This article was published as a part of the Data Science Blogathon.
Introduction
Let’s explore the merits of using deep learning and other machine learning approach in the area of forecasting and describe some of the machine learning approaches Uber uses to forecast time series of business relevance.
Image credits:https://www.ft.com/content/b3e70e9e-5c4d-11e9-9dde-7aedca0a081a
Use cases for forecasting at Uber
The big area of focus is forecasting because it does help decision-making. And so in this blog, I will give you a bit of a survey of the machine learning approaches Uber used to address the problem of forecasting.
Before you go ahead, if you think this is too long to read please use this –> texttovoice
First of all, one should realize that at Uber, times series are completely and utterly ubiquitous. They are pretty much everywhere. First and foremost, there are the markets. Now, there are many ways of thinking of Uber, but one important way of thinking about it, arguably the most important, is that Uber provides a platform to broker transactions in a variety of markets, usually to do with transportation or delivery. Now, a good brokering platform needs to have a way of taking a snapshot of the state of the market in many ways, and then it involves time. This is why Uber has as many time series as you could possibly imagine about the markets Uber operates in.
And as you can imagine for a brokerage platform, it’s also very important to have an opinion about the future. That’s why forecasting is so important.
The typical market Uber deal with, certainly, for instance, UberX, the product that put Uber on the map, is a very simple structure which is two-sided, where you have a clear supply, which is the drivers, in this case, a clear demand, which are the riders, the individual riders, and the notion of a transaction. When a driver and a rider agree on taking a trip together, that is a transaction. So Uber needs to keep track of that.
But there are more interesting markets Uber deals with, which are typically multi-sided as well. For instance, the ride-sharing product, UberPool, has clearly a one-sided supply, but it has multi-sided demand, because Uber has many riders that would interact with one another, and they need to coordinate all these parties in order to have the transaction occur.
Or another example is, for instance, Uber Eats (Shutdown), where it takes a restaurant to prepare the food, a driver to want to deliver it, and someone on the receiving end who wants to eat it. And only when you coordinate among these three sides, you get, in fact, a transaction. It also means that the transaction is, in fact, multilayered.
And Uber needs to capture all of these aspects. Uber needs to figure out when it is that the restaurant gets the order when it’s finished preparing it when it needs to be picked up, and when it needs to be delivered, and so on. Markets are not the whole story though. There are also all sorts of internal resources Uber is very keen on capturing, especially to do with infrastructure. So Uber wants to have computed, storage, and data snapshot of the system at all levels of granularity, Uber-wide, all the way down to individual services.
So again, you have a proliferation of time series. And then there is a whole universe of technical time series, which are also very important. The idea is that Uber embraced completely the micro-service architecture idea. So when you turn on the app, you should be aware– you probably already know– that there is behind the whole cloud of micro-services talking to the app and to one another. And I represented this with a cartoon over here.
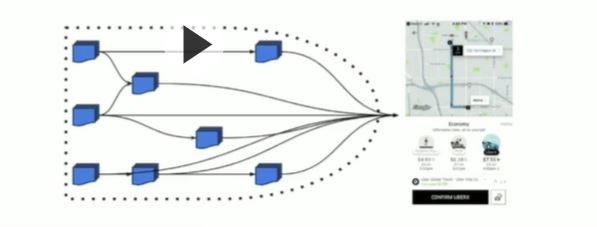
And in fact, quite complicated in connection with all these many micro-services. Now, Uber wants to capture the state of these micro-services and the state of the communication between micro-services with fairly refined granularity. And these are all-time series Uber needs to track for one reason or another. Certainly the level of the market, Uber are interested in all the markets Uber operates in. Uber offers several products for each of these markets. Uber has several up versions, and then there is the powerful combinatorics of geographic multipliers– all the cities Uber operate here, all the neighborhoods Uber operates here.

Image Credits:https://eng.uber.com/forecasting-introduction/
For instance, on the leftover here, you can see a picture that shows a snapshot of one particular market in some areas for one particular product, the domain UberX product, where you see the level of granularity– geographical granularity– Uber is interested in. And this is represented as a heat map that evolves in time, where red means many transactions, namely many trips occurring. Blue means fewer, and then a yellow-red is in between.
