This article was published as a part of the Data Science Blogathon.
Before going ahead, lets we take a brief discussion on Scraping and then AutoScraper:
What is Scraping?
Web scraping is a fundamental technique that is used for extracting useful information such as contact, emails, images, URLs, etc… from the websites. The other form of web scraping is crawling. It is used when we need a huge amount of data that was structured and labeled for industrial fundamentals. The web scraping software may directly access the world wide web by the HTML protocols.
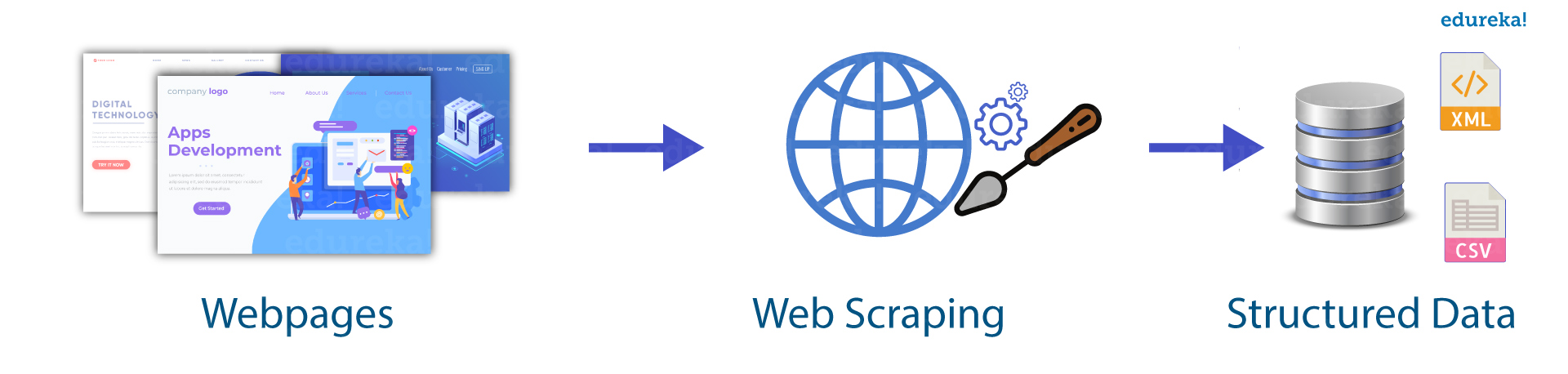
You know that the new forms of web scraping involve the observation of data feed on web servers, for example, JSON file which is used as a transporter between client and web server.
There are many large websites that Google, Facebook, Amazon, etc.. provide API that allows you to access their data in a structured or labeled format.
Now, we take a brief discussion of the AutoScraper library:
What is AutoScraper?
When we talk about scraping, then there is lots of stuff on the website that we want to scrap but writable scripts take lots of time to scrape data and it is a very lengthy process, to overcome this problem a group of python developers develops a library which will scrape the whole data from a website in an easy way. So AutoScraper is the web scraping python library that is used for scraping data from a website in a simple, easy and fast way. It has a user-friendly environment by this scraper can easily interact with this library.

It uses the URLs and HTML content of the website for scraping reliable information and data.
Point to be noted: It learns the scraping rules and returns similar elements in a good format.
It is easy to scrap the content from the website which was easy to go through like title, price, name, ratings, etc… Wait a minute! what will we do for images? it is a big question that arises we can give the image during the execution of the program😅. I am finding a way to scrap the images from the websites. Let’s discuss below:

First, we go for the installation of this library:
Installation of AutoScraper
There is two way to install AutoScraper:
Using pip:-
Write this following code in the command prompt,
pip install autoscraper
or with git repository,
git clone https://github.com/brandonrobertz/autoscrape-py
cd autoscrape-py/
pip install .[all]
Now we import important modules:
Importing Modules
# Importing AutoScraper from autoscraper import AutoScraper
Here we import AutoScraper class from the library.
