This article was published as a part of the Data Science Blogathon
Introduction
Getting complete and high-performance data is not always the case in Machine Learning. While working on any real-world problem statement or trying to build any sort of project as Machine Learning Practioner you need the data.
To accomplish the need for data most of the time, it is required to fetch data from API and if the website does not provide API, then the only option left is Web Scraping.
In this tutorial, we are going to learn how you can use API, extract data and save it in the form of a dataframe.

Table of Contents
- Fetching data from an API
-
- What is API
- Importance of using API
- How to get an API
- Hands-on Code to Extract data from API
- Fetching Data using SQL databases
- EndNote
Fetching data from an API
What is API
API stands for Application Programming Interface. API basically works as an interface between the communication of two software. Now let’s understand How?
Importance of using API
Consider an example, If we have to reserve a railway ticket then we have multiple options like the IRCTC website, Yatra, make my trip, etc. Now, these all are different organizations, and suppose we have reserved seat number 15 of B15 carriage, if someone visits and tries to book the same seat from a different software it will reserve or not? It will show as booked.
Although these are different companies, different software they are capable to share this information. Hence the sharing of information happens between multiple websites through API that’s why APIs are important.
Each organization provides services on multiple operating systems like ios, android, which are integrated with a single database. Hence, they also use API to fetch data from the database to multiple applications.
Now let’s understand practically how to fetch data using in dataframe using Python.
How to get an API?
We will use the TMDB official website, which provides different APIs to fetch different kinds of data. we are going to fetch top-rated movie data into our dataframe. To get the data you need to pass the API.
Visit the TMDB site and sign up and log in using your Google account. After that under your profile section visit the settings. In the left panel of settings at the last second option you can find an option as API, just click on it and generate your API.
Use API key to fetch Top-rated Movies data
Now you have your own API key, visit the TMDB API developers site which you can see in your API section at the top. Click on Movies and visit gets top-rated Now in the top-rated window visit the try-now option where you can see at the right side of send request button, you are having a link to top-rated movies.
https://api.themoviedb.org/3/movie/top_rated?api_key=<<api_key>>&language=en-US&page=1
Copy the link and Instead of the API key paste your API key which you have generated and open the link, you are able to see the JSON-like data.
Now to understand this data there are various tools like JSON viewer. If you want you can open it and paste the code into the viewer. It is a dictionary and the required information about movies is present under the results key.
The Total data is present in 428 pages and the total number of movies is 8551. So, we have to create a dataframe that will have 8551 rows and the fields we will extract is id, Movie title, release date, overview, popularity, vote average, vote count. Hence the dataframe we will receive will have shape 8551 * 7.
Hands-on Code to Fetch data from API
Open your Jupyter Notebook to write the code and extract the data in the dataframe. Install the pandas and requests library if you do not have using pip command
pip install pandas pip install requests
Now define your API key in the link and make a request to the TMDB website to extract data and save the response in a variable.
api_key = your API key
link = "https://api.themoviedb.org/3/movie/top_rated?api_key=<<api_key>>&language=en-US&page=1"
response = requests.get(link)
Do not forget to mention your API key in the link. And after running the above code if you print the response you can see the response at 200 which means everything is working fine and you got the data in form of JSON.
The data we want is in key results so try to print results key.
response.json()["results"]
To create the dataframe of the required columns we can use pandas dataframe and you will get the dataframe of 20 rows which has top movies of page 1.
data = pd.DataFrame(response.json()["results"])[['id','title','overview','popularity','release_date','vote_average','vote_count']]
We want the data of the complete 428 pages so we will place the code in for loop and request the website again and again to different pages and each time we will get 20 rows and seven columns.
for i in range(1, 429):
response = requests.get("https://api.themoviedb.org/3/movie/top_rated?api_key=<api_key>&language=en-US&page={}".format(i))
temp_df = pd.DataFrame(response.json()["results"])[['id','title','overview','popularity','release_date','vote_average','vote_count']]
data.append(temp_df, ignore_index=False)
Hence we got the complete dataframe with 8551 rows. we have formatted a page number to request a different page each time. And please mention your API key in the link by removing the HTML tag. It will take at least 2 minutes time to run. The dataframe we got looks like this.
