This article was published as a part of the Data Science Blogathon
Introduction
Deep learning architecture is rapidly gaining steam as more and more efficient architectures emerge from research papers emerge from around the world. These research papers not only contain a ton of information but also provide a new way to the birth of new Deep learning architectures, they can often be difficult to parse through. And to understand these papers, one might have to go through that paper multiple times and perhaps even other dependent papers. Well! Inception is one of them.
The Inception network was a crucial milestone in the development of CNN Image classifiers. Prior to this architecture, most popular CNNs or the classifiers just used stacked convolution layers deeper and deeper to obtain better performance.
The Inception network, on the other hand, was heavily engineered and very much deep and complex. It used many different techniques to push its performance; both in terms of speed as well as accuracy.
What is Inception?
Inception Network (ResNet) is one of the well-known deep learning models that was introduced by Christian Szegedy, Wei Liu, Yangqing Jia. Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich in their paper “Going deeper with convolutions” [1] in 2014.
Later the different versions of the Inception network are evolved. That was from Sergey Ioffe, Christian Szegedy, Jonathon Shlens, Vincent Vanhouck, and Zbigniew Wojna in their paper named “Rethinking the Inception Architecture for Computer Vision” [2] in 2015. The Inception model is categorized as one of the popular and most used deep learning models.
Design Principles
– The proposal of few general design principles and optimization techniques proved to be useful for efficiently scaling up convolution networks.
– Early in the network architecture, avoid representational bottlenecks.
– The network will learn faster if it has more different filters which will have more different feature maps.
– Spatial aggregation that is dimension reduction can be done over lower dimensional embeddings without much loss in representational power.
– With the balance between width and depth, optimal performance of the network can be achieved.
Inception Modules
Inception Module (naive)
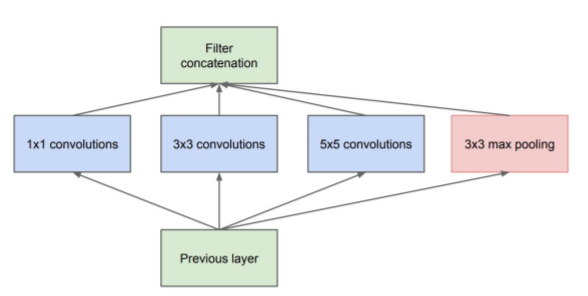
Source: ‘Going Deeper with Convolution‘ paper
Approximation of an optimal local sparse structure
● Process visual/spatial information at various scales and then aggregate
● This is a bit optimistic, computationally
○ 5×5 convolutions are especially expensive
Inception Module (Dimension reduction)
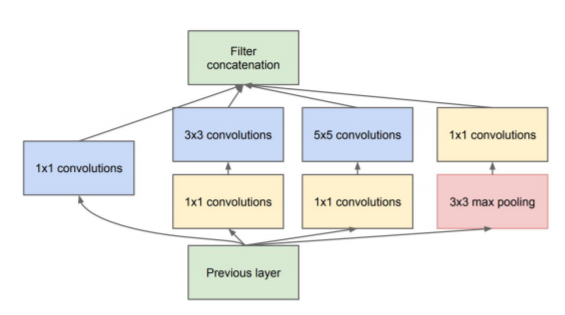
Source: ‘Going Deeper with Convolution’ paper
Dimension reduction is necessary and motivated (Network in-network)
● Achieved with 1×1 convolutions
○ Think learned pooling in-depth instead of max/average pooling in height/width.