Time series
When it comes to technical time-series, Uber also has a very powerful multiplier. There are very many micro-services, and there are communications between micro-services, which scales like the product, the square, of the number of micro-services. So in fact, at the latest tally, when Uber computes all the time series that Uber originate through these that Uber might want to keep track of, it ranges in the order of a billion, because of these remarkable multiplier effects. The edges represent API calls between micro-services. And this is just a corner of the space. It doesn’t represent the whole set. But just you get a sense of what is the scale.
So Uber has to deal with several compounded difficulties over here. The horizons of interesting forecasting are also quite varied. Sometimes Uber is interested in really short-term forecasts, almost real-time. Uber does that to price a property transaction in those markets. Uber does it for reliability purposes. If a time series is supposed to measure in some way the health of the system, Uber wants to know that the system is becoming unhealthy as soon as possible so that Uber can interfere before the problem expands. Uber is interested in the medium term, and that really means between a few hours all the way to a month or so, usually to find out the markets are in balance. If there is a big imbalance between supply and demand, Uber wants to know, because Uber has levers, for instance, incentives so Uber can pull to equilibrate the market, which is good all around. And then long-term, which means up to a couple of years ahead, largely for infrastructure where Uber wants to figure out what is the infrastructure demand projected to be so that Uber can make sure that the infrastructure supports Uber growth without necessary overspending. So lots of compound challenges. Perhaps I convinced you Uber has a high cardinality problem, lots of time series.
They are also very different from one another so that an intelligent system that takes in this time series, has to be able to deal with lots of different patterns.
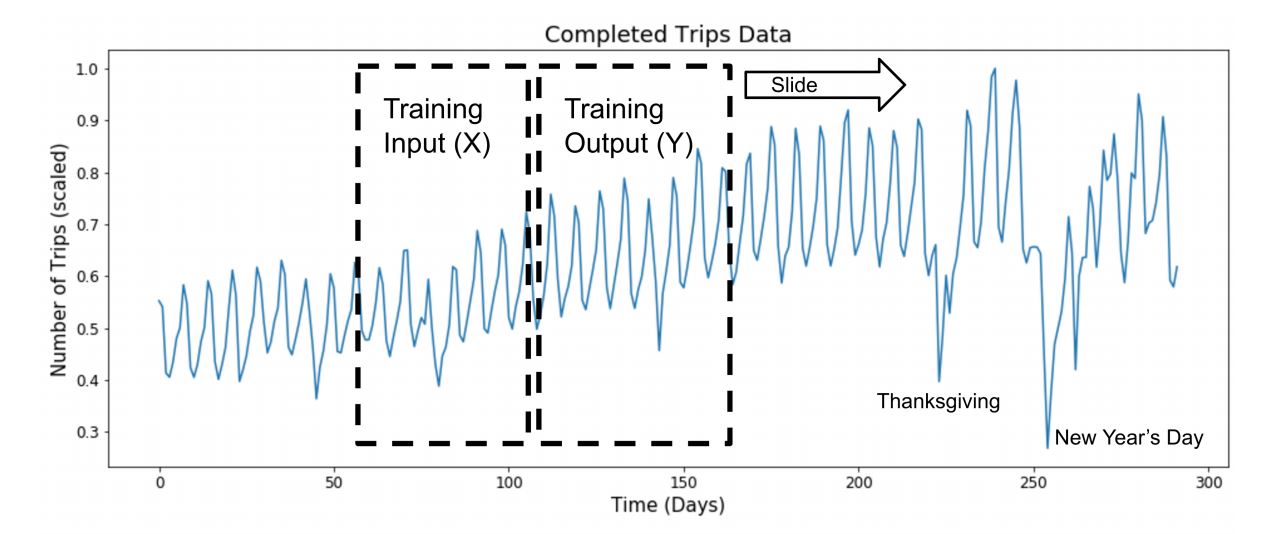
Image Credits: http://www.cs.columbia.edu/~lierranli/publications/TSW2017_paper.pdf
Sometimes Uber has to deal with a lack of information, either because Uber has a short time series in markets where Uber just started or because the time season maybe is long in itself, but it’s fairly sparse. This is, for instance, a technical time series that counts a certain number of events. And you see that oftentimes nothing happens. Largest stretches where it’s just 0, then you have one count, two counts, three counts, and so on. So these are all-time series that Uber has to deal with and forecast all of this larger variety of things.
Classical Methods
Uber gets the time series, and they learn time series by time series, nothing across time series typically. And what you do there is that you decomposed your observable states of the time series in unobservable states. In order to do that, you have to have an opinion about the structure behind the time series, which you impose. The composition, for instance, a typical composition could be level, trained, and the periodic aspect, seasonality, which in general there is more than one.
