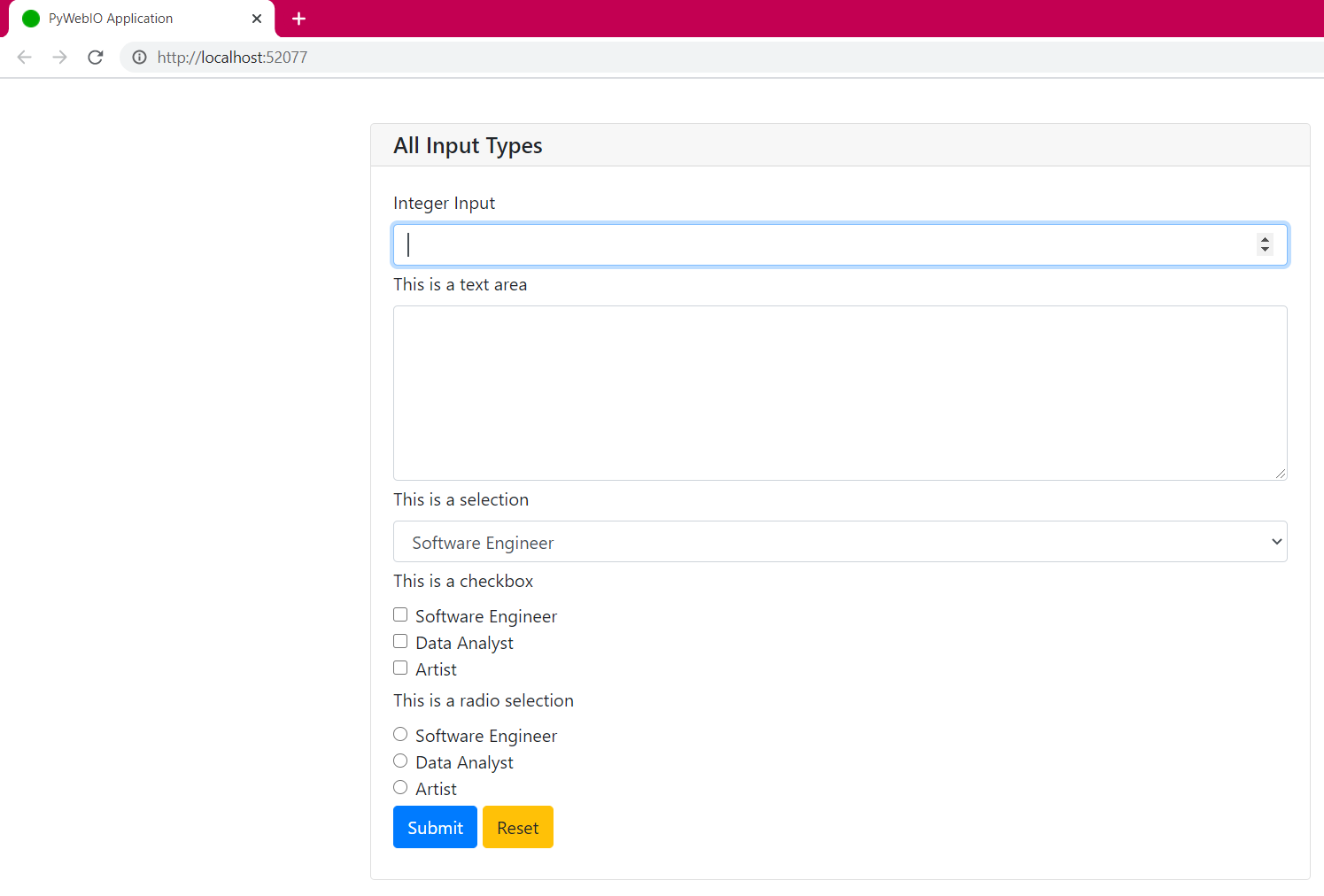
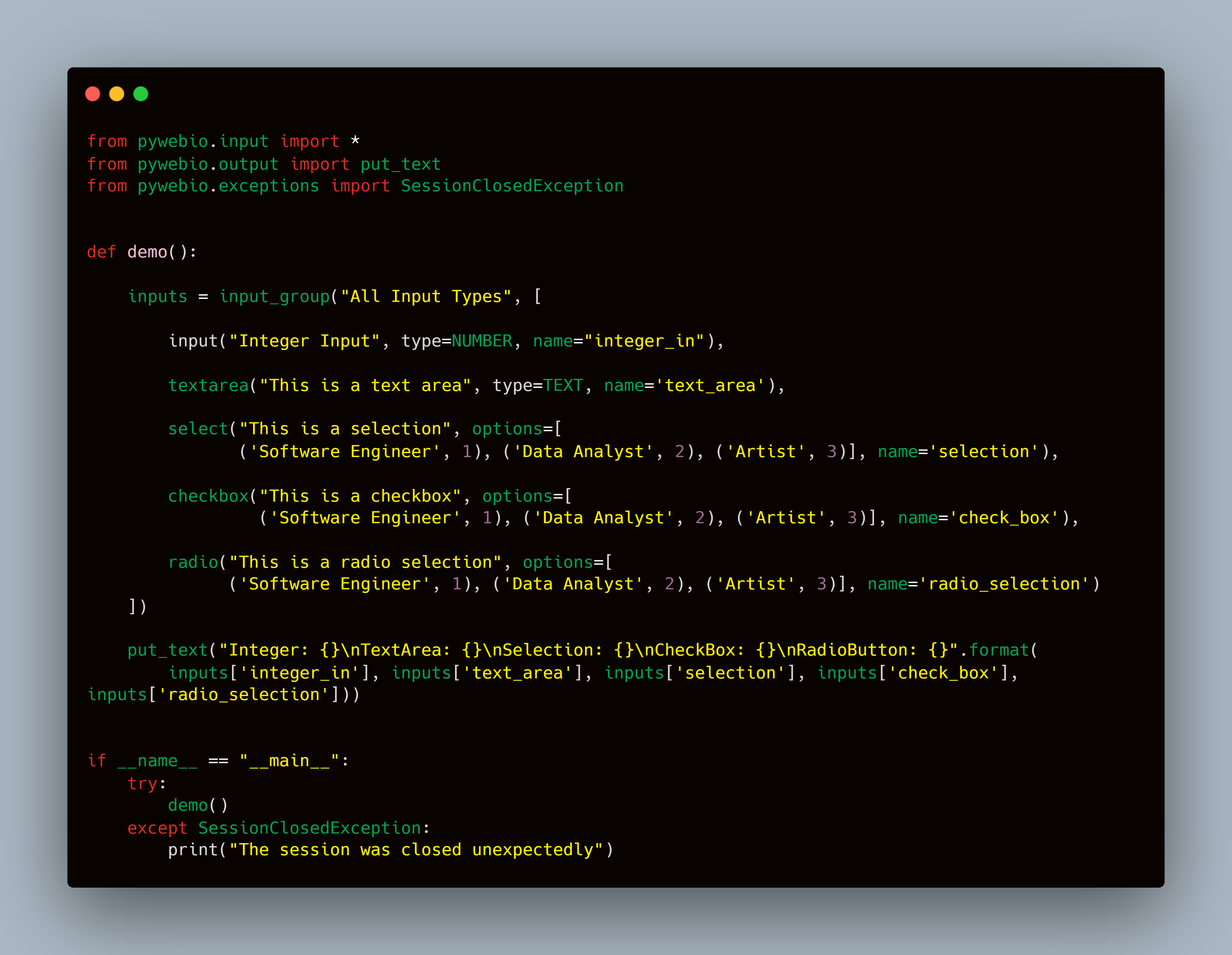
The code for this is pretty simple:
Preparing Code for Model
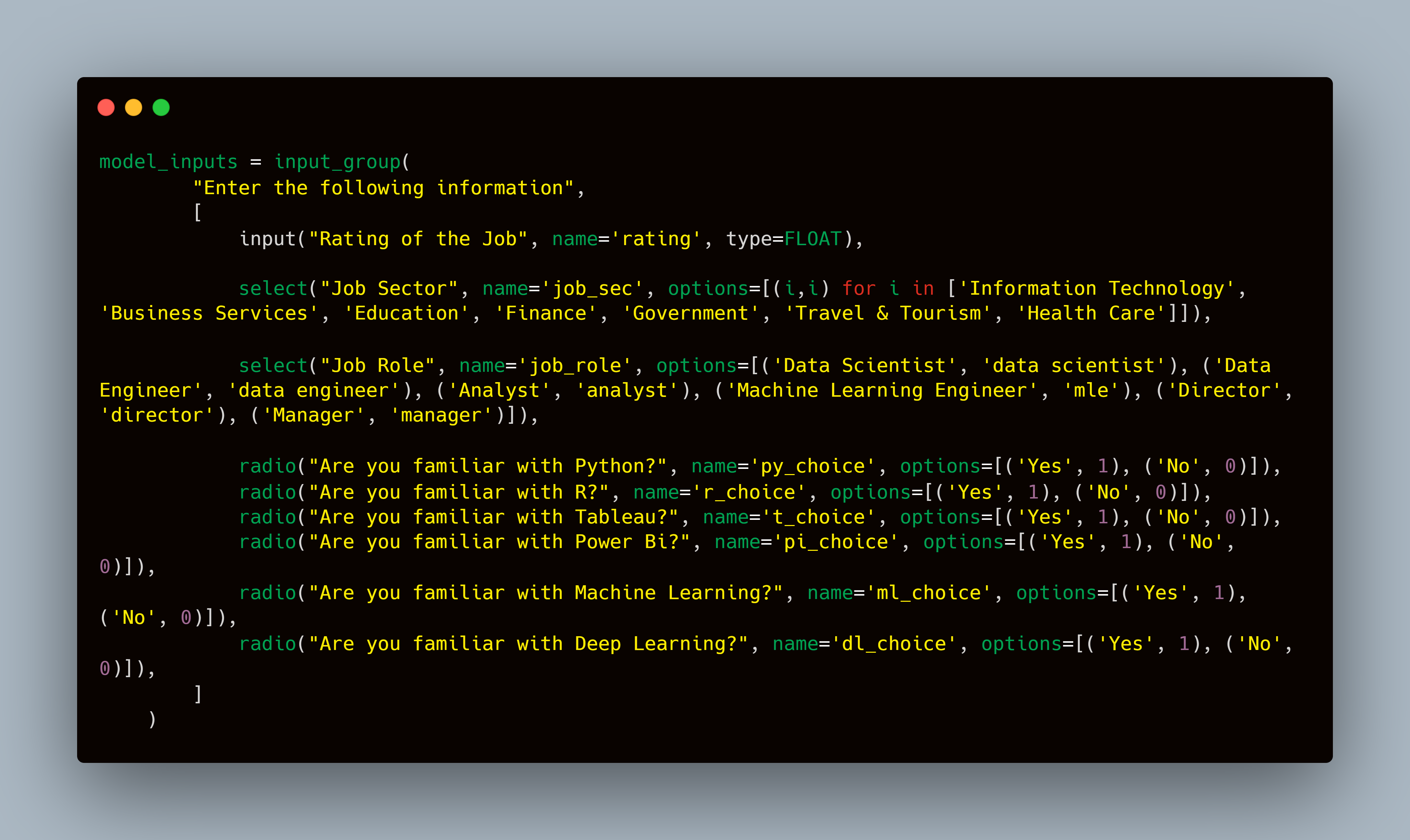
Now we will create the code for the machine learning model which I mentioned at the start of the article. The dataset contains columns for the current sector of employment, job role, some yes/no questions about the tech stack you have experience with, rating of the job, and some other columns. Do note that I have taken inspiration from an already available model on GitHub and then retrained the model with my customizations. These will be inputs for the model:
- Rating
- Job Sector
- Job post
- Familiarity with Python, R, Tableau, Power BI, Machine learning, and Deep learning
Rating is float type, therefore normal input will be used. For Job sector and Job post, as they are categorical values, they need to be selected from a range of choices. In the dataset, there are ample of them and I have picked a few of them for this example. Familiarity with tech stack is a Yes/No choice and therefore, radio buttons. Here is what the input group would look like:
If you will integrate the model loading and prediction in your script, it would work fine there is still one error. In all the examples, the webpage becomes inactive as soon as the output is presented. Currently, it is working as a terminal script. To convert it to a reloading web app, we need a server. The PyWebIO comes with by default tornado server. Other backends which are available include Flask, FastAPI, Django, and aiohttp.
You can check out my this article where I discussed major differences in Flask and FastAPI. FastAPI: The Right Replacement for Flask
We will in-directly use tornado. To start the server, simply import the start_server function from the PyWebIO and pass the function to be executed. That’s it! The whole model prediction code is available in my GitHub repo.