Now we feed the URL to the AutoScraper function for further scraping:
URL:- https://www.bookswagon.com/
Here we feeding the E-commerce website URL to the AutoScraper class for extracting or scraping the images of books.
Now, before going ahead we first see the demo scraping od titles and prices of books to have a basic and better understanding of scraping code:
Demo Scraping
Now, we will feed the list of items for scraping, So first of all we have to initialize the AutoScraper class with its object:
Wanted list:
create a list of elements
# create a list of elements items = ['Rs.349' , 'The Secret of the Nagas']

Object Creation:
# create object scrape = AutoScraper() # feeding for scraping final_result = scrape.build(URL,items) # display result print(final_result)

Time to Scrap Image
Now, you have an idea about the web scraping code that we discussed above, So we use this same method for scraping the images from the website with a few changes. So, we will discuss the method or technique for scraping the images from the data. let’s see below:
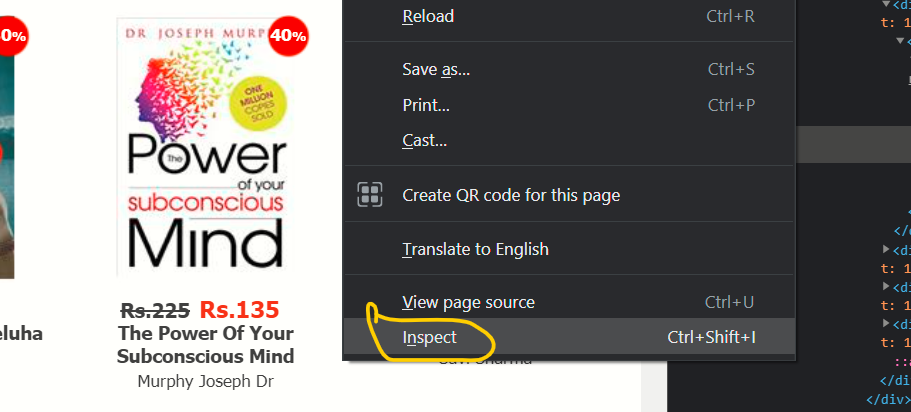
Step 1:
In the first step, we have to right-click on the mouse then select the inspect option from the list of the menu:
Step 2:
After selecting the inspect option, then one HTML content page opens beside the display, after that will hover over the image of the book, at that time notice in the HTML content page you find the URL of the image.
