This article was published as a part of the Data Science Blogathon.
Overview
- introduction
- reduce execution time
- dataset
- reading dataset
- handling categorical variables
- dependent and independent feature
- model training with CPU cores
- Endnote
Introduction
“The 65,536 processors were inside the Connection Machine”
~ Philip Emeagwali
We all are from a computer science background, we use a computer daily and we have a better understanding of what the computer is. Computers have a heart as humans have, it is called CPU.
We all have an understanding of the CPU if you don’t then, the CPU is the central processing unit in the computer, or it is electronic circuitry that executes the several instructions comprising a computer program. CPU performs basic arithmetic, logic, etc…

Previous generations of CPUs were implemented as discrete components and numerous small ICs on one or more circuit boards. Over the time CPUs are changed, they are updated. They are implemented on an integrated circuit, with one or more CPUs on a single IC chip. There are lots of functions or operations the computer performs so it takes lots of time, for that the scientist designed the multi-core processors, it was a combination of microprocessor chips with multiple CPUs.
Multi-core processors are very fast, they can do work within a time. As a data scientist we find that some of the python libraries are very slow and they are lengthy also, they slow down the execution of the program, it takes lots of time for the execution of our machine learning or deep learning models. If you want to see that how many cores are there in your computer have, then simply open your control panel and search system you will see that whole information about your computer.

If we talk about python panda’s library which is used in machine learning for data manipulation and data analysis, if we analyze a short amount of data it will not take as much time to perform operations but what if our dataset is large? obliviously it will take a lot of time to perform calculations on a large amount of data. So, this is a big problem, which every data scientist faced in their carrier. What if we reduce this time? is it beneficial for us?
let’s discussed below:
Reduce Execution Time
Above we have a brief discussion on CPU, so what does it mean? It means that we use cores of the central processing unit to train our machine learning model, There is one of the special parameters inside the machine learning algorithm which we are just normally using it but we don’t have knowledge about it or don’t know the exact meaning of that, this sounds amazing!
These CPU cores are very much important parts of training any machine learning model, this is also important when working with deep learning, because of these CPU cores parallel programming or parallel execution of the program will be possible. We cannot train machine learning models with the help of GPUs, So, CPUs are more helpful in this condition.
For faster machine learning training in any machine learning project, you can use these CPUs cores whenever you have a huge amount of data in the dataset for training the machine learning model.
Now, we see that how we train machine learning model using CPU cores to improve performance concerning training ML model:
Dataset
For training this particular problem statement we have to take the Wine_Quality dataset, the reference link of this dataset is here.
For a better understanding of this dataset you can refer to this link: click here
Point to remember that if you have to solve this particular problem with CPU cores, then you have to simple dataset with large size of data.
The reason behind using this dataset is that it is a simple dataset with a large size of data present inside this dataset.
let’ see what is the size of this data:
Reading Dataset
First of all, we have to read the wine quality dataset using pandas.
#importing pandas
df = pd.read_csv('wine_quality.csv')
df.head()

df.shape()

After executing this code you can see that we have 6497 rows and 13 columns in the wine quality dataset.
Now, we check the unique categories that are present inside a quality variable,
unique_points= df['quality'].unique() unique_points

As we see there are 6, 5, 7, 8, 4, 3, 9 unique data points in the quality variable, where these data points are the quality measures of the wine.
Handel Categorical Variables
# catogerical vars next_df = pd.get_dummies(new_df,drop_first=True) # display new dataframe next_df
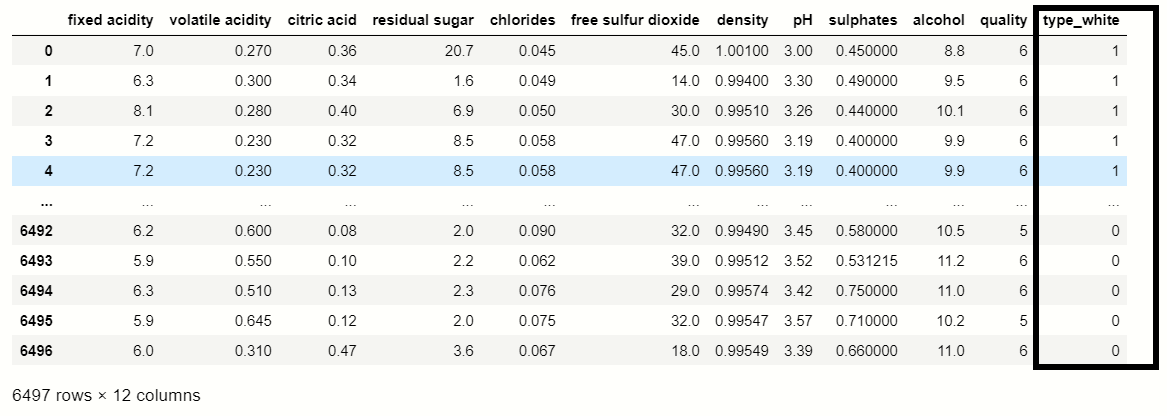
Dependent and Independent Feature
For applying the machine learning model we have to divide dependent and independent features:
# independent features x= next_df.drop(['quality','best quality'],axis=1) # dependent feature y= next_df['best quality']
Model Training with CPU Cores
Coming to the execution now, we are doing this by applying some steps:
Step 1: Using machine learning algorithm RandomForestClassifier.
Step 2: Using RepeatedStratifiedKFold for cross-validation.
Step 3: Train model using cross-validation score.
When we initialize all these things then the time will be calculated based on this cross-validation score. Before checking time we import the required modules:
Importing Modules:
from time import time # importing RepeatedStratifiedKFold from sklearn.model_selection import RepeatedStratifiedKFold from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score # importing RandomForestClassifier
Now, we check the time using the different CPU cores:
Here we use the machine learning algorithm RandomForestClassifie, when you check the parameters of RandomForestClassifier then, you find that there is a n_jobs parameter.

