This article was published as a part of the Data Science Blogathon.
Introduction
In Pycon 2021, the creator of the Python language, Sir Guido Van Rossum elaborated on his long and short-term plans on how to make future versions of python faster and he envisions making it twice as fast as it is currently. PyPy and CPython are some of the existing examples which try to increase the execution speed of Python but you can do this yourself also if you just follow some tips and tricks on how to improve your coding skills so that you will be writing efficient code and not wasting any memory or CPU time.
Why choose Python then?
Python has become one of the most widely accepted languages due to the fact that it is programmer-friendly and very convenient to use. Speed was never one of Python’s strong points but it doesn’t mean it has to always give inefficient results. In python People prefer “Speed of Development” over the “Speed of Execution“. It might not have the raw performance of C or Java but you will be surprised to see that how fast a properly optimized Python application can run. This speed is enough to drive various applications like data analysis, automation tools, management, and multiple others. If you follow some standard coding procedures and tips, then you might almost forget that you were trading application performance for developer productivity in the first place.
1. Code Profiling

You need to actually measure your code outside your UAT or Test environment and directly in the production or live environment to exactly find out why or where your code is running the slowest. This is where profiling comes into play and you can use Python’s inbuilt “cProfile” module to inspect your code for any parts which might be dragging down the performance of your overall code.
If you need greater precision, you can use any other powerful profiler which will give you an in-depth analysis but in many cases, a simple profiler can go a long way to track down the culprit function or line of code that is causing a bottleneck in the execution. You will be accurately able to pinpoint and test with a baseline to establish abnormal patterns or execution times in various deployment scenarios and you might try to guess prematurely but that might not lead to much success and hence you should always use a profiler to break down your code efficiently.
2. Memoization
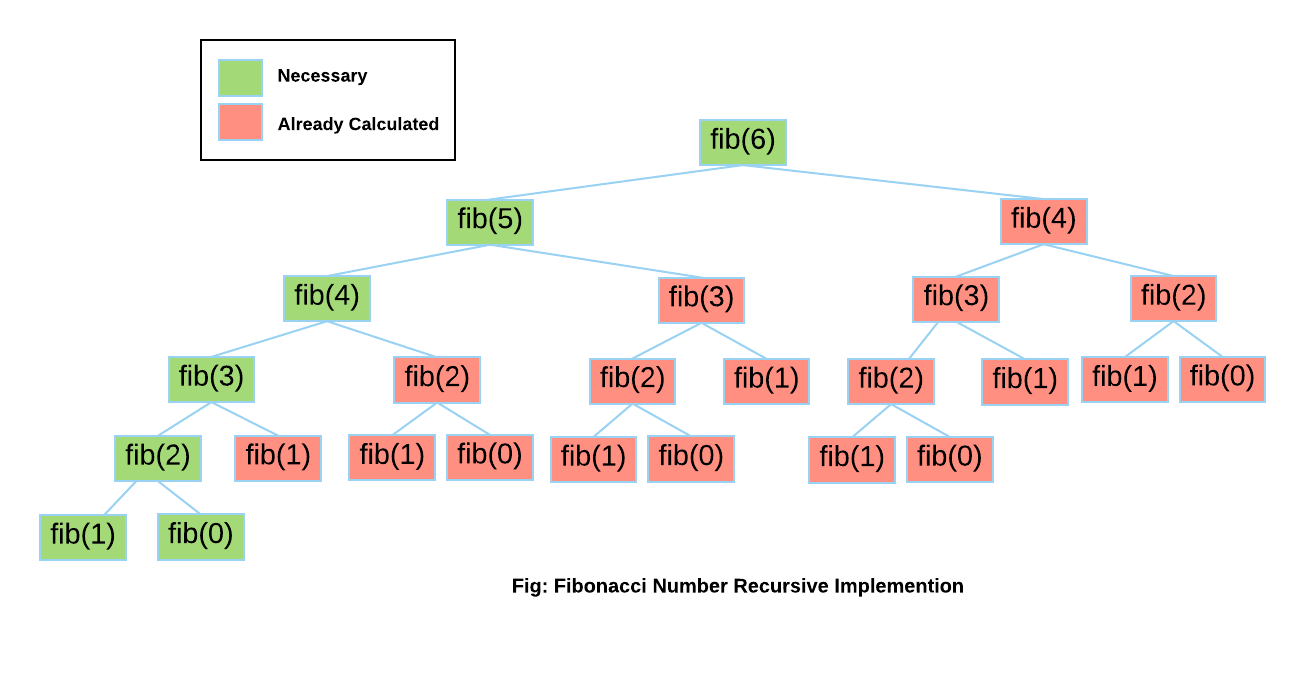
Memoization is a process where you do not repeat the same work over and over again even if it is a function whose value has already been calculated previously. Python provides you with the option of a cache that will give you the ability to instantly fetch results of functions that have been previously computed. These special functionalities of python are known as decorators and you can use them in your code to speed up your code.
Input :
import timeit
def fib(n):
if n < 2:
return n
else:
return fib(n-1) + fib(n-2)
t1 = timeit.Timer("fib(40)", "from __main__ import fib")
print(t1.timeit(1))Add the following two lines of code :
from functools import lru_cache @lru_cache(maxsize=100)
Output : (In my local machine)
5.8000000000002494e-05
Shocking isn’t it? This is the power of LRU_Cache in the functools library. You can set a custom value to the LRU Cache or set it to ‘None’ to store all. This is used to store values that are frequently repeated within a stipulated frame of time. For example maybe the most recently retrieved items over the past 24 hours or a value which will be called multiple times for the next 24 hours.
3. Use Numpy for all Mathematical Operations