Inception architecture:
Using the inception module that is dimension-reduced inception module, a deep neural network architecture was built (Inception v1). The architecture is shown below:
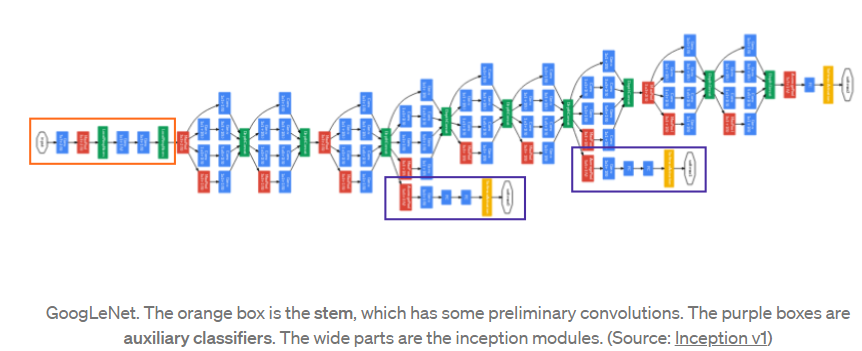
Inception network has linearly stacked 9 such inception modules. It is 22 layers deep (27, if include the pooling layers). At the end of the last inception module, it uses global average pooling.
· For dimension reduction and rectified linear activation, a 1×1 convolution with 128 filters are used.
· Rectified linear activation with a fully connected layer with 1024 units.
· 70% ratio of dropped outputs using a dropout layer.
· A softmax loss with linear layer as the classifier.
The popular versions of the Inception network are as follows:
· Inception v1.
· Inception v2
· Inception v3.
· Inception v4
· Inception-ResNet.
Let’s Build Inception v1(GoogLeNet) from scratch:
Inception architecture uses the CNN blocks multiple times with different filters like 1×1, 3×3, 5×5, etc., so let us create a class for CNN block, which takes input channels and output channels along with batchnorm2d and ReLu activation.
class conv_block(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(conv_block, self).__init__()
self.relu = nn.ReLU()
self.conv = nn.Conv2d(in_channels, out_channels, **kwargs)
self.batchnorm = nn.BatchNorm2d(out_channels)
def forward(self, x):
return self.relu(self.batchnorm(self.conv(x)))
Then create a class for inception module with dimension reduction, refer the figure above, which shows that is output from 1×1 filter, reduction 3×3, then output from 3×3 filter, reduction 5×5, then output from 5×5 and the out from 1×1 pool.
class Inception_block(nn.Module):
def __init__(
self, in_channels, out_1x1, red_3x3, out_3x3, red_5x5, out_5x5, out_1x1pool
):
super(Inception_block, self).__init__()
self.branch1 = conv_block(in_channels, out_1x1, kernel_size=(1, 1))
self.branch2 = nn.Sequential(
conv_block(in_channels, red_3x3, kernel_size=(1, 1)),
conv_block(red_3x3, out_3x3, kernel_size=(3, 3), padding=(1, 1)),
)
self.branch3 = nn.Sequential(
conv_block(in_channels, red_5x5, kernel_size=(1, 1)),
conv_block(red_5x5, out_5x5, kernel_size=(5, 5), padding=(2, 2)),
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
conv_block(in_channels, out_1x1pool, kernel_size=(1, 1)),
)
def forward(self, x):
return torch.cat(
[self.branch1(x), self.branch2(x), self.branch3(x), self.branch4(x)], 1
)
Let us keep the below image as a reference and start building the network.