I have used the function put_markdown for title and predictions. There are more output functions available such as put_html for HTML codes, put_link, put_image, and so on. The final output would look like this:
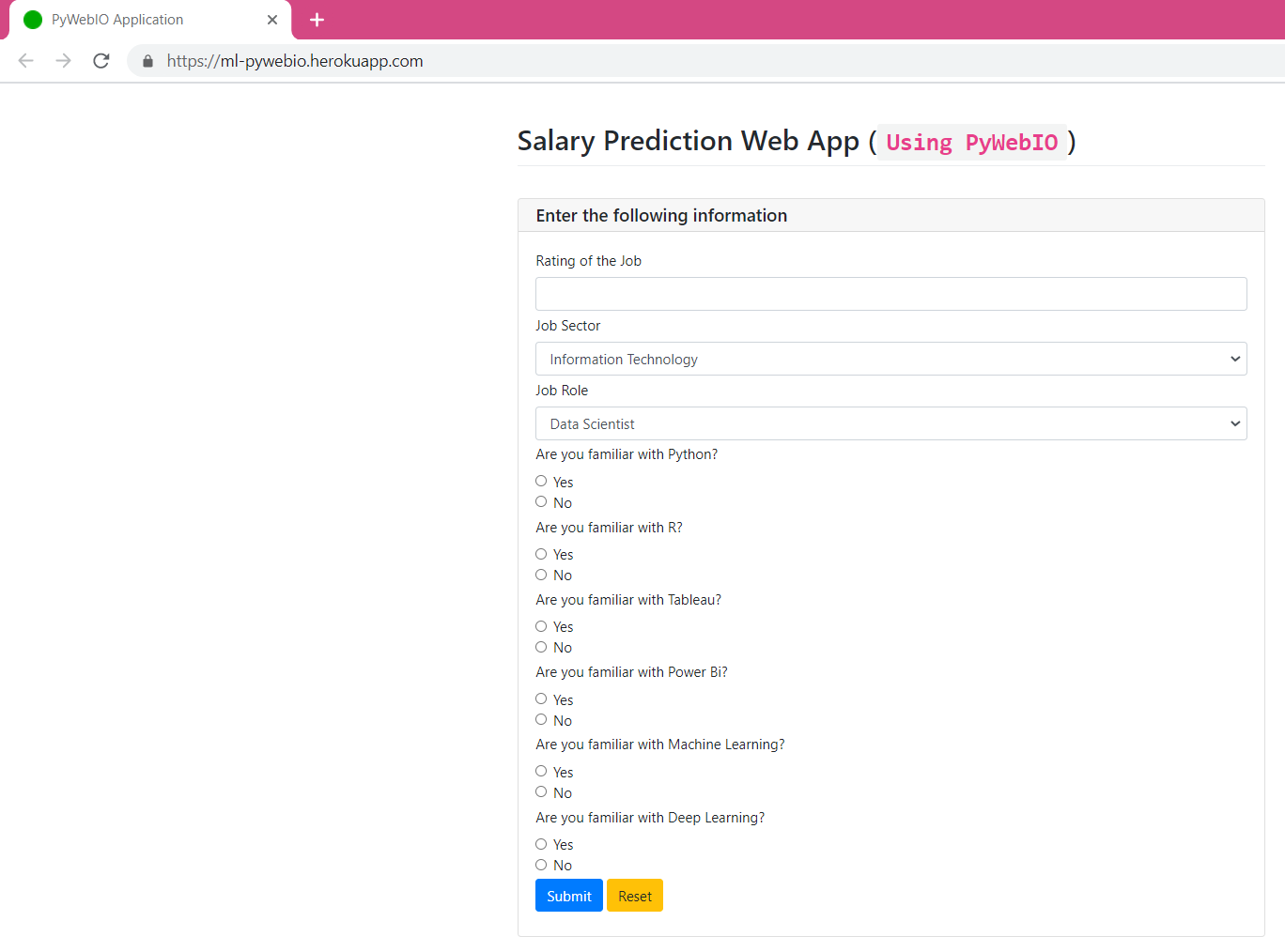
The current application is deployed at Heroku. You can test this application at this link.
Conclusion
In this detailed article, I discussed PyWebIO. I covered all the basic input-outputs, how to convert the basic script to this library code and how it connects to our use case in machine learning. I hope you liked this article. If you wish, you can connect with me on the following platforms:
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Kaustubh Gupta is a skilled engineer with a B.Tech in Information Technology from Maharaja Agrasen Institute of Technology. With experience as a CS Analyst and Analyst Intern at Prodigal Technologies, Kaustubh excels in Python, SQL, Libraries, and various engineering tools. He has developed core components of product intent engines, created gold tables in Databricks, and built internal tools and dashboards using Streamlit and Tableau. Recognized as India’s Top 5 Community Contributor 2023 by Analytics Vidhya, Kaustubh is also a prolific writer and mentor, contributing significantly to the tech community through speaking sessions and workshops.






Hi Kaustubh, this article was really helpful espcially to people where we want to build a lot of POC and want end user to test them before actually putting it in the software development cycle. Thanks again