Once you’ve done that, then you estimate this unobservable component by averaging appropriately historical values. And you do that typically through some kind of exponential smoothing, hence the name. Then the focus is relatively simple. You move the structure regression one step ahead at a time. You recombine them, and this is your forecast for the times series. Now, many methods such as in the Holt-Winters or ETS or even ARIMA can be cast in this context– belong to this classical methods family.
An example of such a composition here at the top, the completed trips in one particular location. That’s what the time series actually looks like. This is observable. And then you have the composition, in this case, run by the ETS, error trends seasonality model, which is of the classical methods family, where you have the completion into an overall level trained, how the time series is trending, and then the periodic seasonality at the bottom. There are many other such compositions that can be done, but the general idea is still there.
Now, these are statistical models. In fact, sometimes they referred to it like that. And the reason is that even though the structural equations give you a point estimate, typically you can treat this as stochastic processes with assumptions about the errors. And once you have done that, then you can focus not just on the point value but the whole distribution. And then you get prediction intervals forecasted.
Machine learning Methods
There are basically four main milestones that I’ll touch on.
- A relatively simple model, a generalized linear model.
- Quantile random forest, a cousin of random forest. This is a more interesting model that can learn nonlinearities.
- Hybrid approach as Uber combines statistical and machine learning models, in this case specifically deep learning, which again is best in class.
Generalized linear model.
So it’s a very simple model. It cannot learn a nonlinearity. The nonlinear structure is imposed by the creator through a linking function. So basically, Uber says that the response variable is just a function to be specified of a linear combination of the features. So clearly, the emphasis on who would be on featurization of it there. This can be turned into a stochastic model, which allows you to do a density forecast, which is what Uber needs in any case. I think any serious forecaster should always provide also intervals, not just point forecasts. And you do that by having your opinion on the errors, the deviations between the response estimates and the actuals. And typically, people use Gaussian or Poisson error or you can generalize. Once you’ve done that, then you do get a density forecast. And you can also optimize, for instance, through maximum likelihood selection.
This is one of those medium-term forecasts when Uber looks maybe a couple of weeks ahead, and Uber tries and figure out if there is an imbalance in the markets by forecasting supply and demand and seeing if they match. So here, Uber train a model per city, which learns across all the neighborhoods in that city.
And I show this for a large cluster, meaning a large neighborhood versus a small neighborhood. And you see that the performance is very much on top of it, quite a bit, more so for the large cluster than for the small cluster, but nonetheless, this is the type of precision you can get. Now, this is an interesting point.
Even though this seems very precise already for most purposes, there is in fact a pretty direct impact on the bottom line for Uber, and therefore a pretty direct business impact to actually improving the forecast position, even a little bit, which makes Uber a good place to do this type of activity, because fancy data science is not done just for its own sake, but it has an impact on the business quite immediately. So Uber can take this as a start point in the narrative. Uber keeps track of how they can improve on this problem. Now, the emphasis, as I was saying, is clearly on featurization. Indeed, in this model, there’s very little else. But it is a common refrain. You will see it occurs throughout the older models Uber will look at.
If I want to know the time series is for what neighborhood of that city because maybe neighborhood can actually learn more from one another than farther away neighborhoods. And I want to know what hour of the day, what day of the week it is. Now, these are categorical features. So their first inclination would be to one-hot encode them. And indeed, Uber did that. And the model performed extremely poorly compared to statistical methods. It was only when Uber had that intuition that, instead of doing this, perhaps they could take some kind of fingerprint of these geo-temporal units where Uber looks at a geo-temporal unit, meaning the values that all the time series in a given neighborhood take over a certain window of time, which I represent here with the red box.
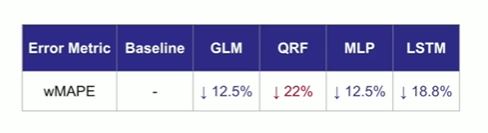
But I can show you what is the improvement, the relative improvement, and the GLM model, as I described, provides a 12.5% improvement, which is quite a bit, if you think of it, in terms of the error. And the metric of error here is MAPE, which I’m sure people in the forecasting community are familiar with. But for those who don’t know, think of it as the mean absolute percent error. And there is a way in the schema which is perhaps less important. So let’s not talk about that right now. So 12.5% is the first thing Uber can get over statistical models.
