This article was published as a part of the Data Science Blogathon.
Introduction
Yes, you heard that right, you should avoid using Python lists. Even though they might be arguably the most popular of the Python containers, a Python List has so much more going on behind the curtains. Lists are so popular because of their diverse usage. A list of integers can be created like this:
L = list(range(10))
print(L)
print(type(L[0]))Not just integers, we can create lists with strings too:
L2 = [ str(c) for c in L ] L2[ : 5 ] > [ "0", "1", "2", "3", "4" ] type(L2[0]) > str
Since Python is dynamically typed, we can create mixed lists also:
L3 = [ True, 3, "6", 9.0 ] [ type(ele) for ele in L3 ] > [ bool, int, str, float ]
But all this flexibility does not come for free. First, to understand why we should avoid using lists, we have to look under the hood to see how Python actually works.
Understanding Python Data Types
To become efficient in Data-driven programming and computation requires a deep understanding of how data is stored and manipulated, and as a Data Scientist, this will help you in the long run. More and more programmers are drawn to Python because of its ease of use, one piece of which is Dynamic typing. While in statically typed languages like C++ or Java, all the variables have to be declared explicitly, a dynamically typed language like Python skips this step. Let us take a code snippet in C++ :
int sum = 0 ;
for( int i = 0 ; i <= 100 ; i++ )
sum += i ;
court<< sum ;
> 5050
The same program can be written in Python like:
sum = 0
for i in range(101):
sum += i
print( sum )
> 5050
The main difference we can see here is that in C++, all the variable types have to be explicitly declared, whereas in Python the types are dynamically inferred. Thus we can assign any type of data to any variable. This flexibility points out that a Python variable is more than just a value, it contains extra information about its type. Let’s explore that in the next section.
Why Python Integer is not just an Integer
The Python interpreter is itself written in C, thus all the Python objects are a disguised version of C structures, therefore it contains not only its value but other information as well. For example, if we declare a variable in Python like:
x = 10
x is not just a raw integer, but rather a pointer to a compound C structure containing several values. If we dig deeper, we can find out how this C structure looks like.
struct _longobject {
long ob_refcnt;
PyTypeObject *ob_type;
size_t ob_size;
long ob_digit[1];
};
Thus it contains 4 pieces:
1) ob_refcnt, a reference count which handles allocation and deallocation of memory.
2) ob_type, type of variable.
3) ob_size, size of the data members.
4) ob_digit, the actual value the variable represents.
All this extra information means more overhead charges in terms of memory and computational power. Thus a Python int object is essentially a pointer to a position in memory containing all the information regarding that variable, including the memory bytes which contain the actual integer value. All this extra information is what lets you code in Python soo freely. Not just integers but all the data types in Python comes with this overhead cost, however, this cost becomes significant in structures that combine many of these objects i.e Lists!
Why Python List is not just a List
Now let’s consider what happens when we use a standard Python container, consisting of multiple elements. The standard Python container is a list, much like an Array in C, both are mutable, but as we discussed earlier, Lists can be heterogeneous.
But this flexibility is quite costly. To be heterogeneous, each of the elements of the list must contain its own type info, reference count, and all the other information as well. In other words, each item is a complete Python object.
So if we break it down further, a Python list contains a pointer, which points to another block of pointers, and within that block, all these pointers in turn point to a separate full Python object like the one we saw earlier. This is like one big nesting doll!
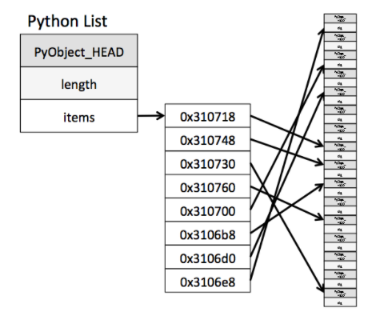
When all the variables are of the same type, much of this information becomes redundant. Won’t it be more efficient to store data like this in a container that does not have such redundancy or not so useful information, and still retain the useful functionalities of lists? Well, the alternatives I’ve got for you are in the next section.