n_jobs is the parameter that will actually help you to basically assign how many cores should particular training takes from the system.
For example, if we want to take n_jobs = 1 then it will take 1 core of the CPU, if you take 2 then it will take 2 cores of the CPU, and soo on. When you want to use all the cores of the CPU for training and don’t know how many cores are there in the system, then simply use n_jobs = -1.
1 CPU Cores:
## CPU cores we use n_jobs
random = RandomForestClassifier(n_estimators=100)
# creating object of RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=4)
# starting execution time
start_time=time()
n_scores =cross_val_score(random,x,y,scoring='accuracy', cv=cv, n_jobs=1)
# ending time of execution
end_time=time()
final_time = end_time-start_time
# display execution time
print('final execution time is : {}'.format(final_time))

Here we see that with 1 core it take around 10 seconds to execute, and this is a very huge time.
We don’t write the n_jobs parameter inside the RandomForestClassifier instead we write it into the cross_val_score because it helps us to do the cross-validation using RepeatedStratifiedKFold
Now, we use this same code with a little bit of change for more cores:
2 CPU Cores:
## CPU cores we use n_jobs
random = RandomForestClassifier(n_estimators=100)
# creating object of RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=4)
# starting execution time
start_time=time()
n_scores =cross_val_score(random,x,y,scoring='accuracy', cv=cv, n_jobs=2) # 2 cores
# ending time of execution
end_time=time()
final_time = end_time-start_time
# display execution time
print('final execution time is : {}'.format(final_time))

yes, here you can see that what the difference between 1 core and 2 core, the execution time is much different from 1 core.
3 CPU Cores:
## CPU cores we use n_jobs
random = RandomForestClassifier(n_estimators=100)
# creating object of RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=4)
# starting execution time
start_time=time()
n_scores =cross_val_score(random,x,y,scoring='accuracy', cv=cv, n_jobs=3) # 3 cores
# ending time of execution
end_time=time()
final_time = end_time-start_time
# display execution time
print('final execution time is : {}'.format(final_time))

Take all the Cores:
## CPU cores we use n_jobs
random = RandomForestClassifier(n_estimators=100)
# creating object of RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=4)
# starting execution time
start_time=time()
n_scores =cross_val_score(random,x,y,scoring='accuracy', cv=cv, n_jobs= -1) # all cores
# ending time of execution
end_time=time()
final_time = end_time-start_time
# display execution time
print('final execution time is : {}'.format(final_time))

Time Comparing of Cores:
## CPU cores we use n_jobs
for core in [1,2,3,4,5,6,7,8,9,10]:
random = RandomForestClassifier(n_estimators=100)
# creating object of RepeatedStratifiedKFold
cv = RepeatedStratifiedKFold(n_splits=5, n_repeats=3, random_state=4)
# starting execution time
start_time=time()
n_scores =cross_val_score(random,x,y,scoring='accuracy', cv=cv, n_jobs = core)
# ending time of execution
end_time=time()
final_time = end_time-start_time
# display execution time
print('final execution time of core {} is : {}'.format(core,final_time))
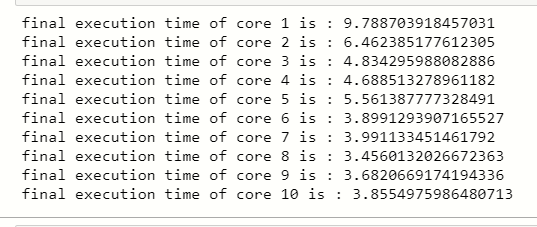
You can see that there is a huge difference when we use 1 core for training our ML model and 10 Cores for training the ML model.
End Notes
Hello, in this article you learned the training of ML models using CPU cores, now it’s time to implement this technique to your machine learning model to reduce the execution time.
I hope you enjoy this article, please share it with your friends.
Check out my other articles: https://www.analyticsvidhya.com/blog/author/mayurbadole2407/
Thank You.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.