Quantile Random Forest
I’m sure you’re familiar with random forests. Perhaps you have not played with quantile random forest, which is a close cousin. Just to give you a sense of the general idea, it is very simple. So for the random forest, you start clearly with the decision trees. Think of them as extremely greedy optimizers for entropy. You always greedily optimize them node by node what is the right decision.
People use that and they realized they were powerful but also had quite a bit of variance. But they also realized that if you randomize the process and you consider a large collection of such trees, you obtain much less variance in your forecast. And then the idea there is that, of course, you aggregate the predictions of each individual tree, typically with some kind of aggregation fraction, typically the mean, and you get a single prediction for the forest. Now, quantile random forest just goes one step beyond. Instead of the mean, you consider all the predictions. You form distribution and out of that, you compute what are the quantiles, hence the name quantile random forest.
So this turns the random forest into a predictor for prediction intervals, which is again a requirement for our agenda. So then, this is a much more interesting model. It can learn nonlinearities instead of imposing them. Maybe it’s not obvious from everything I said, but yet again, the refrain that featurization is paramount and it is hard work, in this case, it’s there.
The thing is that quantile random forest has no sense of time whatsoever, which means that you have to, for instance, compare to recurrent neural networks, which have a sense of time. So you need to provide this sense of time through intelligent featurization, which is not simple, but you can do it. And it is still easier than, in our experience at least, than for neural networks, even though some of them have a sense of time.
The main reason it’s easier is that if there are categorical features or, in general, if there are features that value very much in the span, quantile random forest has no problem whatsoever with it, whereas for neural networks, if you want stochastic again to the center to optimize them properly, you have to be very careful to normalize and balance things. Quantile random forest has no problem. So by using this method, in a very quick time, mostly focusing on featurization, they were able to improve dramatically over GLM with the improvement of 22% compared to the baseline on the same problem. So I’m keeping a tally so you get a sense.
Deep Learning – Neural Networks.
Now, this is a much more interesting model, of course. You know what neural networks are. So let’s not even talk about that. Let me mention, however, there is a variant of neural networks, of recurrent neural networks, which are especially suitable to times series forecast or, in general, in any prompts which have a sense of ordering.
For instance, natural language processing also is another use case there. Because they do have a sense of time, and this is accomplished by having an internal state that gets updated from one iteration to the other, which therefore allows them to keep memories. So they have a sense of the past. One type of recurrent neural network is long short term memory. It’s a particular cell. So where I say A there, there is in fact a cell inside with an internal structure. And the idea there, going back, is that they are able to retain a variable amount of past information in these apps a lot in optimization to avoid the problem of vanishing gradients. Specifically, what is true over here is that Uber has a cell-like that.
What this allows is that you can allow for a selective amount of memory, hence long and short term. And moreover, this is adaptive. From one iteration to the other, you can in fact change how much memory you retain. And this really helps with optimization. So LSTMs or other cells of this type are, in fact, the rule of the game typically when you want to use deep learning in the context of time series forecasting.
So what does the architecture look like? The architecture, typical architecture, is not as deep as people, for instance, used to computer visions have seen. Uber will see an improved architecture, which is more complicated than this, but this gives you the general idea. Uber basically has two hidden layers, on top of which you have another hidden layer, which is just a standard layer, two layers of LSTMs, and one standard layer, and then you have the output.
Notice that there are variations. You will see a few in the subsequent parts of the talk. But this is a general idea. So they’re considered shallower that you find in other fields. But the emphasis here, again, is that rather than optimizing on the architecture, you get to the bigger bang for the buck, so to speak, by actually doing good preprocessing in time series featurization.
Now, here, I emphasize the difference between row input and input, because instead of providing the time series just as it is, Uber actually does quite a bit of preprocessing, mostly to make sure that all the time series and all the features are normalized in a similar way. And this really helps for the optimization of the system. Now, Uber uses this type of architecture, variations from top of this, in a variety of contexts. Uber also uses a very short horizon for anomaly detection, especially for reliability purposes.
And then again, a type of architecture of this comes as an ingredient in the hybrid models I claim are best in class.
Hybrid Models
Uber spent maybe double the amount on improving deep learning models for this problem than Uber’s needs for quantile random forest, and they still over this amount of time were not able to beat the performance or quantile random forest. Now, I show you a couple of things. I show you a simple multilayered perceptual neural network architecture. And the reason I show you that is because this is the closest analog to quantile random forest and that it has no sense of time either. There is no internal state, just multilayer perception.
