This article was published as a part of the Data Science Blogathon
What is Transfer Learning?
One of the most powerful tools in Deep Learning is that sometimes we can take the knowledge or parameters the neural network has learned from one task and apply that knowledge to a different task. So for example maybe we have a neural network model, learned to recognize objects like cats, dogs, and other animals. Then we use that knowledge or use a part of it to do a better job at reading X-ray scans. This is called Transfer Learning. To have a more concrete definition, in transfer learning we reuse a pre-trained model on a new problem. This is particularly so useful because in Deep learning we can train more complex models, with fewer quantities of data using this method. This might come in handy in Data Science because, in most real-world problems, there’s a lack of labeled data points to train such complex models.
Intuition for Transfer Learning

Let’s say you have trained your network on image recognition. So first you take a neural network and train it on XY pairs where X is some image, and Y is some object in the images, say cats or dogs.

Image Source: Deeplearning.Ai
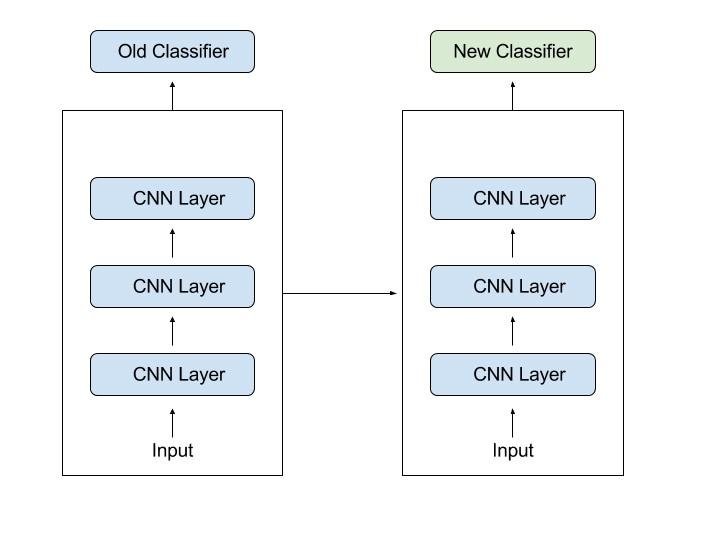
Now let’s say we want to take this neural network and adapt, or as we say “transfer” the learning to a different problem, such as radiology diagnosis. What we can do is take the last output layer of the neural network, sometimes referred to as the “Head” and just delete that, and also delete the weights(parameters) feeding into that removed layer and create a set of new randomly initialized values just for the last layer, which can output radiology diagnosis.
So now we take our new dataset with X’Y’ pair where X’ is our radiology images or X-rays, and Y’ is our diagnosis. We train our model with this new set of data and voila! It works with as much accuracy as it did with the previous dataset.
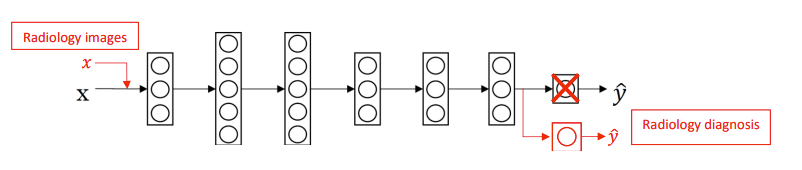
Image Source: DeepLearning.Ai
When Transfer Learning makes sense?
We assume that our model is initially trained for Task A and we want to transfer it to Task B.
- Task A and B have the same type of input i.e If Task A is for image processing, Task B has to be some kind of Image analysis too.
- The amount of data of A should be substantially more than B.
- The Low-level features of A could be helpful for learning the High-level features of B.
MNIST and EfficientNetB0
In this article, we shall work with the popular dataset MNIST (Modified National Institute of Standards and Technology) which is a very popular dataset and is one of the oldest, created in 1998. It is a huge collection of handwritten digits, and commonly used for image processing systems. The dataset contains 60,000 training data and 10,000 test data.
On the other hand, EfficientNetB0 is a convolutional neural network designed by Google and is trained on the ImageNet database. The ImageNet database consists of 14 million images of different categories, all of them annotated by hand.
Since EfficientNetB0 is an already-trained network, in theory, we can perform transfer learning and predict the labels of the data from MNIST with a fair amount of accuracy. Thus in our case, Task A is the image processing of ImageNet data, and Task B is number prediction using the MNIST database.

Image Source: MNIST-Wikipedia
You can find the dataset on Kaggle here. Now let’s start!
