This article was published as a part of the Data Science Blogathon
Introduction
Hello Readers!!
Deep Learning is used in many applications such as object detection, face detection, natural language processing tasks, and many more. In this blog I am going to build a model that will be used to solve unsolved Sudoku puzzles from an image using deep learning, We are going to libraries such as OpenCV and TensorFlow. If you want to know more about OpenCV, check this link. So let’s get started.
- If you want to know about Python Libraries For Image Processing, then check this Link.
- For more articles, click here

Image Source
The blog is divided into three parts:
Part 1: Digit Classification Model
We will be first building and training a neural network on the Char74k images dataset for digits. This model will help to classify the digits from the images.
Part 2: Reading and Detecting the Sudoku From an Image
This section contains, identifying the puzzle from an image with the help of OpenCV, classify the digits in the detected Sudoku puzzle using Part-1, finally getting the values of the cells from Sudoku and stored in an array.
Part3: Solving the Puzzle
We are going to store the array that we got in Pat-2 in the form of a matrix and finally run a recursion loop to solve the puzzle.
IMPORTING LIBRARIES
Let’s import all the required libraries using the below commands:
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import os, random import cv2 from glob import glob import sklearn from sklearn.model_selection import train_test_split import tensorflow as tf from tensorflow import keras from tensorflow.keras.preprocessing.image import ImageDataGenerator from keras.preprocessing.image import ImageDataGenerator, load_img from keras.utils.np_utils import to_categorical from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Activation, Dropout, Dense, Flatten, BatchNormalization, Conv2D, MaxPooling2D from tensorflow.keras.optimizers import RMSprop from tensorflow.keras import backend as K from tensorflow.keras.preprocessing import image from sklearn.metrics import accuracy_score, classification_report from pathlib import Path from PIL import Image
Part 1: Digit Classification Model
In this section, we are going to use a digit classification model
LOADING DATA
We are going to use an image dataset to classify the numbers in an image. Data is specified as features like images and labels as tags.
#Loading the data
data = os.listdir("digits/Digits" )
data_X = []
data_y = []
data_classes = len(data)
for i in range (0,data_classes):
data_list = os.listdir("digits/Digits" +"/"+str(i))
for j in data_list:
pic = cv2.imread("digits/Digits" +"/"+str(i)+"/"+j)
pic = cv2.resize(pic,(32,32))
data_X.append(pic)
data_y.append(i)
if len(data_X) == len(data_y) :
print("Total Dataponits = ",len(data_X))
# Labels and images
data_X = np.array(data_X)
data_y = np.array(data_y)

SPLITTING DATASET
We are splitting the dataset into the train, test, and validation sets as we do in any machine learning problem.
#Spliting the train validation and test sets
train_X, test_X, train_y, test_y = train_test_split(data_X,data_y,test_size=0.05)
train_X, valid_X, train_y, valid_y = train_test_split(train_X,train_y,test_size=0.2)
print("Training Set Shape = ",train_X.shape)
print("Validation Set Shape = ",valid_X.shape)
print("Test Set Shape = ",test_X.shape)

Preprocessing the images for neural net
In a preprocessing step, we preprocess the features (images) into grayscale, normalizing and enhancing them with histogram equalization. After that, convert them to NumPp arrays then reshaping them and data augmentation.
def Prep(img):
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #making image grayscale
img = cv2.equalizeHist(img) #Histogram equalization to enhance contrast
img = img/255 #normalizing
return img
train_X = np.array(list(map(Prep, train_X)))
test_X = np.array(list(map(Prep, test_X)))
valid_X= np.array(list(map(Prep, valid_X)))
#Reshaping the images
train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], train_X.shape[2],1)
test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], test_X.shape[2],1)
valid_X = valid_X.reshape(valid_X.shape[0], valid_X.shape[1], valid_X.shape[2],1)
#Augmentation
datagen = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, zoom_range=0.2, shear_range=0.1, rotation_range=10)
datagen.fit(train_X)
One Hot Encoding
In this section, we are going to use one-hot encoding to labels the classes.