And the performance with similar preprocessing as quantile random forest is considerably disappointing, 12.5%, improvement, a better match for GLM. Now, where you add the sense of time like with LSTM, then that bumps you quite a bit. And so you get 18.8%, still less than what Uber obtained for quantile random forest. So now, is this the end of this final word? No, I don’t think it’s the final word absolutely. There’s quite a bit of work they are still doing on LSTMs. You can improve the performance.
You can play with different architecture and so on. But the one thing is that there’s not an immediate silver bullet. And they found that it is better to combine LSTMs with stochastic models if you really want to get good performance. So perhaps your time is better spent looking into these hybrid models, at least in our experience, than trying to refine the performance above. So this is pretty telling, especially because comparing the forest was put together relatively quickly and achieved pretty good results right away. Deep learning proved considerably harder.
Final word
How do you recover density forecasts when it comes to deep learning?
Now, density forecasts are paramount. You want to have prediction intervals, otherwise, you don’t know the precision of your forecast at all. And now neural networks, usually give you just a point forecast, and most people use them in that fashion. So what Uber did, in this case, is very simple. One of two approaches, one considerably more interesting than the other, but both fairly good. One is that instead of having the neural network generate a single number, you have them generate a collection of numbers, one per the point estimate and several for various quantiles of the distribution you are trying to predict.
Other ways
The way that you push the neural network toward predicting a quantile of the distribution instead of the expected value is to use a loss, which is asymmetric, which penalizes over-forecasting more than under-forecasting or vice versa, depending on when you want a high yield of 50 or lower than 50 quantiles. So that’s the pin-ball loss represented graphically over there. That’s one loss that will do the job for you. You have to calibrate it.
One example of this hybrid model was a clear winner in the M4 Competition. Now, again, I don’t expect you to know about the M competitions if you’re not in the forecasting area, although if you are, you probably heard of them. The latest incarnation, the M4, was around this year not long ago. And so one of these models is a winner.
Now, to give you a sense, Rob Hyndman, which is a big name in the area of forecasting, said about the predecessor of the M4, the M3 Competition, there is a bit of a standard for times he is forecasting. He said the M3 data have continued to be used since 200 for testing new time series forecasting methods. In fact, unless a proposed forecasting method is competitive against the original M3 participating methods, it is difficult to get published in the International Journal of Forecasting.
More deep learning applied in-depth
So this gives you the sense that this is a little bit of the standard you want to test your methods against if you want to see if they are viable. The M4 is the latest version, which happened not long ago. It includes about 100,000-time series, for which you know the historical values, the frequency, whether it’s yearly, quarterly, monthly, weekly, daily, hourly. And finally, just the general area. Some of them are in demographics, some in finance and industry, and so on. But you don’t know anything else. So it’s a tough, challenging problem because you don’t have much information about that. M stands for Makridakis, who is the professor who put together the first competition as well as participated in all the subsequent ones and ended.
So then, what do I mean by hybrid models?
These are models that combine. On the one hand, the traditional structural models I described at the beginning, the exponential moving family being a clear example, together with machine learning models, usually deep learning and so in particular in our versions. They are hierarchical in the sense that the parameters you have to train, are local and some are global. Local in the sense that they are by time series. They vary from time series to time series. Global in the sense that they are not variable by time series, but they are learned across time series.
Now, in our experience, the reason why neural networks don’t always perform as well as other methods are because they tend to average a little bit too much across the time series that are provided in training, which really means that perhaps in this hybrid model Uber has an opportunity to bring back a little bit of the specificity the neural networks have traveled to capture. And now there are two models I want to discuss, and I think in the interest of time, I’ll move on to the second one, the one that won the M4 Competition, and then I’ll go back to the event lift model if Uber have time, because I’m not sure otherwise I have time to cover all of this. So let’s talk about the M4 model. It is a hybrid of recurrent neural networks, the RLSTMs, and the one member of the exponentials moving family.
