This article was published as a part of the Data Science Blogathon
Introduction:
Image classification has been the coolest topic of 21 century. Its goal is to classify the image with the correct label. We can do image classification by Convolution Neural Network. And it’s not that hard to do image classification. You just need to learn some libraries like Tensorflow, Keras, PyTorch. But sometimes you will face this type of question in interviews like, how can you solve an image classification problem using Support Vector Machine(SVM)? And here in this article, I am going to discuss this.
Table of Contents:
1. What is SVM?
2. Importing necessary Libraries
3. Data Augmentation
4. Model Creation
5. Compile Model
6. What we need to do to convert a CNN into an SVM image classifier
7. Model Training
What is SVM?
Generally, Support Vector Machines(SVM) is considered to be a classification approach but it can be employed in both types of classification and regression problems. It can easily handle multiple continuous and categorical variables. SVM constructs a hyperplane in multidimensional space to separate different classes. SVM generates optimal hyperplane in an iterative manner, which is used to minimize an error. The core idea of SVM is to find a maximum marginal hyperplane(MMH) that best divides the dataset into classes.
.png)
SVM is a very good algorithm for doing classification. It’s a supervised learning algorithm that is mainly used to classify data into different classes. SVM trains on a set of label data. The main advantage of SVM is that it can be used for both classification and regression problems. SVM draws a decision boundary which is a hyperplane between any two classes in order to separate them or classify them. SVM also used in Object Detection and image classification.
Here, I am going to use the Cats & Dogs dataset for doing Classification using SVM. You can collect the dataset from here. It’s a binary classification problem, but Support Vector Machine can also be used for multiclass classification problems.
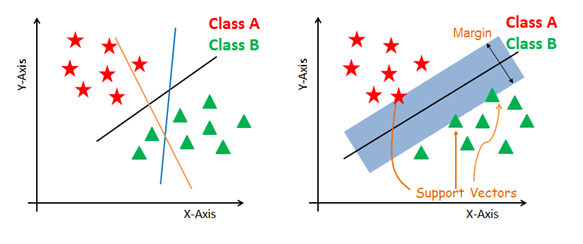
Support Vectors
Support vectors are the data points, which are closest to the hyperplane. These points will define the separating line better by calculating margins. These points are more relevant to the construction of the classifier.
Hyperplane
A hyperplane is a decision plane that separates between a set of objects having different class memberships.
Margin
A margin is a gap between the two lines on the closest class points. This is calculated as the perpendicular distance from the line to support vectors or closest points. If the margin is larger in between the classes, then it is considered a good margin, a smaller margin is a bad margin.
How does SVM work?
The main objective is to segregate the given dataset in the best possible way. The distance between the either nearest points is known as the margin. The objective is to select a hyperplane with the maximum possible margin between support vectors in the given dataset. SVM searches for the maximum marginal hyperplane in the following steps:
- Generate hyperplanes that segregate the classes in the best way. Left-hand side figure showing three hyperplanes black, blue, and orange. Here, the blue and orange have higher classification errors, but the black is separating the two classes correctly.
- Select the right hyperplane with the maximum segregation from the either nearest data points as shown in the right-hand side figure.
To know about SVM, more precisely check out this article.
Now, Let’s head to our main point.
Let’s import the necessary libraries:
- import numpy as np
- import pandas as pd
- import tensorflow as tf
- from tensorflow.keras.preprocessing.image import ImageDataGenerator
- from tensorflow.keras import Sequential
- from tensorflow.keras.layers import Conv2D,Dense,MaxPool2D,Flatten
- from tensorflow.keras.regularizers import l2
We’ll do Data Augmentation here:
- train_dir = “dataset/training_set/”
- test_dir = “dataset/test_set/”
-
train_datagen = ImageDataGenerator(rescale=(1/255.),shear_range = 0.2,zoom_range=0.2, horizontal_flip=True) training_set = train_datagen.flow_from_directory(directory = train_dir,target_size=(64,64), batch_size=32, class_mode = "binary") test_datagen = ImageDataGenerator(rescale=(1/255.)) test_set = test_datagen.flow_from_directory(directory = test_dir,target_size=(64,64), batch_size=32, class_mode = "binary")
We did data Augmentation here so that we can create additional data in the memory.

