Introduction
In the contemporary scene of business machine learning life cycle, the combination of information science strategies has become vital for associations endeavoring to remain cutthroat and receptive to developing business sector requests. The crucial steps from understanding the business context to the deployment of machine learning models. Each phase within this framework is meticulously designed to address the myriad challenges encountered in real-world scenarios, thereby facilitating a seamless transition from business problem to actionable insights.
This article was published as a part of the Data Science Blogathon
Table of contents
- What is Machine Learning Lifecycle
- Step 1: Business Context and Define a Problem
- Step 2: Translating to AI problem and approach
- Step 3: Milestones and Planning
- Step 4: Data gathering and understanding
- Step 5: Data preparation
- Step 7: Exploratory data analysis
- Step 8: Feature engineering and selection
- Step 9: ML model assumption checks
- Step 10: Data Preparation for Modelling
- Step 11: Model Building
- Step 12 : Model Validation & Evaluation
- Step 13: Prediction & Model deployment
- Frequently Asked Questions
What is Machine Learning Lifecycle
The Machine Learning Lifecycle represents a cyclical process encompassing numerous steps essential for constructing an effective machine learning project. Each stage within this lifecycle adheres to a quality assurance framework, ensuring continuous enhancement and upkeep while adhering meticulously to specified requirements and limitations. It is imperative to recognize the iterative nature of this lifecycle, often necessitating revisitation of prior stages based on insights gleaned in subsequent phases.
Here are the major Steps Involved
Step 1: Business Context and Define a Problem

Understand the business and the use case you are working with and define a proper problem statement. Asking the right questions to the business people to get required information plays a prominent role.
Challenges involved:
The main challenge involved here is understanding the business context and also figuring out what are the exact challenges business is facing.
Example
Basic understanding of what is telecom industry and how it works. In the Churn use case, the problem statement is to identify the drivers for un-subscription and also to predict existing customers who are at high risk of un-subscribing in near future. So that a retention strategy can be planned.
Step 2: Translating to AI problem and approach
This step forms the base for all the following steps. If the problem is not translated into a proper AI problem, then the final model is not deployable for the business use case. From an AI point of view, business problems need to be translated. As the approaches can be many, finding the right approach is skilful. The end-to-end framework of the approach needs to be planned in this step.
Challenges involved
In machine learning life-cycle, translating a business problem to an AI problem is the main challenge industry is facing. Many of the models built are not production-ready, due to a mismatch of expectations from the business view. This happens if the business context/problem is unclear or the business problem is not properly translated to an AI problem.
Example
Churn model can be taken as a Machine learning-based Classification problem. Users of similar behavioural patterns need to be grouped, which helps in planning a retention strategy.
Step 3: Milestones and Planning
Keeping milestones and planning a timeline helps in understanding the progress of the project, resource planning, and deliverables.
Challenges involved
Computational & human resource allocation planning and also estimating a proper deadline for each milestone.
Example
If the data is too large to handle, the computational time for local machines will be more. This kind of cases need to be planned and deadlines need to be planned.
Step 4: Data gathering and understanding
In machine learning life-cycle, the data is not always readily available in proper formats and also not with the required features to build a model. The required data need to be gathered from business people. Data understanding involves having good knowledge on what are the features involved in the data, what they represent exactly, and how they are derived.
Challenges involved
Some of the potential features which affect the target may not be captured by the business in the past. A very good understanding of the provided features is needed.
Example
“Cus_Intenet” is one of the features provided, which is not clear by just seeing the feature name. This needs to be clarified from the business, what it means.
Top 10 Machine Learning Algorithms to Use in 2024
Step 5: Data preparation
The data taken from the client contains required features but may not be in a single table. The data need to be merged from different databases when dealing with larger datasets. The entity-relationship diagram(ERD) helps in understanding the raw data and preparing the data in the required format.
Challenges involved
Data can be from different database management systems like SQL, Oracle DBMS. Prior knowledge is needed on clubbing the data from different data sources.
Example
Machine learning life-cycle, Data for internet users and non-internet users can be in different databases. Data of a user’s internet balance and main balance can be in different files, which need to be clubbed based on UserID.
Step 6: Data Cleaning
Below are the points that need to be addressed in this step:
Duplicates
The data may contain duplicate entries, which need to be removed in most of the applications.
Example: Same customer data might be repeated in the entries, which can be identified using customer ID.
Data validity check
Based on the features, need to validate the data.
Example: Customer bill containing negative values.
Missing values
Based on the business, a missing value imputation needs to be chosen.
Example: If the data is normally distributed, mean imputation can be performed. If the mean and median difference is huge, median imputation is preferred.
Outliers
In machine learning life-cycle, the Outliers can be valid outlier or data entry mistake. Need to understand what kind of outlier the data contains. Based on the outlier type, the issue needs to be addressed.
Example: The age of a customer cannot be 500. It is a data entry mistake.