Transfer Learning
Library installation and Importing
!pip install efficientnet-pytorch
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) import matplotlib.pyplot as plt import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torch.optim import lr_scheduler from torch.autograd import Variable from torch.utils.data import DataLoader, Dataset from sklearn.metrics import accuracy_score from PIL import Image, ImageOps, ImageEnhance from efficientnet_pytorch import EfficientNet
#parameters BATCH_SIZE = 64 VALID_BATCH_SIZE = 100 TEST_BATCH_SIZE = 100 EPOCHS = 5 NUM_CLASSES = 10 SEED = 42 EARLY_STOPPING = 25 OUTPUT_DIR = '/kaggle/working/' MODEL_NAME = 'efficientnet-b0'
Reading MNIST data
train = pd.<a onclick="parent.postMessage({'referent':'.pandas.read_csv'}, '*')">read_csv('/kaggle/input/digit-recognizer/train.csv') test = pd.<a onclick="parent.postMessage({'referent':'.pandas.read_csv'}, '*')">read_csv('/kaggle/input/digit-recognizer/test.csv') print('Shape of the training data: ', train.shape) print('Shape of the test data: ', test.shape)

sample_df = train.groupby('label').apply(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.[996,1002]'}, '*')">lambda <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.[996,1002]..x'}, '*')">x: <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.[996,1002]..x'}, '*')">x.sample(n=1)).reset_index(drop = True) sample_df.drop(columns=['label'], inplace=True)
nrows = 2 ncols = 5 fig, axs = plt.<a onclick="parent.postMessage({'referent':'.matplotlib.pyplot.subplots'}, '*')">subplots(nrows=nrows, ncols=ncols, gridspec_kw={'wspace': 0.01, 'hspace': 0.05}, squeeze=True, figsize=(10,12)) ind_y = 0 ind_x = 0 for i, row in sample_df.iterrows(): if ind_y > ncols - 1: ind_y = 0 ind_x += 1 sample_digit = sample_df.values[i, :].reshape((28, 28)) axs[ind_x, ind_y].axis('off') axs[ind_x, ind_y].imshow(sample_digit, cmap='gray') axs[ind_x, ind_y].set_title("Digit {}:".format(i)) ind_y += 1 plt.<a onclick="parent.postMessage({'referent':'.matplotlib.pyplot.show'}, '*')">show()

from sklearn.model_selection import train_test_split # Perform train, validation split train_df, valid_df = train_test_split(train, test_size = 0.2, random_state=SEED,stratify=train['label'])
import cv2 # Define custom data loader, # code adapted from https://www.kaggle.com/juiyangchang/cnn-with-pytorch-0-995-accuracy n_pixels = len(train_df.columns) - 1 class MNIST_Dataset(Dataset): """MNIST data set""" def __init__(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self, <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..df'}, '*')">df ): if len(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..df'}, '*')">df.columns) == n_pixels: # test data <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.X = <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..df'}, '*')">df.values.reshape((-1,28,28)).astype(np.<a onclick="parent.postMessage({'referent':'.numpy.uint8'}, '*')">uint8)[:,:,:,<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..None'}, '*')">None] <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.y = <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..None'}, '*')">None <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.X3 = np.<a onclick="parent.postMessage({'referent':'.numpy.full'}, '*')">full((<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.X.shape[0], 3, 28, 28), 0.0) for <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..i'}, '*')">i, <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..s'}, '*')">s in enumerate(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.X): <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.X3[<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..i'}, '*')">i] = np.<a onclick="parent.postMessage({'referent':'.numpy.moveaxis'}, '*')">moveaxis(cv2.<a onclick="parent.postMessage({'referent':'.cv2.cvtColor'}, '*')">cvtColor(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..s'}, '*')">s, cv2.<a onclick="parent.postMessage({'referent':'.cv2.COLOR_GRAY2RGB'}, '*')">COLOR_GRAY2RGB), -1, 0) else: # training/validation data <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.X = <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..df'}, '*')">df.iloc[:,1:].values.reshape((-1,28,28)).astype(np.