
Image by National Cancer Institute from Unsplash.
Problem Statement
Breast cancer is the second most frequent cancer in women and men globally. In 2012, it factored about 12 percent of all latest cancer cases and 25 percent of women’s total cancers.
Breast cancer arises when cells in the breast start to develop out of control. These cells usually grow a tumor that can frequently be seen on an x-ray or considered a lump. The tumor is malignant (cancer) if the cells can expand into (invade) encompassing tissues or increase (metastasize) to different sections of the body.
The Hurdle
Construct an algorithm to automatically classify whether a victim is experiencing breast cancer or not by studying biopsy photographs.
Downloading DataSet
The data for the plan can be obtained here. It is a binary classification problem.
We have 277,524 samples with dimensions 50 x 50 (198,738 IDC negative and 78,786 IDC positive)
.png)
Where (a & b) belongs to Benign Samples and (c & d) belongs to Malignant Samples.
Deep Learning To Rescue
#1.Input
Input is a matrix of pixel values in the configuration of [WIDTH, HEIGHT, CHANNELS].
#2.Convolution Layer
The objective of this layer is to sustain a feature map. Typically, we commence with a base estimate of filters for low-level feature detection. The more distant we go within CNN, the added filters we use to identify high-level features. Feature detection is based on ‘examining’ the input with a presented dimension filter and implementing matrix computations to infer a feature map.
#3.Pooling Layer
This layer aims to implement spatial variance, which means that the system will be proficient in identifying an object even when its appearance differs somehow. The pooling layer will do a downsampling procedure accompanying the spatial dimensions (width, height), resulting in the product such as [16x16x12] for pooling_size=(2, 2).
#4.Fully Connected Layer
In a fully connected layer, we flatten the product of the end convolution layer and combine every node of the prevailing layer with the separate nodes of the subsequent layer.
Implementation
First, we load all the libraries and packages.

Next, I loaded the pictures in the corresponding directory.

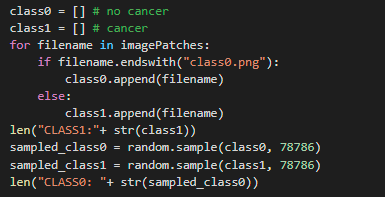
Then we create two arrays holding images for each class type.
Output:
Class1: 78786
Class0: 78786
Preprocess that images into an array of size (3, 50, 50)

Load the test image

Output: (50, 50, 3)
Combine the data and shuffle for training purposes.

Output: <string>:6: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify ‘dtype=object’ when creating the ndarray
Differentiate labels and features in the combined data and append them to a separate list. Then reshape the list holding the elements into a shape accepted by the Neural Network.

Output: (157572, 50, 50, 3)
Split the dataset into training(75%) and testing(25%) using the train_test_split() method and apply the to_categorical() method to transform your data before you pass it to your deep learning model for training. It converts the classes into a set of numbers in proper vector form for compatibility with the models. It is mainly done in classification problems.

Output: (118179, 50, 50, 3) (39393, 50, 50, 3) (118179, 2) (39393, 2)
Define the architecture of the model to training the model. I adopted a batch size equivalent of 20 and also training the model for 20 epochs. Batch size is an example of the most fundamental hyperparameters to harmonize in deep learning. I fancy using a larger batch size to train my models as it concedes computational speedups from the affinity of GPUs. However, it is well comprehended that too high of a batch size will commence to lousy generalization.
On the opposite deal, accepting smaller batch sizes has given faster convergence to great results. Smaller batch sizes enable the model to begin learning before recognizing all the data.

.png)
- The learning rate is determined to be 0.0001.
- Applying Dense layer with two neurons for two output classes in our case, which is benign and malignant, with activation function as softmax.
- I am using Adam optimizer for optimization and binary-cross-entropy for the loss function.
Performance Metrics
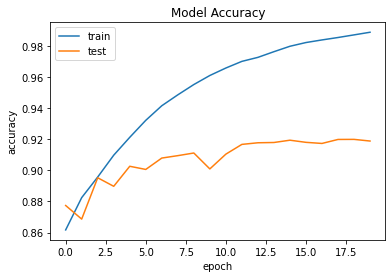
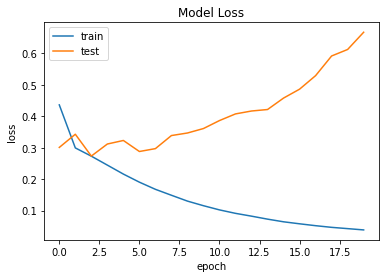
The most popular metric for assessing model performance is accuracy and loss plot. We achieved an accuracy of 98.87%, but let us determine if we overtrained the model by mistake by looking at the Model accuracy and model loss plot.

Why are we using Deep Learning For Breast Cancer Classification?
Convolutional Neural Network (CNN) has been introduced as an extraordinary class of models for image recognition issues. CNN is a deep learning model that derives an image’s features and practices these features to analyze an image.
Other classification algorithm demands to remove the element of an illustration applying feature extraction algorithm. In our study, we have two groups which we need to classify 1.benign and 2.malignant.
We disengage the patches of the picture from training the network and finally giving the shot as an input to analyze the picture. The achievement of CNN is much more reliable when associated with other published results on diverse datasets using different classification algorithms for classifying an image.
Conclusions
It is extraordinary to witness the completion of deep learning in such diverse real-world difficulties. This post explained how to distinguish benign and malignant breast cancer from a combination of small images using Deep Learning and Python for coding.
I hope you noticed my article both exciting and relevant. Please feel open to comment below, and you can also connect with me on my social media: MEDIUM LINKEDIN GITHUB.
The media shown in this article on Sign Language Recognition are not owned by Analytics Vidhya and are used at the Author’s discretion.
Data Scientist and a Technical Writer! I will give you the best of Open-Source and AI.
Talks about #chatgpt, #opensource, #contentcreation, #communitybuilding, and #artificialintelligence
Technical Writer | Data Science, ML, AI, Open-Source | Do More with Data - Litmus





what is the platform used here to run the code? Like I'm using google colab but I'm getting lot of errors...so I just want to know the exact platform Could you please help me?