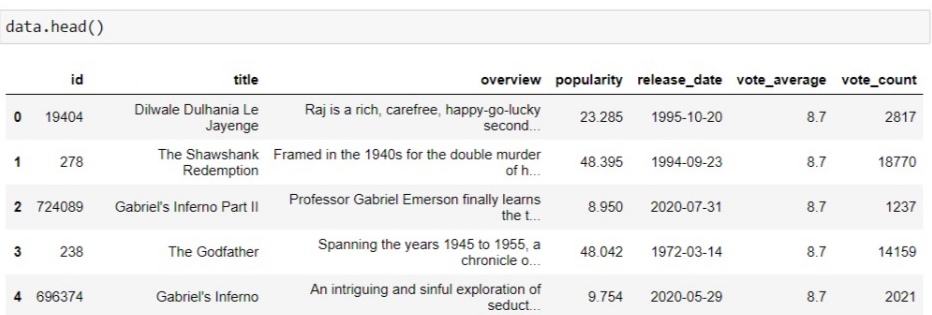
Save the data to a CSV file so that you can use this to Analyze, process and create a project on top of it.
Fetching Data from a SQL Database
Working with SQL databases is simple with Python. Python provides various libraries to connect to the database and read the SQL queries and extract the data from the SQL table to pandas Dataframe.
For a demonstration purpose, we are using world cities and district population dataset uploaded on Kaggle in SQL queries format. You can access the dataset from here.
Download the file and upload the file to your local database. You can use MySQL, XAMPP, SQLite or any database of your choice. ALL database provides an option of import, just click on it and select the downloaded file and upload it.
Now we are ready to connect Python to the database and Extract the SQL data in Pandas Dataframe. For making a connection install the MySQL connector library.
!pip install mysql.connector
After installing import the required libraries and orient the connection to the database using connect method.
import numpy as np import pandas as pd import mysql.connector conn = mysql.connector.connect(host="localhost", user="root", password="", database="World")
After connecting with the database successfully we can query a database and extract a data in dataframe.
city_data = pd.read_sql_query("SELECT * FROM city", conn)
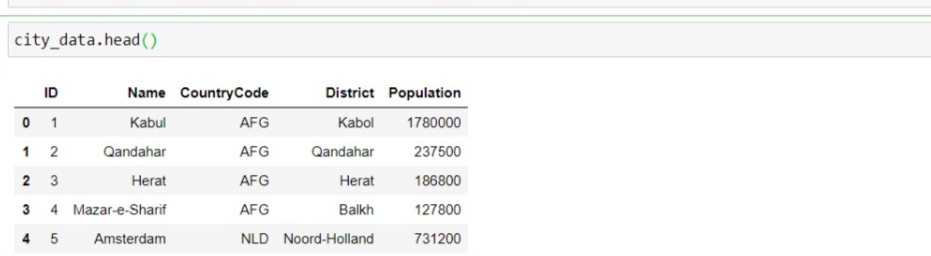
Hence we have extracted data to dataframe successfully and that’s easy it is to work with databases with help of Python. You can also extract data by filtering with SQL queries.
EndNote
I hope it was an amazing article to get you through How to Extract data from different sources. Fetching data with the help of API is mostly used by Data Scientist to data the large and vast set of data to have better analysis and improve model performance.
As a beginner most of the times you get the accurate data file but this is not the case all the time, you have to bring the data from different sources which will be noisy and work on it to drive better business decisions.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a software Engineer with a keen passion towards data science. I love to learn and explore different data-related techniques and technologies. Writing articles provide me with the skill of research and the ability to make others understand what I learned. I aspire to grow as a prominent data architect through my profession and technical content writing as a passion.






Another way to make it very easy is to use Talisman MPCS OpenAPI server thanks to its low-code approach. TMPCS's philosophy is to enable composite webservices, meaning that you build webservices that integrate any data collections part of a process workflow to deliver them as you need.