Alternatives for Lists
1) Array
Image Source: GeeksForGeeks
Python has a built-in module named ‘array‘ which is similar to arrays in C or C++. In this container, the data is stored in a contiguous block of memory. Just like arrays in C or C++, these arrays only support one data type at a time, therefore it’s not heterogenous like Python lists. The indexing is similar to lists. The type of the array has to be specified using the typecode provided in the official documentation.
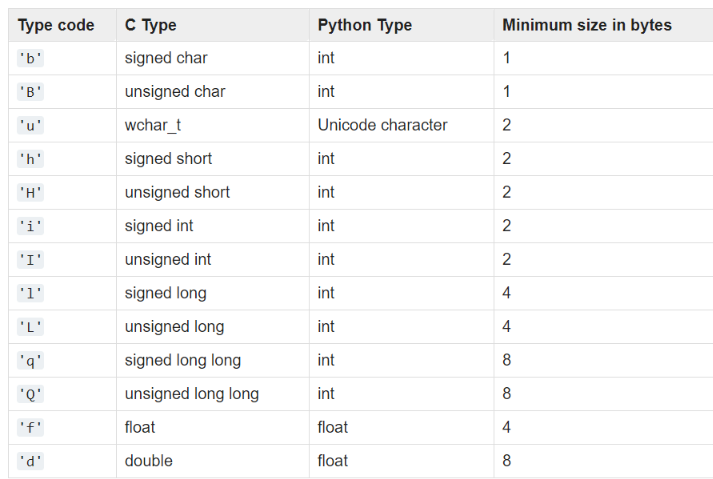
Image source: array
Here is a short tutorial cum examples of using the array module:
from array import array a = array( "l", range(10) ) print( a ) >array( 'l', [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] )
The “l” we used is to specify the typecode of the array we want i.e signed long. Some of the useful methods that can be used with arrays are:
- array.typecode – returns typecode of the array
- array.itemsize – returns length in bytes of one array element.
- array.append(x) – appends a new element x to the right of the array.
- array.count(x) – returns the number of times x occurs in the array.
- array.extend(iterable) – appends all the items to the tight of the array.
There are many more useful operations and methods about which you can read about in the official documentation here.
2) Numpy Arrays
Numpy arrays are even faster than the arrays from the array module. Numpy arrays take up less space than lists since it contains homogenous data. Since the last decade, Python’s popularity increased and thus the need for faster scientific computation was needed. This gave rise to Numpy, which is mainly used for different mathematical calculations. The reasons why NumPy arrays are faster than lists are :
- Numpy arrays are homogenous and contiguous, whereas the lists due to their flexibility need much more space and are not contiguous.
- In NumPy, all the tasks are broken down into small segments and then all these segments are processed parallelly.
- All the NumPy functions and methods are implemented in languages like C, C++, and Fortran, which have very very less execution time than python
Here is a nice comparison of time taken for different operations by Python lists and Numpy arrays:
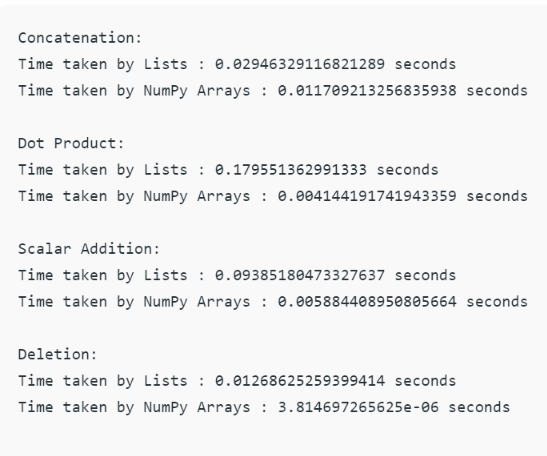
So as you can see, one can side with so much more efficiently in terms of memory usage and speed while using alternatives for Lists like arrays and Numpy arrays. Knowing about these small minuscule details is what separates a great Data scientist from a good Data Scientist. if you are looking to optimize your code further, I would suggest you look into the Python module called Numba. Here is my article about Numba, which can make your Python code run 1000X times faster!! –
I hope you enjoyed reading the blog as much as I enjoyed writing it, and I hope it helps you in your Data Science journey. Cheers!!
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







Very good read!
Helpful article! Thank you!