<a onclick="parent.postMessage({'referent':'.numpy.uint8'}, '*')">uint8)[:,:,:,<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..None'}, '*')">None] <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.y = torch.<a onclick="parent.postMessage({'referent':'.torch.from_numpy'}, '*')">from_numpy(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..df'}, '*')">df.iloc[:,0].values) <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.X3 = np.<a onclick="parent.postMessage({'referent':'.numpy.full'}, '*')">full((<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.X.shape[0], 3, 28, 28), 0.0) for <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..i'}, '*')">i, <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..s'}, '*')">s in <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..enumerate'}, '*')">enumerate(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.X): <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..self'}, '*')">self.X3[<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..i'}, '*')">i] = np.<a onclick="parent.postMessage({'referent':'.numpy.moveaxis'}, '*')">moveaxis(cv2.<a onclick="parent.postMessage({'referent':'.cv2.cvtColor'}, '*')">cvtColor(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__init__..s'}, '*')">s, cv2.<a onclick="parent.postMessage({'referent':'.cv2.COLOR_GRAY2RGB'}, '*')">COLOR_GRAY2RGB), -1, 0) def __len__(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__len__..self'}, '*')">self): return len(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__len__..self'}, '*')">self.X3) def __getitem__(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__getitem__..self'}, '*')">self, <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__getitem__..idx'}, '*')">idx): if <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__getitem__..self'}, '*')">self.y is not None: return <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__getitem__..self'}, '*')">self.X3[<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__getitem__..idx'}, '*')">idx] , <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__getitem__..self'}, '*')">self.y[<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__getitem__..idx'}, '*')">idx] else: return <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__getitem__..self'}, '*')">self.X3[<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.MNIST_Dataset.__getitem__..idx'}, '*')">idx]
train_dataset = MNIST_Dataset(train_df) valid_dataset = MNIST_Dataset(valid_df) test_dataset = MNIST_Dataset(test) train_loader = torch.<a onclick="parent.postMessage({'referent':'.torch.utils'}, '*')">utils.data.DataLoader(dataset=train_dataset, batch_size=BATCH_SIZE, shuffle=True) valid_loader = torch.<a onclick="parent.postMessage({'referent':'.torch.utils'}, '*')">utils.data.DataLoader(dataset=valid_dataset, batch_size=VALID_BATCH_SIZE, shuffle=False) test_loader = torch.<a onclick="parent.postMessage({'referent':'.torch.utils'}, '*')">utils.data.DataLoader(dataset=test_dataset, batch_size=TEST_BATCH_SIZE, shuffle=False)
Transfer learning with EfficientNet architecture
## Load in pretrained effnet model and remove its head, replacing it with fully connected layer ## that gives 10 outputs def get_model(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.get_model..model_name'}, '*')">model_name='efficientnet-b0'): <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.get_model..model'}, '*')">model = EfficientNet.<a onclick="parent.postMessage({'referent':'.efficientnet_pytorch.EfficientNet.from_pretrained'}, '*')">from_pretrained(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.get_model..model_name'}, '*')">model_name) del <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.get_model..model'}, '*')">model._fc # # # use the same head as the baseline notebook. <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.get_model..model'}, '*')">model._fc = nn.<a onclick="parent.postMessage({'referent':'.torch.nn.Linear'}, '*')">Linear(1280, NUM_CLASSES) return <a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.get_model..model'}, '*')">model
As simple as that! we just took the pre-trained model, took off its “Head” and added a new one to fulfill our needs! Now we shall train the model for a few epochs with our new “Head”, and see the results.