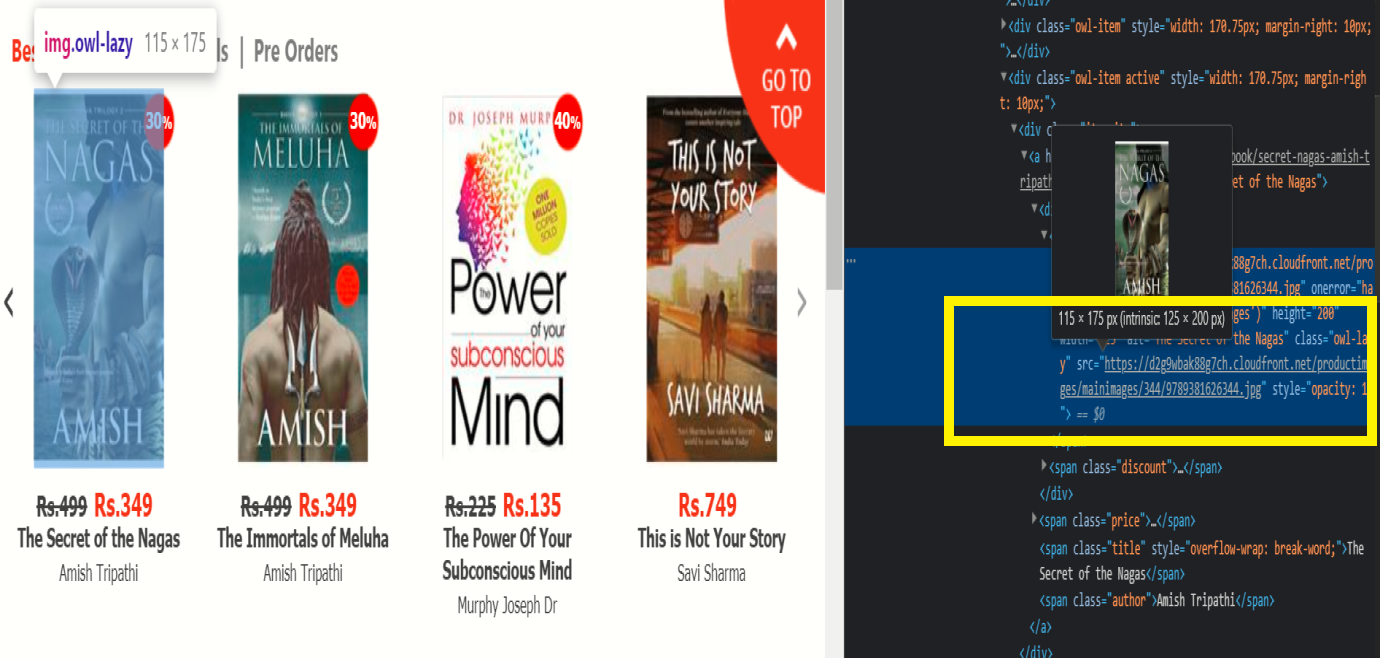
When you find the URL of the particular image then copy that and we will use this in the items wanted list. This is only the change is required for scraping the images from the website.
Step 3:
Now, we will set that image URL along with the books that came into our wanted list,
item = ['https://d2g9wbak88g7ch.cloudfront.net/productimages/mainimages/344/9789381626344.jpg','This is Not Your Story']
After creating a list, we do the same process as we do above:
# creating object scrape = AutoScraper() # building result final_result = scrap.build( URL, item ) # display result print(final_result)
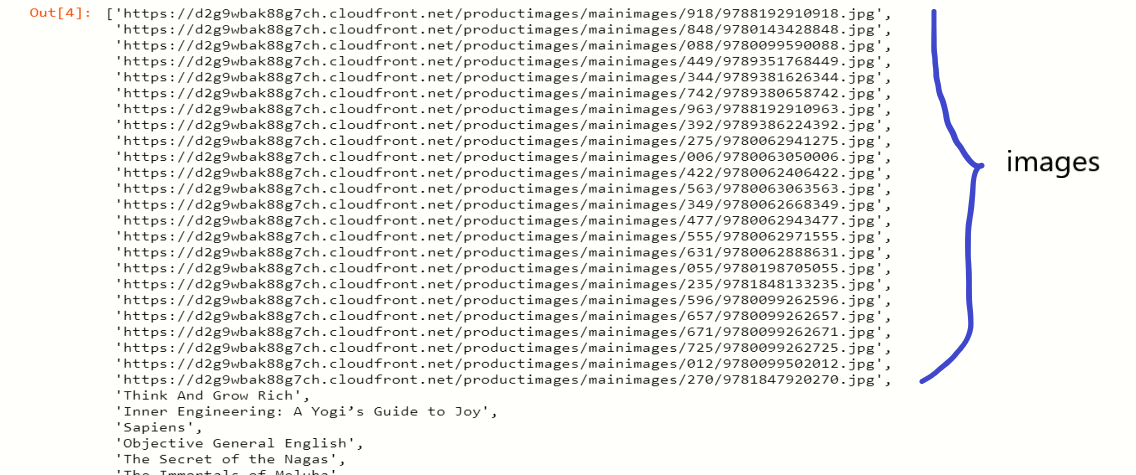
Note: Use URL of images for scraping the images from website
So, this is the process for scraping the images from any website.
Endnote
So, here we will discuss image scraping from the website, if you want to scrap images from the website then use this technique. I am very much amazed by using this AutoViz library. I hope you enjoyed this article and thank you for reading this article.😊
You can connect with me on Linkedin: Profile URL
Also read my other articles: https://www.analyticsvidhya.com/blog/author/mayurbadole2407/
Thank You😎.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.





