This article was published as a part of the Data Science Blogathon
Introduction
A detailed guide to implementing a recommender system in a real-time environment.
Data influx in certain domains is huge and dynamic, leading to big data and the need to build recommender systems grows stronger.
To tackle Big Scholarly Data, a recommender system was built to expedite various research-related activities. YouTube, Amazon, Netflix, and other big giants provide recommendations to users helping them find products/items of interest.
Different algorithms are being studied to build an efficient recommender system. Collaborative Filtering (CF) recommender system is one such system that outperforms Content-based recommender system as it is domain-free. Among CF, Item-based CF (IBCF) is a well-known technique that provides accurate recommendations and has been used by Amazon as well.
In this blog, we will go through the basics of IBCF, how items are recommended to users, and implement the same using python.
Item-based CF, developed by Amazon in the year 1998 plays an important role in its success. The basic idea behind this technique is to look for similar items based on items users have already rated/consumed.
Table of contents
How IBCF works?
Firstly, similarities between items are computed. Secondly, based on the computed similarities, items similar to already consumed/rated are looked at and recommended accordingly.
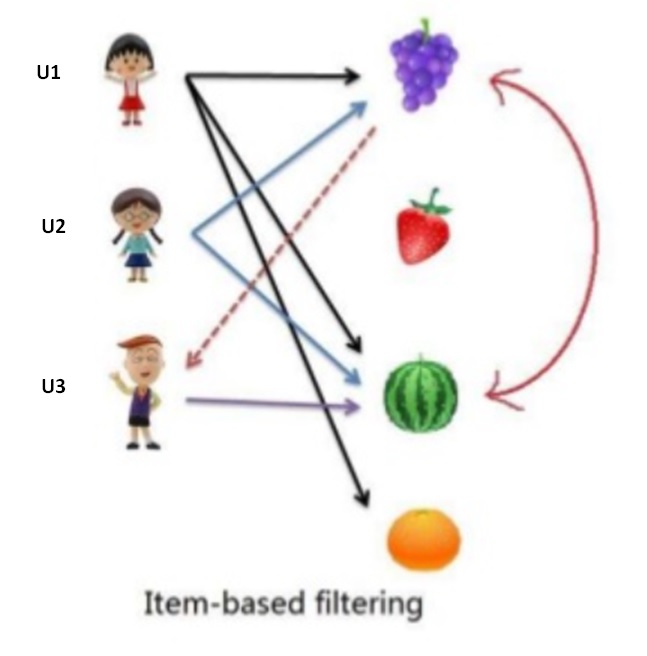
In the above figure, grapes and watermelon are similar to each other as they have been liked/consumed by users U1 and U2. To recommend fruits to U3, we will first find the fruits being liked/consumed by U3 i.e. watermelon.
Now, the next step is to find similar fruits to watermelon i.e. grapes. Therefore, we can recommend grapes to U3 as he likes watermelon and watermelon is similar to grapes.
Let us now start with the step-wise implementation.
We have used the MovieLens dataset consisting of 100K ratings provided by 941 users across 1682 items for implementing IBCF.
Loading Libraries
All libraries are imported at once for comprehensibility.
import pandas as pd
import numpy as np
from scipy.sparse import csr_matrix
from sklearn.neighbors import NearestNeighbors
import matplotlib.pyplot as plt
import seaborn as sns
Loading and Reading DataAs coding is done in google colab, we’ll first have to upload the u.data file extracted from the downloaded zip folder using the statements below.
from google.colab import files
uploaded = files.upload()Once u.data file is uploaded, the next step is to read the dataset using Pandas library as shown below:
import pandas as pd
header = ['user_id','item_id','rating','timestamp']
dataset = pd.read_csv('u.data',sep = 't',names = header)
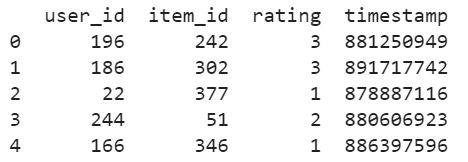
print(dataset.head())The dataset.head() prints the first 5 rows of the dataset as shown below:
Transforming data into the matrix
Next, we transform the dataset into a matrix where each row represents the user and column represents the item.