import random import os def set_seed(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.set_seed..seed'}, '*')">seed: int = 42): random.seed(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.set_seed..seed'}, '*')">seed) np.<a onclick="parent.postMessage({'referent':'.numpy.random'}, '*')">random.seed(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.set_seed..seed'}, '*')">seed) os.environ["PYTHONHASHSEED"] = str(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.set_seed..seed'}, '*')">seed) torch.<a onclick="parent.postMessage({'referent':'.torch.manual_seed'}, '*')">manual_seed(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.set_seed..seed'}, '*')">seed) torch.<a onclick="parent.postMessage({'referent':'.torch.cuda'}, '*')">cuda.manual_seed(<a onclick="parent.postMessage({'referent':'.kaggle.usercode.11949480.43593611.set_seed..seed'}, '*')">seed) # type: ignore
set_seed(SEED) device = torch.<a onclick="parent.postMessage({'referent':'.torch.device'}, '*')">device('cuda' if torch.cuda.is_available() else 'cpu') output_dir = OUTPUT_DIR model = get_model(MODEL_NAME) model = model.to(device) # # # get optimizer optimizer = optim.<a onclick="parent.postMessage({'referent':'.torch.optim.Adam'}, '*')">Adam(model.parameters(), lr=0.001) # # # get scheduler scheduler = lr_scheduler.<a onclick="parent.postMessage({'referent':'.torch.optim.lr_scheduler.CosineAnnealingLR'}, '*')">CosineAnnealingLR(optimizer, T_max=10) # # # get loss loss_func = nn.<a onclick="parent.postMessage({'referent':'.torch.nn.CrossEntropyLoss'}, '*')">CrossEntropyLoss() if torch.<a onclick="parent.postMessage({'referent':'.torch.cuda'}, '*')">cuda.is_available(): model = model.cuda() loss_func = loss_func.cuda() best_val_accuracy = 0 min_val_loss = np.<a onclick="parent.postMessage({'referent':'.numpy.inf'}, '*')">inf best_epoch = 0 batches = 0 epochs_no_improve = 0 n_epochs_stop = EARLY_STOPPING
for epoch in range(EPOCHS): running_loss = 0.0 targets = torch.<a onclick="parent.postMessage({'referent':'.torch.empty'}, '*')">empty(size=(BATCH_SIZE, )).to(device) outputs = torch.<a onclick="parent.postMessage({'referent':'.torch.empty'}, '*')">empty(size=(BATCH_SIZE, )).to(device) model.train() for batch_idx, (data, target) in enumerate(train_loader): batches += 1 data, target = Variable(data), Variable(target) if torch.<a onclick="parent.postMessage({'referent':'.torch.cuda'}, '*')">cuda.is_available(): data = data.type(torch.<a onclick="parent.postMessage({'referent':'.torch.FloatTensor'}, '*')">FloatTensor).cuda() target = target.cuda() targets = torch.<a onclick="parent.postMessage({'referent':'.torch.cat'}, '*')">cat((targets, target), 0) optimizer.zero_grad() output = model(data) loss = loss_func(output, target) output = torch.<a onclick="parent.postMessage({'referent':'.torch.argmax'}, '*')">argmax(torch.<a onclick="parent.postMessage({'referent':'.torch.softmax'}, '*')">softmax(output, dim=1), dim=1) outputs = torch.<a onclick="parent.postMessage({'referent':'.torch.cat'}, '*')">cat((outputs, output), 0) running_loss += loss.item() loss.backward() optimizer.step() scheduler.step() print('train/loss on EPOCH {}: {}'.format(epoch, running_loss/batches)) train_acc = accuracy_score(targets.cpu().detach().numpy().astype(int), outputs.cpu().detach().numpy().astype(int)) print('train/accuracy: {} for epoch {}'.format(train_acc, epoch))
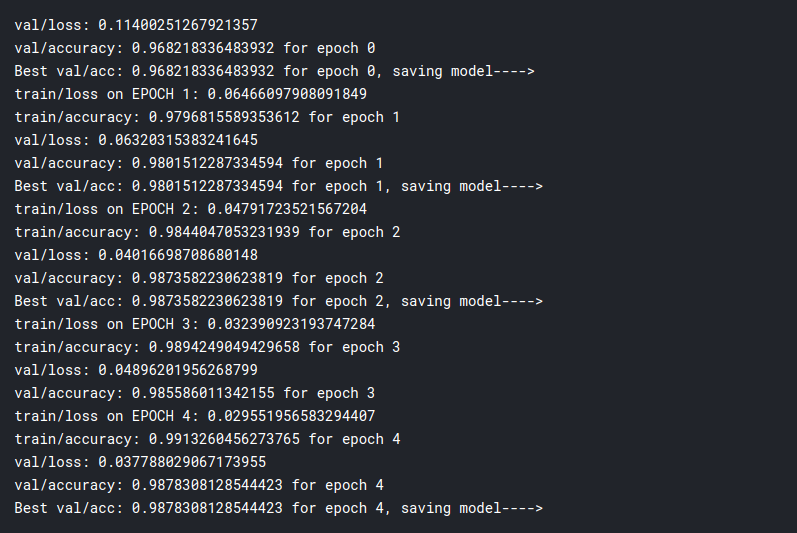
So as you can see, we get an almost 99% accuracy with just 5 epochs!!!!
Conclusion
In this blog, we were introduced to Transfer Learning which is a very important concept of Deep Learning. With Transfer learning, we can reuse an already built model, change the last few layers, and apply it to similar problems and get really accurate results.
Then we proceeded and used the Neural Network architecture developed by google called EfficientNetB0, and used transfer learning to predict the digits from the MNIST dataset and got an accuracy of almost 99%.
The media shown in this article on Transfer Learning using MNIST are not owned by Analytics Vidhya and is used at the Author’s discretion.



how did you train a model on images with one channel? while imagenet weights have been trained on 3 channels images. How to do transfer learning with grayscale images? like images with shape (m, 28, 28, 1)