Generative Adversarial Networks (GAN) are a somewhat new theory in Machine Learning, proposed for the first time in 2014. Their purpose is to synthesize artificial examples, such as pictures that are obscure from authentic photographs. A typical example of a GAN application is to produce artificial face pictures by learning from a dataset of notable faces.
- While GAN images became further vivid over time, one of their main hurdles is regulating their output, i.e. replacing explicit features such as pose, face shape, and hairstyle in an illustration of a face.
- The Style Generative Adversarial Network, or StyleGAN for short, is an addition to the GAN architecture that introduces significant modifications to the generator model. StyleGAN produces the simulated image sequentially, originating from a simple resolution and enlarging to a huge resolution (1024×1024).
- By transforming the input of each level individually, it examines the visual features that are manifested in that level, from standard features (pose, face shape) to minute details (hair color), without altering other levels.
The resulting model is proficient in producing impressively photorealistic high-quality photos of faces and grants control over the characteristic of the created image at different specification levels by changing the style vectors and noise.
This article was published as a part of the Data Science Blogathon.
What is StyleGAN?
The StyleGAN is a continuation of the progressive, developing GAN that is a proposition for training generator models to synthesize enormous high-quality photographs via the incremental development of both discriminator and generator models from minute to extensive pictures.
- The StyleGAN generator no longer takes a feature from the potential range as input; instead, it uses two new references of randomness to produce a synthetic image: standalone mapping channels and noise layers.
- The production from the mapping network is a vector that defines the techniques integrated at a particular point in the generator model through a new layer called adaptive instance normalization. The advantage of this style vector grants control over the characteristic of the generated image.
- Stochastic variation is proposed through turbulence added at a specific point in the generator model. The noise is affixed to whole feature maps that enable the model to understand the style in a fine-grained, per-pixel manner.
This per-block incorporating style vector and noise provides each block to limit both the understanding of style and the stochastic modification to an addressed level of detail.
StyleGAN Architecture
Style GAN adopted the baseline progressive GAN architecture and suggested some modifications in the generator part of it. However, the discriminator architecture is considerably comparable to baseline progressive GAN. Let us look at specific architectural differences one by one.
- Baseline Progressive Growing GANs : Style GAN uses baseline progressive GAN structure, which means the volume of the generated picture increases progressively from a shallow resolution (4×4) to high resolution (1024 x1024) by adding a new section to both the models to maintain the larger resolution after applying the model on a more modest resolution to make it further stable.
- Bi-linear Sampling: In both generator and discriminator, the scholars of the paper use bi-linear sampling rather than nearest neighbor up/down sampling (practiced in former Baseline Progressive GAN architectures).
- Mapping Network moreover Style Network: The purpose of the mapping network is to produce the latent input vector within the intermediate vector whose distinctive element control various visual features. Instead of immediately implementing latent vector to the input layer, mapping is done.
- Eliminating traditional (Latent) input: The style-GAN writers resolved that the photogeneration characteristics are examined by w and AdaIN. Therefore, they substitute the initial input with the continuous matrix of 4x4x512 to improve the network’s execution.
- Enhancement of Noisy: A Gaussian noise is attached to each activation map before the AdaIN method. A separate sample of noise for each block is evaluated based on the scaling factors of that layer.
- Merging Regularization: The Style generation used an intermediary vector at various levels of the synthesis network, making the network determine the relationship among different levels.
Normalizing Convolutional Inputs
A separate convolutional layer’s input is normalized with adaptive instance normalization (AdaIN) operation using the latent vector “style” embeddings. Lastly, added noise is included in the network to generate more stochastic details in the images. This noise is just a single-channel picture consisting of uncorrelated Gaussian noise. Before each AdaIN operation, noise is supplied at a specific convolutional layer. Additionally, there is a scaling part for the noise, which is decided per feature.

Outcomes
Since the principal objective of the process is disentanglement and interpolation skills of the generative model, a commonly occurring mystery is: what happens with the picture quality and resolution?
Researchers demonstrate that the generator’s radical redesign or compromise produced image quality but considerably enhances it. So, there does not exist a trade-off between picture quality and interpolation skills.

As further participation, researchers provide two new computerized methods for quantification of interpolation quality and disentanglement and a new separate dataset of personal faces.
Tests were carried on both Celeba-HQ and the new dataset called FFHQ. The outcomes show that StyleGAN is superior to old Generative Adversarial Networks, and it reaches state-of-the-art execution in traditional distribution quality metrics. The reports below show the connection of StyleGAN with traditional GAN networks as baselines.
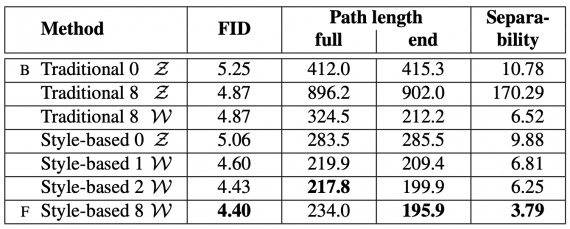
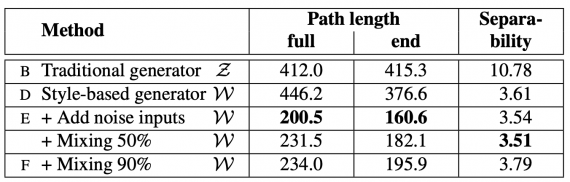
Perceptual path measures and separability records for various generator architectures in FFHQ (lower is better). Estimations are performed in Z for the traditional network and W for style-based ones.

Samples of the new dataset – FFHQ.
Practical Example of StyleGAN
The StyleGAN is adequate at producing large-quality pictures and establishing the style of the created images.
A video validating the model’s skill was published by the paper’s authors, presenting a helpful summary.
Use Cases of StyleGAN
Creating fake faces might not be immediately helpful in a professional connection, but any portion of the means could be. If one can express these elements collectively perfectly, they can describe very complex problems with appreciation.
However, how will this new technology be beneficial beyond standing up to our creativity (which machines have yet to figure out, however)? Results could no longer need models as we will produce them with precise constraints and designs in mind. Extras in films, NPCs in video games can be extra realistic, charming, and diverse. These are just probabilities for a facial generation.
GANs can operate on any dataset of photographs that share connections, and more lately, non-image datasets like text and audio. As a non-human sample, GANs are previously heavily used to generate training data for driverless vehicles. GANs may assist in generating synthetic data to prepare all sorts of patterns where the data is required — which would be an extensive discovery for the field and rush up to additional discovery.
Read about this article how StyleGAN using Transfer learning on a custom dataset !
Conclusion
In this article, we learned the Style Generative Adversarial Network that delivers power over the style of formed synthetic images. StyleGAN is a groundbreaking paper that offers high-quality and realistic pictures and allows for superior control and knowledge of generated photographs, making it even more lenient than before to generate convincing fake images.
The techniques displayed in StyleGAN, particularly the Mapping Network and the Adaptive Normalization (AdaIN), will possibly be the foundation for multiple future discoveries in GANs.
Data Scientist and a Technical Writer! I will give you the best of Open-Source and AI.
Talks about #chatgpt, #opensource, #contentcreation, #communitybuilding, and #artificialintelligence
Technical Writer | Data Science, ML, AI, Open-Source | Do More with Data - Litmus