The n_users defines the number of users whereas n_items defines the number of items in the dataset. The loop iterates through each row of the dataframe and extracts ratings from it to form the user-item rating matrix.
n_users = dataset.user_id.unique().shape[0]
n_items = dataset.item_id.unique().shape[0]
n_items = dataset['item_id'].max()
A = np.zeros((n_users,n_items))
for line in dataset.itertuples():
A[line[1]-1,line[2]-1] = line[3]
print("Original rating matrix : ",A)
The output of the above code is shown below:

The MovieLens dataset consists of ratings on a scale of 1-5 where 1 represents the lowest rating while 5 represents the highest rating. However, different ratings could have different meanings to users. For instance, a rating of 3 might be good for one user while average for another user.
To solve this ambiguity, big giants such as Netflix or YouTube have moved to binary ratings. Therefore, in this blog, we will work on binary ratings instead of continuous ratings to keep ourselves in sync with the latest research.
The below code converts the MovieLens dataset into the binary MovieLens dataset. We have considered items whose ratings are greater or equal to 3 being liked by the user and others being disliked by the user. As we are only considerate about the liking of users, making ratings less than 3 as 0 would not impact the recommendation process.
for i in range(len(A)):
for j in range(len(A[0])):
if A[i][j]>=3:
A[i][j]=1
else:
A[i][j]=0Further, users rarely provide ratings to items which results in a sparse dataset. The considered MovieLens dataset is 93.7% sparse which is further being increased by converting the matrix into a binary matrix. Therefore, to save the memory, we convert the dense rating matrix into a sparse matrix using the csr_matrix() function.
csr_sample = csr_matrix(A)
print(csr_sample)
Items Similarity Computation
Compute similarity between items of csr_sample using cosine similarity as shown below:
knn = NearestNeighbors(metric='cosine', algorithm='brute', n_neighbors=3, n_jobs=-1)
knn.fit(csr_sample)Generate Recommendations
Once, the similarity between items is computed, the final step is to generate recommendations for the target user. Here, we are generating recommendations for the user_id: 1.
We generate recommendations for user_id:1 based on 20 items being liked by him. So, we first get the 20 items being liked/consumed by the user as shown below:
dataset_sort_des = dataset.sort_values(['user_id', 'timestamp'], ascending=[True, False])
filter1 = dataset_sort_des[dataset_sort_des['user_id'] == 1].item_id
filter1 = filter1.tolist()
filter1 = filter1[:20]
print("Items liked by user: ",filter1)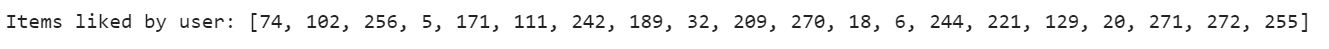
Next, for each item being liked by the user1, we recommend 2 similar items. The number of similar items to be recommended can vary depending on the need of the system.
distances1=[]
indices1=[]
for i in filter1:
distances , indices = knn.kneighbors(csr_sample[i],n_neighbors=3)
indices = indices.flatten()
indices= indices[1:]
indices1.extend(indices)
print("Items to be recommended: ",indices1)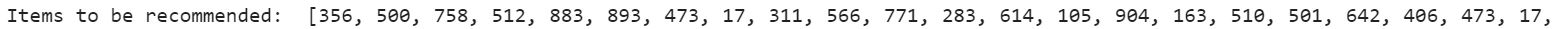
The above output screen shows the recommendations being generated for user1. For ease of use and simplicity, we have used movie_id here but movie_id can be replaced with corresponding movie name by fetching information from the movies dataset.
Conclusion
A recommender system or recommendation system is a subclass of information filtering systems that predict the items the user may be interested in based on the user past behaviour.
Collaborative filtering is one such recommendation technique that filters items of user interest based on user/item similarity. Due to ease of use and domain-free, it is being used and explored at a large scale by researchers.
In this blog, we have implemented item-based collaborative filtering to recommend movies to users using cosine similarity. Other similarity metrics such as the Pearson correlation coefficient and Jaccard similarity could also be explored. This is still an open area of research with the motive to provide the user with the most relevant items.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






