This article was published as a part of the Data Science Blogathon.
Introduction
Welcome Readers!!
Data cleaning and Data Manipulation is one the primary step in a machine learning project. It involves many steps like removing null values, handling outliers, features encoding, and many more. Data cleaning is very time-consuming and very tedious and it requires very patience. According to a recent survey, data scientists spend almost 60% of their time in data cleaning. We can’t neglect this step because we can’t feed messy data in machine learning models otherwise we won’t able to get useful insights.
There are many tool and libraries that are useful to handle messy data and saves developers time. In this blog, I am going to cover some useful python libraries and tools that could be very handy. So let’s get started without any further delay!!

Table of Contents
- Dora
- Arrow
- PrettyPandas
- DataCleaner
- scrubadub
- Beautifier
- Tabulate

Dora
Dora is a library intended to improve on exploratory data analysis which is a particularly difficult task. It tries to automate the monotonous tasks that require a lot of time. The library provides a lot of functions that are very useful for feature extraction, data cleaning, feature selection, visualization, etc. Aside from this, it is also useful for versioning transformation of data and partitioning data for model validation.
This library utilizes scikit-learn, pandas, and matplotlib. The goal of this library is to add extra highlights to the general library referenced before for exploratory data analysis. This library is created by Nathan Epstein.
Installation
Dora can be installed by using the below command:
pip install Dora
Features
- Data Cleaning
- Data Versioning
- Data Visualization
- Feature Extraction
- Feature Selection
- Model Validation
For more information check official documentation: Link
Arrow
As a python user/developer, you may experience confronted a great deal of difficulty managing date and time format into some other time region format. We mostly used manually built functions to handle days, hours, minutes, etc. You may wind up utilizing plenty of libraries like datetime, time, dateutil, and so on that require a ton of additional code to be composed. Imagine a scenario where you learn one single library that presents all significant library highlights and, most importantly, gives extra highlights to make you code less. Isn’t it amazing right? So, Arrow is a python library that handles dates and times. It helps you to work with dates and times by writing lesser code and fewer imports. It has an intelligent module API that handles many common scenarios.
Features
- It works for a Python 3.6+
- Timezone conversion
- It is aware of timezones and it enables easy timezone conversion
- It parses and formats string automatically
- It supports the ISO 8601 standard
- It support for pytz, ZoneInfo tzinfo, dateutil objects
- It generates ranges, floors, Time spans, and ceilings for a time ranging from microsecond to years
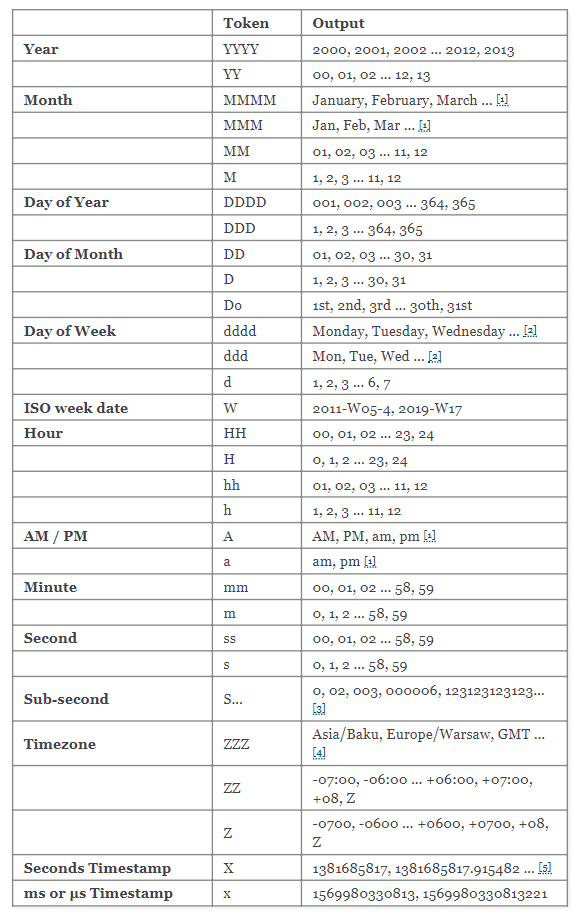
Supported Tokens:
Installation
It can be installed by using the below command:
pip install –U arrow
For more information check official documentation: Link
PrettyPandas
DataFrames are incredible, however, they don’t create the sort of tables you’d need to show your chief. PrettyPandas utilizes the Pandas Style API to change DataFrames into nice presentable look tables. Make outlines, add styling, and design numbers, sections, and columns. Special reward: strong, simple to understand documentation.
Features
- It has chaining commands
- It adds a summary of columns and rows
- It provides number formatting for scientific units, currency, and percentages
- It has a lot of pretty and customizable themes
- It works flawlessly with Pandas Style API
Installation
It can be installed by using the below command:
pip install prettypandas
For more information check official documentation: Link
DataCleaner
It is an open-source python library that is very useful to automate the process of data cleaning work ie to automate the most time-consuming task in any machine learning project. It is built on top of Pandas Dataframe and scikit-learn data preprocessing features. This library is pretty new and very underrated, but it is worth checking out. Creator of this library constantly updating new features. Some of the features are given below:
- Helps in encoding categorical values to numerical values
- It handles null values and replaces them with median(categorical) or mean(numerical)
- Optionally it drops the columns that have missing values
Installation
It can be installed by using the below command:
pip install datacleaner
For more information check official documentation: Link
Scrubadub
It is a free open-source python library that removes personally identifiable information(PII) from free text. So generally speaking, in the fields like finance and healthcare, data scientists have to anonymize data. Sometimes we don’t. This package makes it simple to flawlessly clean close to personal data from free content, without compromising the security of individuals we are attempting to ensure. One of the best things is, it has very decretive and nicely arranged documents.
It currently supports removing the following information from free text:
- Email Addresses
- URLs
- Names
- Skype usernames
- Phone number
- Password/username combinations
- Social security numbers
Installation
It can be installed by using the below command:
pip install scrubadub
For more information check official documentation: Link
Beautifier
It is an open-source python library that is helpful to handle URLs and email addresses. Basic library to clean up and prettify URL patterns, domains, etc. Library assists with cleaning Unicode, special characters, and unnecessary redirection designs from the URLs and give you clean data.

Installation
It can be installed by using the below command:
pip install beautifier
Email Cleanup API’s
from beautifier import Email Email_add = Email([email protected]) Email_add.domain >>> “gmail.com” Email_add.username >>> “gakshay1210”
For more information check official documentation: Link
Tabulate
It is a free and open-source python library that is useful to print small tables without issue by just one function call and it handles all formatting on its own. It’s convenient for making tables more readable with number formatting, headers, column alignment by a decimal, and many more.
One of the best things is, it outputs data in many formats like PHP, HTML, or Markdown Extra, so you can keep working with your tabular data in another language or tool.
Installation
It can be installed by using the below command:
pip install tabulate
For more information check official documentation: Link
Conclusion
So in this article, we have covered the top 7 Data Cleaning libraries in python for machine learning in 2021. I hope you learn something from this blog and it will turn out best for your project. Thanks for reading and your patience. Good luck!
You can check my articles here: Articles
Thanks for reading this article on python libraries for image processing and your patience. Do let me in the comment section. Share this article, it will give me the motivation to write more blogs for the data science community.
Email id: gakshay1210@gmail.com
Connect me on LinkedIn: LinkedIn
The media shown in this article on Data Cleaning Libraries are not owned by Analytics Vidhya and is used at the Author’s discretion.