train_y = to_categorical(train_y, data_classes) test_y = to_categorical(test_y, data_classes) valid_y = to_categorical(valid_y, data_classes)
MODEL BUILDING
We are using a convolutional neural network for model building. It consists of the following steps:
#Creating a Neural Network model = Sequential() model.add((Conv2D(60,(5,5),input_shape=(32, 32, 1) ,padding = 'Same' ,activation='relu'))) model.add((Conv2D(60, (5,5),padding="same",activation='relu'))) model.add(MaxPooling2D(pool_size=(2,2))) #model.add(Dropout(0.25)) model.add((Conv2D(30, (3,3),padding="same", activation='relu'))) model.add((Conv2D(30, (3,3), padding="same", activation='relu'))) model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2))) model.add(Dropout(0.5)) model.add(Flatten()) model.add(Dense(500,activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) model.summary()
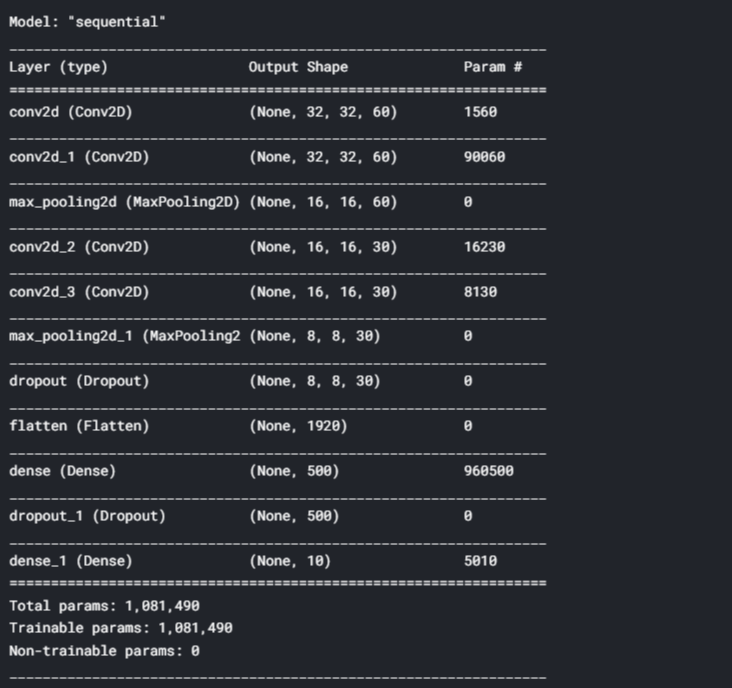
In this step, we are going to compile the model and testing the model on the test set as shown below:
#Compiling the model
optimizer = RMSprop(lr=0.001, rho=0.9, epsilon = 1e-08, decay=0.0)
model.compile(optimizer=optimizer,loss='categorical_crossentropy',metrics=['accuracy'])
#Fit the model
history = model.fit(datagen.flow(train_X, train_y, batch_size=32),
epochs = 30, validation_data = (valid_X, valid_y),
verbose = 2, steps_per_epoch= 200)
# Testing the model on the test set
score = model.evaluate(test_X, test_y, verbose=0)
print('Test Score = ',score[0])
print('Test Accuracy =', score[1])

