This article was published as a part of the Data Science Blogathon.
Introduction
In this article, I have curated a list of 20 Questions on Data Science Concepts consisting of MCQs(One or more correct), True-False, and Integer Type Questions to check your understanding.
Let’s Get Started.
Question Context: 1- 3
Suppose we want to use an automatic classification system to differentiate between COVID-19 negative (Negative class) and Covid-19 positive(Positive class). We have evaluated two pattern classification systems and the data obtained is given below –

1. The number of False Positives(FP) and False Negatives(FN) for both systems respectively are:
(a) System A: FP = 20,FN = 25 ; System B: FP = 15, FN = 30
(b) System A: FP = 15,FN = 30 ; System B: FP = 20, FN = 25
(c) System A: FP = 15,FN = 25 ; System B: FP = 20, FN = 30
(d) System A: FP = 30,FN = 20 ; System B: FP = 15, FN = 25
Answer: [ a ]
Hint: Read the confusion matrix carefully and use basic concepts.
2. The Sensitivity and Specificity for System-A respectively are:
(a) Sensitivity = 0.75, Specificity = 0.80
(b) Sensitivity = 0.70, Specificity = 0.85
(c) Sensitivity = 0.75, Specificity = 0.85
(d) Sensitivity = 0.70, Specificity = 0.80
Answer: [ a ]
Hint: Use the formula to calculate sensitivity and specificity for a given confusion matrix.
3. Which system should we use to rule out the presence of COVID-19?
(a) System-A
(b) System-B
(c) Anyone can be preferred
(d) Can’t be determined
Answer: [ b ]
Explanation: The reason being system B has more specificity than system A.
4. If N is the number of rows/instances in the training dataset, then what is the time complexity of the K- nearest neighbors algorithm run in Big-O notation?
(a) O(1)
(b) O( N )
(c) O( log N )
(d) O( N2 )
Answer: [ b ]
Explanation: K-Nearest neighbors need to compute distances of points to each of the N training instances. Hence, the classification run time complexity is O(N).
5. A company manager wants to predict the time before a break-down of its production machines. As a Machine Learning student, you are asked to solve the problem. How will you formulate it?
(a) as a classification problem statement
(b) as a regression problem statement
(c) as a clustering problem statement
(d) as an association rule-based problem statement
Answer: [ b ]
Explanation: For a regression problem statement our target column is numerical(continuous).
6. Which of the following statements are correct about the Regression line?
(a) The Regression line always goes through the mean of the data.
(b) The sum of the deviation of the values from their regression line is always zero.
(c) The sum of the squared deviation of the values from their regression line is always minimum.
(d) If regression lines coincide with each other, then there is no correlation.
Answer: [ a, b, c ]
Explanation: If regression lines coincide with each other, it shows perfect correlation i.e, r=1.
7. Which of the following options are incorrect about the Mahalanobis distance?
(a) It transforms the columns into correlated variables.
(b) It changes the values of the features so that the standard deviation becomes zero.
(c) It calculates the mean and variance with the help of new columns.
(d) It includes only variances in its formula while calculating the distance
Answer: [a, b, c, d ]
Explanation: Mahalanobis distance takes Covariance into account while calculating distances.
8. Choose the correct options for Random Variables X1 and X2:
(a) If Cov(X1, X2)=0, then the random variables X1 and X2 are independent
(b) If random variables X1 and X2 are independent, then Cov(X1, X2)=0
(c) if Cov(X1, X2)=0 and X1 and X2 are normally distributed, then X1 and X2 are independent.
(d) If Cov(X1, X2)=0, then Corr(X1, X2)=0
Answer: [ b, c, d ]
Explanation: Independence implies zero covariance but zero covariance not necessarily implies Independence.
9. Which of the following statements are TRUE?
(a) Supervised learning does not require target attributes while unsupervised learning requires it.
(b) In a supermarket, categorization of the items to be placed in aisles and on the shelves can be an application of unsupervised learning.
(c) Sentiment analysis can be posed as a classification task, not as a clustering task.
(d) Decision trees can also be used to do clustering tasks.
Answer: [ b, d ]
Explanation: Unsupervised machine learning does not require target attributes while supervised machine learning requires it.
10. The algorithm which can only be used when the training data are linearly separable is:
(a) Linear hard-margin SVM
(b) Linear Logistic Regression
(c) Linear soft-margin SVM
(d) The centroid method
Answer: [ a ]
Explanation: Hard margin SVM can work only when data is completely linearly separable without any errors(outliers/noise). In hard margin SVM, we have very strict constraints to correctly classify data points.
11. Which of the following statements are correct about the Backpropagation Algorithm?
(a) It is also known as the Generalized delta rule
(b) In Backpropagation, error in output is propagated backward only to determine weight updates
(c) Backpropagation learning is based on gradient descent along the surface of the defined loss function.
(d)It is an algorithm for unsupervised learning of artificial neural networks
Answer: [ a, b, c ]
Explanation: Backpropagation algorithm is used for supervised learning of artificial neural networks
12. Integer Answer Type Question:
How many of the following statements are incorrect about the K-Means Clustering algorithm?
(a) In presence of possible outliers in the data, one should not go for ‘complete link’ distance measures during the clustering tasks
(b) Two different runs of k-means clustering algorithms always result in the same clusters
(c) It is always better to assign 10 to 20 iterations as a stopping criterion for k-means clustering
(d) In k-means clustering, the number of centroids change during the algorithm run
(e) It tries to maximize the within class-variance for a given number of clusters.