Step 7: Exploratory data analysis
This step gives more insights into the data and how the data is related to the target variable. This step involves mainly:
Uni-variate analysis
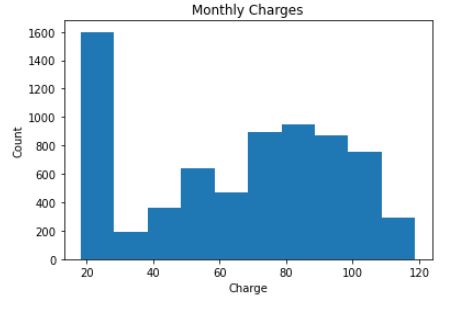
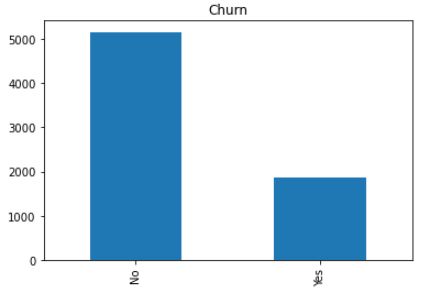
Individual feature data patterns can be known using Frequency distribution table, Bar charts, Histograms, Box plots
Example: Monthly charges distribution, Numbers of churners and non-churners
Bi-variate/Multi-varaite analysis
The behaviour of the target variable based on independent features can be known by using Scatter plots, Correlation Coefficients, and by doing Regression analysis.
Example: Identifying the churn based on user tenure and total charges.
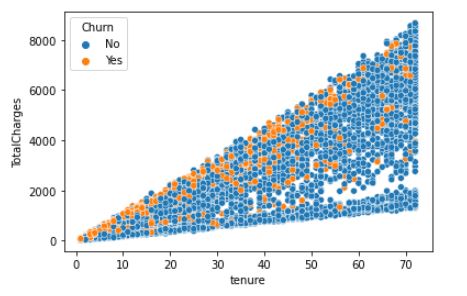
Multi-variate analysis on Churn, TotalCharges and tenure
Pivots
Pivots allow us to draw insights from the data in a quick time.
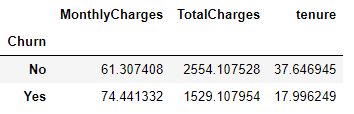
Pivot table based on churn column
Visualization and Data insights
Based on the data visualization in step 2 and 3, insights into the data need to observe and noted. These insights of data are the takeaway points from step 4.
Example: Identifying the gender and age group of churners.
Step 8: Feature engineering and selection
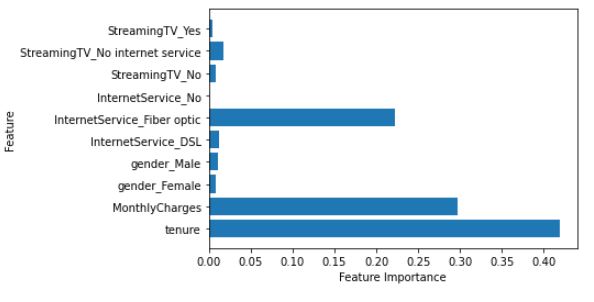
Feature engineering involves identifying the right drivers/features that affect the target variable and also deriving the new features based on existing features.Based on feature importance, some of the features can be removed from the data, which helps in reducing data size. As an example, feature importance can be known by calculating correlation, information gain(IG), and also from the Random forest model.
Example
If the data doesn’t contain “customer tenure” which is important, it needs to be derived based on the subscription start date and current date.
Step 9: ML model assumption checks
Some of the ML models have assumptions check which needs to be done before proceeding to the model building.
Challenges involved
In most cases, model assumptions don’t hold good for real-world data.
Example
The linear regression model assumes1. Data is normally distributed2. The relation between dependent and independent variables is linear.3. The residuals are assumed to have a constant variance. (Homoscedasticity)
Step 10: Data Preparation for Modelling
Below are the topics that can be covered in this step :1. Creating dummy variables2. Over Sampling and Under Sampling (if the data is imbalanced)3. Split the data into train and test
Create Dummy variables
Features of data can be categorical or continuous. For the linear regression model, the categorical data need to be addressed by creating dummy variables. Example: The gender of a customer is 0 if female and one in the case of a male. In regression, this categorical data need to be addressed by creating dummy variables (Customer_0, Customer_1).
Over Sampling and Under Sampling
Oversampling and Undersampling are the techniques used when the data is imbalanced.