Part 2: Reading and Detecting the Sudoku From an Image
READING THE SUDOKU PUZZLE
Read a Sudoku using OpenCv using the following code:
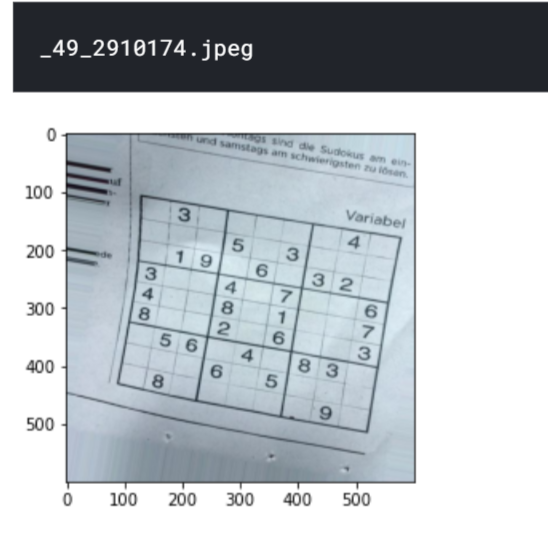
# Randomly select an image from the dataset folder="sudoku-box-detection/aug" a=random.choice(os.listdir(folder)) print(a) sudoku_a = cv2.imread(folder+'/'+a) plt.figure() plt.imshow(sudoku_a) plt.show()
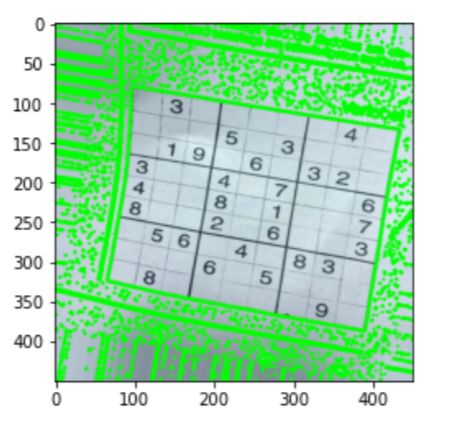
Preprocess the image for further analysis using the below code;
#Preprocessing image to be read
sudoku_a = cv2.resize(sudoku_a, (450,450))
# function to greyscale, blur and change the receptive threshold of image
def preprocess(image):
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (3,3),6)
#blur = cv2.bilateralFilter(gray,9,75,75)
threshold_img = cv2.adaptiveThreshold(blur,255,1,1,11,2)
return threshold_img
threshold = preprocess(sudoku_a)
#let's look at what we have got
plt.figure()
plt.imshow(threshold)
plt.show()
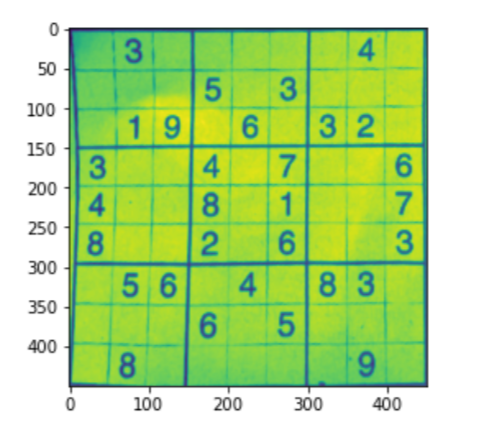
DETECTING CONTOUR
In this section, we are going to detect contour. We sill detect the biggest contour of the image
# Finding the outline of the sudoku puzzle in the image contour_1 = sudoku_a.copy() contour_2 = sudoku_a.copy() contour, hierarchy = cv2.findContours(threshold,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) cv2.drawContours(contour_1, contour,-1,(0,255,0),3) #let's see what we got plt.figure() plt.imshow(contour_1) plt.show()
The following code is used to get the cropped and well-aligned Sudoku by reshaping it.