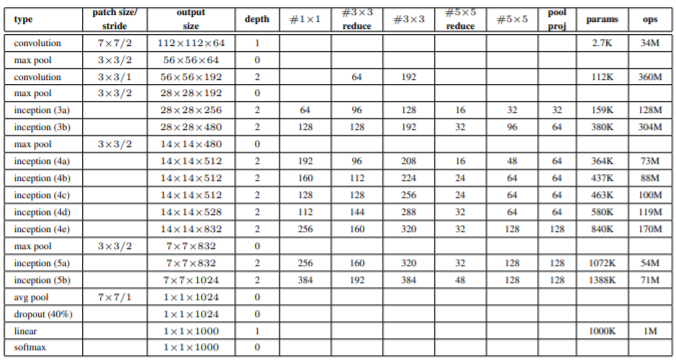
Source: ‘Going Deeper with Convolution’ paper
Create a class as GoogLeNet
class GoogLeNet(nn.Module):
def __init__(self, aux_logits=True, num_classes=1000):
super(GoogLeNet, self).__init__()
assert aux_logits == True or aux_logits == False
self.aux_logits = aux_logits
# Write in_channels, etc, all explicit in self.conv1, rest will write to
# make everything as compact as possible, kernel_size=3 instead of (3,3)
self.conv1 = conv_block(
in_channels=3,
out_channels=64,
kernel_size=(7, 7),
stride=(2, 2),
padding=(3, 3),
)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv2 = conv_block(64, 192, kernel_size=3, stride=1, padding=1)
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# In this order: in_channels, out_1x1, red_3x3, out_3x3, red_5x5, out_5x5, out_1x1pool
self.inception3a = Inception_block(192, 64, 96, 128, 16, 32, 32)
self.inception3b = Inception_block(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(kernel_size=(3, 3), stride=2, padding=1)
self.inception4a = Inception_block(480, 192, 96, 208, 16, 48, 64)
self.inception4b = Inception_block(512, 160, 112, 224, 24, 64, 64)
self.inception4c = Inception_block(512, 128, 128, 256, 24, 64, 64)
self.inception4d = Inception_block(512, 112, 144, 288, 32, 64, 64)
self.inception4e = Inception_block(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.inception5a = Inception_block(832, 256, 160, 320, 32, 128, 128)
self.inception5b = Inception_block(832, 384, 192, 384, 48, 128, 128)
self.avgpool = nn.AvgPool2d(kernel_size=7, stride=1)
self.dropout = nn.Dropout(p=0.4)
self.fc1 = nn.Linear(1024, num_classes)
if self.aux_logits:
self.aux1 = InceptionAux(512, num_classes)
self.aux2 = InceptionAux(528, num_classes)
else:
self.aux1 = self.aux2 = None
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
# x = self.conv3(x)
x = self.maxpool2(x)
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
x = self.inception4a(x)
# Auxiliary Softmax classifier 1
if self.aux_logits and self.training:
aux1 = self.aux1(x)
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
# Auxiliary Softmax classifier 2
if self.aux_logits and self.training:
aux2 = self.aux2(x)
x = self.inception4e(x)
x = self.maxpool4(x)
x = self.inception5a(x)
x = self.inception5b(x)
x = self.avgpool(x)
x = x.reshape(x.shape[0], -1)
x = self.dropout(x)
x = self.fc1(x)
if self.aux_logits and self.training:
return aux1, aux2, x
else:
return x
Then define a class for the output layer that is with dropout=0.7 as mentioned in the paper and a linear layer with softmax to output n_classes.
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=0.7)
self.pool = nn.AvgPool2d(kernel_size=5, stride=3)
self.conv = conv_block(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.pool(x)
x = self.conv(x)
x = x.reshape(x.shape[0], -1)
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
Then the program should be aligned as shown below.
– Class GoogLeNet
– Class Inception_block
– Class InceptionAux
– Class conv_block
Then at the end let us write a small piece of test code to check if our model is working fine.
if __name__ == "__main__":
# N = 3 (Mini batch size)
x = torch.randn(3, 3, 224, 224)
model = GoogLeNet(aux_logits=True, num_classes=1000)
print(model(x)[2].shape)
The output should be as shown below

The entire code can be accessed here:
[1]. Christian Szegedy, Wei Liu, Yangqing Jia. Pierre Sermanet, Scott Reed, Dragomir
Anguelov, Dumitru Erhan, Vincent Vanhoucke and Andrew Rabinovich: Going deeper with convolutions, Sep 2014, DOI: https://arxiv.org/pdf/1409.4842v1.pdf
[2]. Sergey Ioffe , Christian Szegedy, Jonathon Shlens, Vincent Vanhouck and Zbigniew
Wojna: Rethinking the Inception Architecture for Computer
Vision, Dec 2015, DOI:https://arxiv.org/pdf/1512.00567.pdf
Thank you
The media shown in this article on Sign Language Recognition are not owned by Analytics Vidhya and are used at the Author’s discretion.
I thrive on the thrill of the challenge, tackling complex problems and crafting innovative AI solutions that make a difference. Whether it's optimizing or building sustainable AI ecosystems, I believe in harnessing the power of AI for the greater good. Let's brainstorm, collaborate, and change the world, one byte at a time.