NumPy is famous for matrix-based or any array-based mathematical operations but the secret ingredient here is that it stores numerical data more efficiently than Python’s inbuilt data structures. The package has many replacements for traditional math operations and since it utilizes the C libraries, it is much faster than general python functions. NumPy also efficiently manages your memory for very large data structures like lists with a million items in them.
Numpy can optimize and save up to 75% of space than normal python lists. NumPy Array is the only thing that is close to arrays like in Java or C and is easy to declare and use and hence it sticks to the initial commitment of “Speed of Development”.
4. Always use a C library wherever possible

As you have already seen the use of NumPy along with C libraries and how powerful it can be. A similar concept can be applied to other libraries and functions as well. Python libraries are not as efficient as Cones and hence if you have a choice or get an opportunity to use a C library, always go for the C library one. They are faster and more efficient than their respective Python libraries. Python’s Ctypes library is a prime example that is compatible with Python runtime and leverages the benefits of C.
You will be able to get the best results by reducing the number of trips from C to Python as data passing between them is a costly operation. For example consider two scenarios where you are passing one value at a time in a loop to C from Python, computing and sending it back and in another case, you pass a list to C, do your computation there and send the result back. Always go for the second option as it is much faster and efficient in this method.
5. Know your Library and its functions

It is very easy to include all the libraries that you know in a code and never need to worry about importing anything else but in practice, that is one of the worst ways to code actually. It is analogous to ordering too much food than you can generally handle and by the end, you will feel tired and difficult to finish. While python may be a powerful language, it is no excuse to pile up all the existing libraries into it just for the sake of no errors. Instead, you are harming your own code if you are importing more than the required libraries to your python code. Always be aware of what functions you need and what libraries are extra. Delete the line or comment them out so that you remove that overhead and your code will execute faster.
Conclusion
So now you know some tips and tricks on how to make your code faster and more efficient by some simple techniques and if you have any more questions feel free to connect with me on LinkedIn or if you are into Geometric Brownian motion and Stock market, you can check out another one of my articles here. Stay safe and have a good day.
The media shown in this article on 5 Tips and Tricks to speed up your Python Programs are not owned by Analytics Vidhya and is used at the Author’s discretion.
I love to code and create new software for any purpose. I also love to play MMO and RTG games. Other hobbies include Exploring new places and restaurants and making new friends. Feel free to ping me on LinkedIn for any new ideas or same and if you need any help with any code too.






I'm happy to see you working like that. home services app development