So let’s talk about the core deep learning module. It’s a variation of the architecture you’ve seen before, but it is a little bit more interesting. There are two blocks of each two layers of the hidden layers of LSTMs where Uber also uses dilation, which means the data in LSTMs you have an iteration step, which updated the internal state, right? And you provided which step the previous value of the state so that it can be updated. Dilation just means that you actually provide also a shortcut where you provide the state one time before, two times before, four times before, eight times before. So you kind of has a way of bypassing the mechanism by which LSTMs acquire memory and modify the memory. Now, you see, already here this is not uncommon in neural networks. In principle, STMs have all the flexibility to do this on their own. They do have the structure in the cell that allows this variable retention. But it really does help if you provide a little bit of a nudge and in the architecture, you hardcode some of these choices instead of hoping for the optimization to bring it up. This is a common refrain, which makes deep learning extremely effective but also a little bit less of a silver bullet that Uber still hopes for.
So now how do you go about optimizing these types of models? It’s not trivial anymore now, because you cannot just use stochastic gradient descent and optimize it once and for all. You go through e-books and so on and you update the weights until you get to stability. You can’t do that anymore, because some of the coefficients in my nomenclature alpha and gamma are time series by time series. So in order to perform an optimization of a model like that, you need dynamic computational graphs. In other words, the computational graph has to be dependent on the time series. It needs to be updated as you move from one-time series to the other. Now, this is provided by several frameworks. Uber did this in Dynet. Uber then, later on, was implemented in PyTorch. PyTorch is especially important to us because as a tool bearer, Uber has a team that created a library that leaves on top of PyTorch call Pyro which is especially good for doing basing optimization. So to have a version of this in PyTorch was important to us. And I think this is also supported by TensorFlow now, at least in some fashion. But I don’t know too much, because Uber hasn’t used that.
So you need dynamic computational graphs in order to do that. And this is all I can say for now about this particular model, which again, won by a significant margin, in some categories up to 30% compared to the next winner– to the second place model.
I think the point Uber has just switched to machine learning models.
What Uber does is that when a new time series comes in that Uber are not– to establish a baseline, Uber runs it against a stable of models. And then Uber tries to improve over that. So you know, when I was keeping a tally, there is a baseline that I did not indicate the actual number, because I don’t think I’m allowed to. But I just wanted to give you the relative improvement. That baseline is obtained by running a bunch of models against the time series of one on one. And then they are trying to improve on top of it. And these models include ETS, Holt-Winters, Holt-Winters with double seasonality, which are all ARIMA, ARIMA X, which are all members of what I call this exponential smoothing state parameter. Even though ARIMA is not constructed the way, it’s been shown that you can cast it as a member of this particular family with some choices. So those are included. The M profit has included that as well.
So when I say baseline, I give it the best-performing model among the large number. They are talking 10 or 15 of the exponentials moving family as well as profit. So the answer is that these can perform– the machine-learning-based methods can outperform those methods. It really depends on the problem space.
Uber finds that if these three conditions are met, namely you have plenty of history, there’s little transfer learning you can do across time series. And there are not too many external regressors you might want to add, then it’s hard to beat those. I hope this gave you the general idea of Uber’s internal structure of forecasting.
With Uber, you can learn a lot about Artificial Intelligence.
I hope you really enjoyed the article.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
I have 4+ years of working experience working with Big Data Analytics and the Cloud. Worked with different domains like Capital Markets, Insurance, FinTech, MedTech/Healthcare. Have designed scalable & optimized data pipelines for mostly Batch Processing Utilizing Cloud.
✔️ Building data warehouses /Data lakes using modern cloud platforms and technologies.
✔️ Implementing and automating data pipelines, ETL processes.
✔️ Data Cleaning, Processing, and Standardization (Machine Learning and NLP).
✔️ Data Migration (Heterogenous and Homogenous)
Some of the technologies I most frequently work with are:
👨💻 Programming: Python, PySpark, SQL, Pandas
☁️ Cloud: AWS
🔰 Databases: Redshift, RDS, PostgreSQL, MySQL, S3, Cloud Data Store
⚙️ Data Integration/ETL: AWS Glue & EMR, Airflow
📊 BI/Visualization: Tableau, Excel
🤖 Big Data - Hadoop, Hive, Spark, NLP, Jupyter Notebook, Data Structures
I love to adapt to new technologies to solve different business problems. I want to work with Petabytes of real-time/Streaming/Batch data and build good platforms. Looking forward to exploring.






That was very informative. Thank You
This is certainly some lecture transcript. That is nice to have it, but it lacks some slides from the original presentation. Could you, pls, publish a link to the original video?
Thank you for this amazing article. Please keep up the good work.