def main_outline(contour):
biggest = np.array([])
max_area = 0
for i in contour:
area = cv2.contourArea(i)
if area >50:
peri = cv2.arcLength(i, True)
approx = cv2.approxPolyDP(i , 0.02* peri, True)
if area > max_area and len(approx) ==4:
biggest = approx
max_area = area
return biggest ,max_area
def reframe(points):
points = points.reshape((4, 2))
points_new = np.zeros((4,1,2),dtype = np.int32)
add = points.sum(1)
points_new[0] = points[np.argmin(add)]
points_new[3] = points[np.argmax(add)]
diff = np.diff(points, axis =1)
points_new[1] = points[np.argmin(diff)]
points_new[2] = points[np.argmax(diff)]
return points_new
def splitcells(img):
rows = np.vsplit(img,9)
boxes = []
for r in rows:
cols = np.hsplit(r,9)
for box in cols:
boxes.append(box)
return boxes
black_img = np.zeros((450,450,3), np.uint8)
biggest, maxArea = main_outline(contour)
if biggest.size != 0:
biggest = reframe(biggest)
cv2.drawContours(contour_2,biggest,-1, (0,255,0),10)
pts1 = np.float32(biggest)
pts2 = np.float32([[0,0],[450,0],[0,450],[450,450]])
matrix = cv2.getPerspectiveTransform(pts1,pts2)
imagewrap = cv2.warpPerspective(sudoku_a,matrix,(450,450))
imagewrap =cv2.cvtColor(imagewrap, cv2.COLOR_BGR2GRAY)
plt.figure()
plt.imshow(imagewrap)
plt.show()
# Importing puzzle to be solved
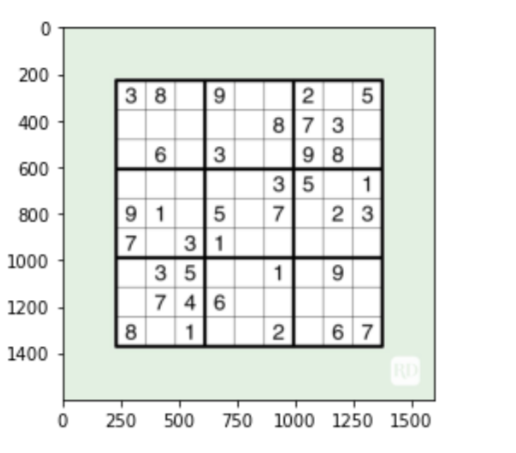
puzzle = cv2.imread("su-puzzle/su.jpg")
#let's see what we got
plt.figure()
plt.imshow(puzzle)
plt.show()
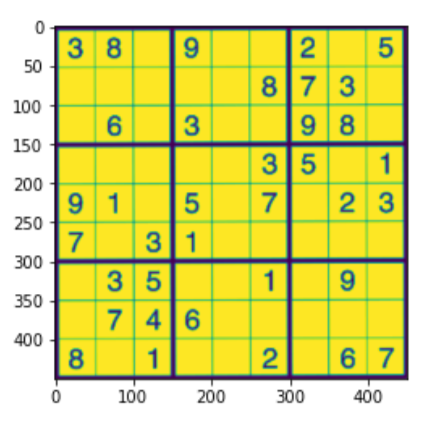
# Finding the outline of the sudoku puzzle in the image su_contour_1= su_puzzle.copy() su_contour_2= sudoku_a.copy() su_contour, hierarchy = cv2.findContours(su_puzzle,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_SIMPLE) cv2.drawContours(su_contour_1, su_contour,-1,(0,255,0),3) black_img = np.zeros((450,450,3), np.uint8) su_biggest, su_maxArea = main_outline(su_contour) if su_biggest.size != 0: su_biggest = reframe(su_biggest) cv2.drawContours(su_contour_2,su_biggest,-1, (0,255,0),10) su_pts1 = np.float32(su_biggest) su_pts2 = np.float32([[0,0],[450,0],[0,450],[450,450]]) su_matrix = cv2.getPerspectiveTransform(su_pts1,su_pts2) su_imagewrap = cv2.warpPerspective(puzzle,su_matrix,(450,450)) su_imagewrap =cv2.cvtColor(su_imagewrap, cv2.COLOR_BGR2GRAY) plt.figure() plt.imshow(su_imagewrap) plt.show()
SPLITTING THE CELLS AND CLASSIFYING DIGITS
In this section, we are going to split the cells and classify the digits
- First split the Sudoku into 81 cells with digits or empty spaces
- Cropping the cells
- Using the model to classify the digits in the cells so that the empty cells are classified as zero
- Finally, detect the output in an array of 81 digits.