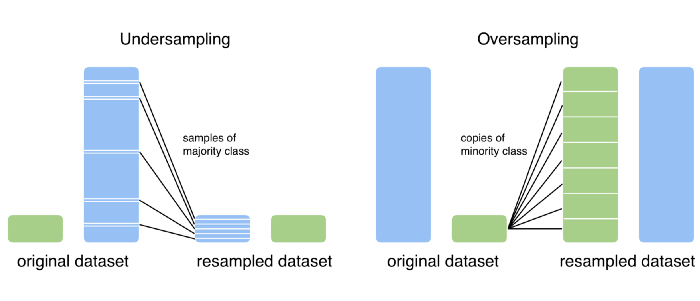
Example: The data may contain, Churn to Non-churn ratio of 95:5. In this case, the model cannot learn properly the behavior of Non-churners.
Split the data into train and test
Test data need to be separated for checking the model accuracy. The most common train to test ratio of a model will be 70:30, 80:20.
Step 11: Model Building
Model building is the process of developing a probabilistic model that best describes the relationship between independent and dependent variables. Various ML models are to be built based on the problem statement.
Example
Customer classification can be done by using Decision trees, Random Forest classifier, Naive Bayes models, and much more.
Step 12 : Model Validation & Evaluation
This step covers1. Testing the model2. Tuning the model3. Cross-validation4. Model evaluation metrics trade-off5. Model Underfitting/Overfitting
Testing the model
Run the model on test data and evaluate the model performance using the correct metric based on the business use case.
Tuning the mode
Model tuning involves, improving model performance by iterating the parameter values during model building. After fine-tuning, the model needs to re-build.To know more about hyperparameter tuning, refer to Hyperparameter tuning.
Example: “Gridsearchcv” in sklearn helps in finding the best combination of hyperparameter values
Cross-validation
Cross-validation is used to evaluate how the model will perform on an independent test dataset. Some of the cross-validation techniques are :1. K- fold cross-validation2. Stratified k-fold cross-validation. To know more about the cross-validation techniques, refer to Cross-validation techniques.
Model Evaluation metrics trade-off :
Trade-offs always help us to find the sweet spot or the middle ground. Machine learning machine learning life-cycle mostly deals with two tradeoffs :1. Bias-variance tradeoff2. Precision-Recall tradeoff know more about the tradeoff’s, refer to Bias-variance & precision -Recall Tradeoff.
Model Underfitting and Overfitting
Overfitting is the case, where the model is trying to capture all the patterns in the training data and failing to perform in the test data.
- Underfitting is the case, where the model is not learning properly in the training data and also not performing well in test data.
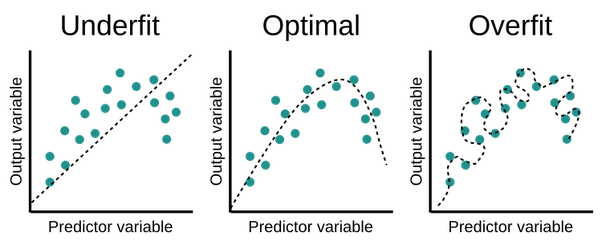
Challenges involved
- Model overfitting and underfitting.
- Choosing the right model evaluation metric based on business context.
Step 13: Prediction & Model deployment
Predict and review the outputs after fine-tuning the model in step 12.This step covers model deployment and also to production models for real-time use. Below topics will be covered under this final step.1. Scaling the model2. Model Deployment3. Business adoption and consumption4. A/B testing5. Business KPI6. Measure performance and monitor7. Feedback loop
Model deployment is out of scope for this article to discuss. For more information on Model deployment please check “Deploying Machine Learning Models“.
Conclusion
In traversing the intricate terrain of data science implementation, this article elucidates a systematic methodology essential for organizations aspiring to harness the power of data-driven decision-making. By delineating each step from business context comprehension to model deployment, this framework provides a roadmap for navigating the complexities inherent in data science endeavors. As businesses embark on this transformative journey, adherence to this structured approach promises not only actionable insights but also a competitive edge in an increasingly data-centric landscape.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions
Q1. How long is a lifecycle?
A. The length of a lifecycle can vary greatly depending on what it refers to. In biology, the lifecycle of a species can range from a few days to several decades or even centuries. In the context of products or technologies, a lifecycle can range from a few months to several years, depending on factors such as market demand, technological advancements, and consumer preferences.
Q2. What is PLC (Product Life Cycle)?
A. PLC, or Product Life Cycle, refers to the stages a product goes through from introduction to withdrawal from the market. These stages typically include introduction, growth, maturity, and decline. During the introduction stage, the product is launched into the market, with sales gradually increasing as awareness grows.
Q3. What is a life stage?
A. A life stage refers to a distinct phase or period within an individual’s or organism’s life cycle. In human development, life stages might include infancy, childhood, adolescence, adulthood, and old age. Each life stage is associated with specific physical, cognitive, emotional, and social changes.
Q4. What is the life cycle of learning?
A. The learning life cycle encompasses four stages:
Experience: Engaging with new information or situations.
Reflection: Analyzing and understanding the experience.
Conceptualization: Developing new knowledge and insights.
Application: Implementing the new knowledge in practice.







It is not distinct from CRISP-DM methodology, which has been there since 1998.