(f) It converges to the global optimum if and only if the initial means(initialization) is chosen as some of the samples themselves.
(g) It requires the dimension of the feature space to be no bigger than the number of samples.
Answer: [ {b, c, d, e, f, g} – 6 ]
Explanation: The objective of the K-Means clustering algorithm is to minimize total intra-cluster variance(inside clusters). Within-cluster-variance is simple to understand the measure of compactness(compact partitioning).
13. Which of the following statements are correct about the characteristics of Hierarchical clustering?
(a) It is a Merging approach
(b) Measuring distance between two clusters
(c) Divisive hierarchical clustering works in a bottom-up approach
(d) It is a semi-unsupervised clustering algorithm
Answer: [ a, b ]
Explanation: Divisive hierarchical clustering works in a top-down approach.
14. Which of the following statements are correct about Bayesian Classification?
(a) Decision boundary in Bayesian classification depends on evidence
(b) Decision boundary in Bayesian classification depends on priors
(c) Bayes classification is a supervised machine learning algorithm
Answer: [ b, c ]
Explanation: Decision boundary in Bayesian classification doesn’t depend on evidence.
15. Integer Answer Type Question:
How many of the following statements are incorrect about neural networks?
(a) An activation function must be monotonic in neural networks
(b) The logistic function is a monotonically increasing function
(c) A non-differentiable function can not be used as an activation function
(d) They can only be trained with stochastic gradient descent
(e) Optimize a convex objective function.
(f) Can use a mix of different activation functions
Answer: [ {a, c, d, e} – 4 ]
Explanation: Neural networks can use a mix of different activation functions like sigmoid, tanh, and RELU functions.
16. The capacity of a neural network model i.e. the ability of the network to model a complex function _____________ with the increase in drop out rate.
(a) Increases
(b) Decreases
(c) Remain same
(d) First decreases and then increases
Answer: [ b ]
Answer: The capacity of a neural network model decreases with the increase in the dropout rate.
For further reference, refer to the link
Integer Answer Type Question:
17. How many of the following options are TRUE about Support Vector Machines(SVMs)?
(a) Support vectors only have non-zero Lagrangian multipliers in the formulation of SVMs.
(b) SVMs linear discriminant function focuses on a dot product between the test point and the support vectors.
(c) In soft margin SVM, we give freedom to model for some misclassifications.
(d) Support vectors are the data points that are farthest from the decision boundary.
(e) The only training points necessary to compute f(x) in an SVM are support vectors.
Answer: [ {a, b, c, d, e} – 5 ]
Explanation: A support vector machine(SVM) performs classification by choosing the hyperplane that maximizes the margin between the two classes. The vectors that define the Hyperplane are the support vectors and they have non-zero Lagrangian multipliers.
True or False
18. The linear discriminant function(classifier) with the maximum margin in SVMs is the best since it is robust to outliers and has a strong generalization ability.
Answer: [ True ]
Explanation: A support vector machine tries to find the line that “best” separates two classes of points. By “best”, we mean the line that gives the largest margin between the two classes.
19. For the given Dendrogram, if you draw a horizontal line on the y-axis for y=0.50. What will be the number of clusters formed?
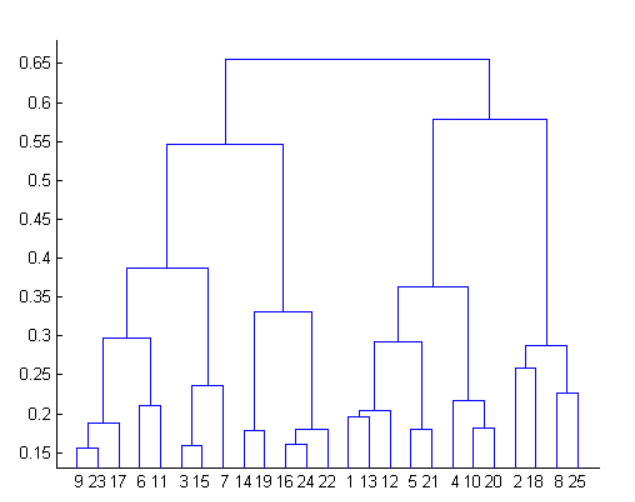
(a) 1 (b) 3 (c) 4 (d) 7
Answer: [ c ]
Hint: Self Explanatory.
20. How do you handle missing values or corrupted data in a dataset for categorical variables?
(a) Drop missing rows or columns
(b) Replace missing value with the most frequent value
(c) Develop a model to predict those missing values
(d) All of the above
Answer: [ d ]
Hint: For reference, refer to the link
End Notes
Thanks for reading!
I hope you enjoyed the questions and were able to test your knowledge about Data Science.
If you liked this and want to know more, go visit my other articles on Data Science and Machine Learning by clicking on the Link
Please feel free to contact me on Linkedin, Email.
Something not mentioned or want to share your thoughts? Feel free to comment below And I’ll get back to you.
About the author
Chirag Goyal
Currently, I pursuing my Bachelor of Technology (B.Tech) in Computer Science and Engineering from the Indian Institute of Technology Jodhpur(IITJ). I am very enthusiastic about Machine learning, Deep Learning, and Artificial Intelligence.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
I am a B.Tech. student (Computer Science major) currently in the pre-final year of my undergrad. My interest lies in the field of Data Science and Machine Learning. I have been pursuing this interest and am eager to work more in these directions. I feel proud to share that I am one of the best students in my class who has a desire to learn many new things in my field.