sudoku_cell = splitcells(su_imagewrap) #Let's have alook at the last cell plt.figure() plt.imshow(sudoku_cell[58]) plt.show()
def CropCell(cells):
Cells_croped = []
for image in cells:
img = np.array(image)
img = img[4:46, 6:46]
img = Image.fromarray(img)
Cells_croped.append(img)
return Cells_croped
sudoku_cell_croped= CropCell(sudoku_cell)
#Let's have alook at the last cell
plt.figure()
plt.imshow(sudoku_cell_croped[58])
plt.show()
Part3: SOLVING THE SODOKU
In this section, we are going to perform two operations:
- Reshaping the array into a 9 x 9 matrix
- Solving the matrix using recursion
# Reshaping the grid to a 9x9 matrix grid = np.reshape(grid,(9,9)) grid
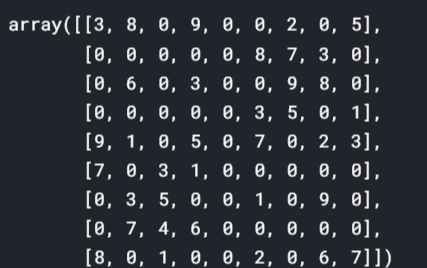
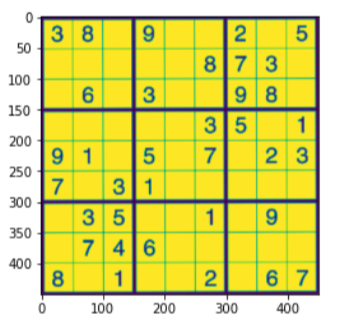
#For compairing plt.figure() plt.imshow(su_imagewrap) plt.show()
Check the below code for further solving the sudoku puzzle:
def next_box(quiz):
for row in range(9):
for col in range(9):
if quiz[row][col] == 0:
return (row, col)
return False
#Function to fill in the possible values by evaluating rows collumns and smaller cells
def possible (quiz,row, col, n):
#global quiz
for i in range (0,9):
if quiz[row][i] == n and row != i:
return False
for i in range (0,9):
if quiz[i][col] == n and col != i:
return False
row0 = (row)//3
col0 = (col)//3
for i in range(row0*3, row0*3 + 3):
for j in range(col0*3, col0*3 + 3):
if quiz[i][j]==n and (i,j) != (row, col):
return False
return True
#Recursion function to loop over untill a valid answer is found.
def solve(quiz):
val = next_box(quiz)
if val is False:
return True
else:
row, col = val
for n in range(1,10): #n is the possible solution
if possible(quiz,row, col, n):
quiz[row][col]=n
if solve(quiz):
return True
else:
quiz[row][col]=0
return
def Solved(quiz):
for row in range(9):
if row % 3 == 0 and row != 0:
print("....................")
for col in range(9):
if col % 3 == 0 and col != 0:
print("|", end=" ")
if col == 8:
print(quiz[row][col])
else:
print(str(quiz[row][col]) + " ", end="")
solve(grid)

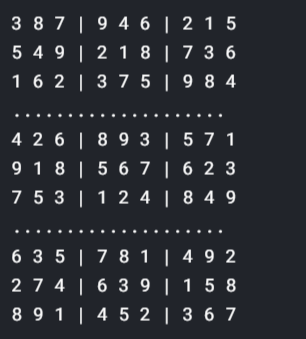
Check the below code for final output:
if solve(grid):
Solved(grid)
else:
print("Solution don't exist. Model misread digits.")
Hurray!! We are done with sudoku solving using deep learning. If you want to learn more, then check the below links:
https://www.youtube.com/watch?v=G_UYXzGuqvM
https://www.kaggle.com/yashchoudhary/deep-sudoku-solver-multiple-approaches
https://www.youtube.com/watch?v=QR66rMS_ZfA
End Notes
So in this article, we had a detailed discussion on Solving Sudoku Using Deep Learning. Hope you learn something from this blog and it will help you in the future. Thanks for reading and your patience. Good luck!
You can check my articles here: Articles
Email id: gakshay1210@gmail.com
Connect with me on LinkedIn: LinkedIn.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







Your article is very interesting.With this we can read the text of a photo and retype the same in a beautiful way. Thank you, Thank you.