Model Creation:
model = Sequential() model.add(Conv2D(filters = 32, padding = "same",activation = "relu",kernel_size=3, strides = 2,input_shape=(64,64,3))) model.add(MaxPool2D(pool_size=(2,2),strides = 2)) model.add(Conv2D(filters = 32, padding = "same",activation = "relu",kernel_size=3)) model.add(MaxPool2D(pool_size=(2,2),strides = 2)) model.add(Flatten()) model.add(Dense(128,activation="relu")) #Output layer model.add(Dense(1,kernel_regularizer=l2(0.01),activation = "linear"))
In a normal CNN, at output layer we’ll write: model.add(Dense(1,activation = “sigmoid”))
But if we want to convert this into SVM what we’ll do is, there’s a parameter called “kernel_regularizer” and inside this regularizer, we have to use l1 or l2 norm, here I am using l2 norm and pass linear as activation function and that’s what we did in the final output layer above in the model creation section. Because when we use Support Vector Machine for binary classification we use something called LinearSVM. Linear SVM means we’ll try to draw a line between them & we’ll try to find out other margin lines & then we’ll try to divide the particular classes. For multiclass classification, we’ve to use softmax as an activation function for SVM.
Compile:
During compiling we’ve to use hinge as a loss function.
- model.compile(optimizer = ‘adam’, loss = “hinge”, metrics = [‘accuracy’])
If our problem was a Multiclass classification problem then we’ve to use squared_hinge as loss function & softmax as activation function during compiling for SVM. Like this:
- model.add(Dense(number_of_classes,kernel_regularizers = l2(0.01),activation= “softmax”))
- model.compile(optimizer=”adam”,loss=”squared_hinge”, metrics = [‘accuracy’])
What do we need to do to convert a CNN into an SVM image classifier?
So, to do image classification using SVM we need to apply 2 changes:
i. Apply loss = “hinge” for binary & “squared_hinge” for multi class classification.
ii. Apply regularizer in the final output layer & apply activation = “linear” for binary & “softmax” for multiclass classification.
Let’s now train our model:
- history = model.fit(x = training_set, validation_data = test_set, epochs=15)
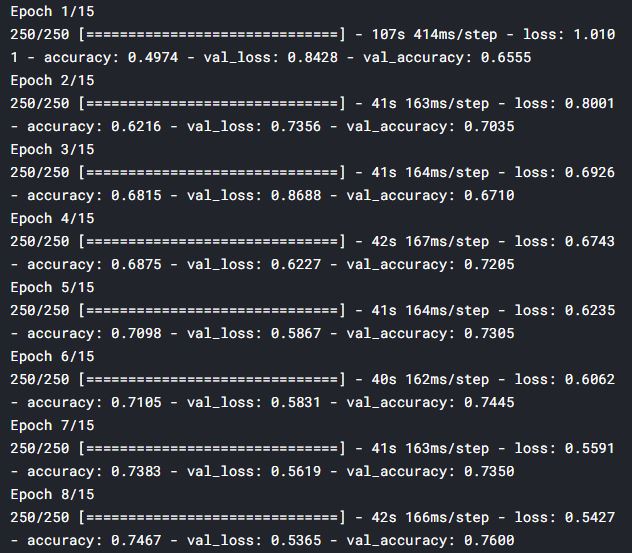
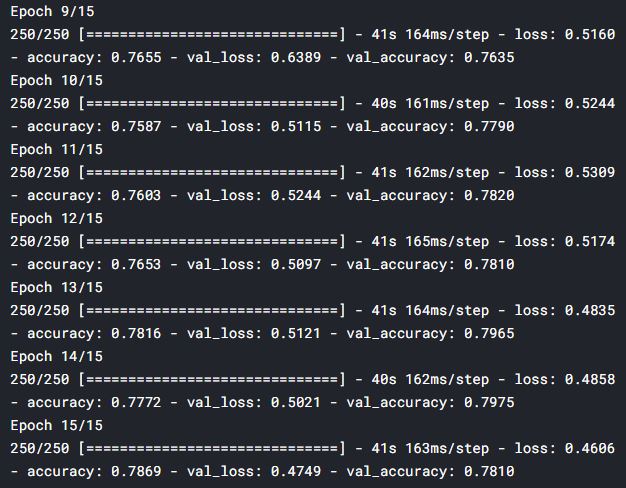
Here I just created a simple model, you can increase the accuracy by making some changes in the model like increasing the number of layers, applying some regularization techniques like Dropout, MaxPool2D, etc. You can find the whole code here.
And there it is!! It’s really simple to apply SVM for image classification. You can use it easily for creating your image classification model. So, go ahead and create your image classification model using SVM. And this completes today’s discussion.
Endnotes:
I hope you enjoyed the article. If you have anything to know related to the article, feel free to ask me in the comment section.
About me:
Currently, I am pursuing my bachelor’s in Computer Science, and I am very enthusiastic about Machine Learning, Deep Learning, and Data Science.
The media shown in this article on Deploying Machine Learning Models leveraging CherryPy and Docker are not owned by Analytics Vidhya and are used at the Author’s discretion.

