In Neural Networks, we have the concept of Loss Functions, which tell us about the performance of our neural networks, i.e., at the current instant, how good or poor the model is performing. Now, to train our network to perform better on unseen datasets, we need to use loss. We aim to minimize the loss, as a lower loss implies that our model will perform better. So, Optimization means minimizing (or maximizing) any mathematical expression. In this article, we’ll explore and deep dive into the world of gradient-based optimizers for deep learning models. We will also discuss the foundational mathematics behind these optimizers and their advantages and disadvantages.
Overview:
- Define loss functions in neural networks, explaining their role in measuring model performance and how optimization aims to minimize these functions.
- Explain the mathematical concepts behind gradient-based optimization and how these optimizers navigate the “terrain” of the loss function to reach a global minimum.
- Differentiate between Batch Gradient Descent, Stochastic Gradient Descent (SGD), and Mini-Batch Gradient Descent, covering their mechanics and how they update model parameters.
- Describe how gradients indicate a direction for optimization and the importance of setting an appropriate learning rate to ensure effective and efficient convergence.
- Explore the strengths and limitations of each method (e.g., stability vs. speed) and how these impact deep learning model training, especially for large datasets.
- Identify common challenges, such as getting stuck in local minima, choosing an optimal learning rate, and managing memory constraints that affect all gradient-based optimizers.
- Showcase practical applications of these optimizers in deep learning, highlighting typical code implementations and best practices for real-world data science and machine learning tasks.
This article was published as a part of the Data Science Blogathon
Table of contents
Role of an Optimizer
As discussed in the introduction, Optimizers update the parameters of neural networks, such as weights and learning rate, to minimize the loss function. Here, the loss function guides the terrain, telling the optimizer if it is moving in the right direction to reach the bottom of the valley, the global minimum.
The Intuition Behind Optimizers with an Example
Let us imagine a climber hiking down the hill with no direction. He doesn’t know the right way to reach the valley in the hills, but he can understand whether he is moving closer (going downhill) or further away (uphill) from his final destination. If he keeps taking steps in the correct direction, he will reach his aim i.,e the valley
This is the intuition behind optimizers- to reach a global minimum concerning the loss function.
Instances of Gradient-Based Optimizers
Different instances of Gradient descent Optimizers are as follows:
- Batch Gradient Descent or Vanilla Gradient Descent or Gradient Descent (GD)
- Stochastic Gradient Descent (SGD)
- Mini batch Gradient Descent (MB-GD)
Batch Gradient Descent
Gradient descent is an optimization algorithm used when training deep learning models. It’s based on a convex function and updates its parameters iteratively to minimize a given function to its local minimum.

The notation used in the above Formula is given below,
In the above formula,
- α is the learning rate,
- J is the cost function, and
- ϴ is the parameter to be updated.
As you can see, the gradient represents the partial derivative of J(cost function) with respect to ϴj
Note that as we reach closer to the global minima, the slope or the gradient of the curve becomes less and less steep, which results in a smaller value of the derivative, which in turn reduces the step size or learning rate automatically.
It is the most basic but most used optimizer that directly uses the derivative of the loss function and learning rate to reduce the loss function and tries to reach the global minimum.
Thus, the Gradient Descent Optimization algorithm has many applications including:
- Linear Regression,
- Classification Algorithms,
- Backpropagation in Neural Networks, etc.

The above-described equation calculates the gradient of the cost function J(θ) with respect to the network parameters θ for the entire training dataset:
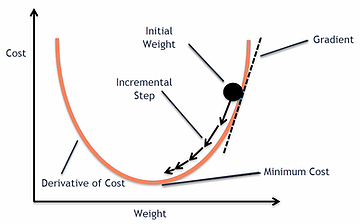
Our aim is to reach the bottom of the graph(Cost vs. weight) or to a point where we can no longer move downhill–a local minimum.
Role of Gradient
In general, a Gradient represents the slope of the equation, while gradients are partial derivatives. They describe the change reflected in the loss function with respect to the small change in the function’s parameters. This slight change in loss functions can tell us about the next step to reduce the loss function’s output.
Role of Learning Rate
The learning rate represents our optimisation algorithm’s steps to reach the global minima. To ensure that the gradient descent algorithm reaches the local minimum, we must set the learning rate to an appropriate value that is neither too low nor too high.
Taking very large steps, i.e., a large learning rate value, may skip the global minima, and the model will never reach the optimal value for the loss function. On the contrary, taking very small steps, i.e., a small learning rate value, will take forever to converge.
Thus, the step size also depends on the gradient value.
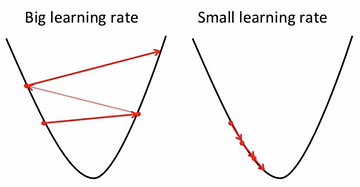
As we discussed, the gradient represents the direction of increase. However, we aim to find the minimum point in the valley, so we have to go in the opposite direction of the gradient. Therefore, we update parameters in the negative gradient direction to minimize the loss.
Algorithm: θ=θ−α⋅∇J(θ)In code, Batch Gradient Descent looks something like this:
for x in range(epochs):
params_gradient = find_gradient(loss_function, data, parameters)
parameters = parameters - learning_rate * params_gradientAdvantages of Batch Gradient Descent
- Efficient Computation: By processing the entire dataset in one go, batch gradient descent efficiently computes gradients, especially with matrix operations, optimizing performance on large datasets.
- Simple Implementation: The straightforward approach of calculating gradients on all data points makes batch gradient descent easy to code, especially with frameworks like TensorFlow and PyTorch.
- Enhanced Convergence Stability: With gradients computed over the full dataset, batch gradient descent offers a smoother path to convergence, reducing fluctuations in updates and aiding in reliable model training.
Disadvantages of Batch Gradient Descent
- Susceptible to Local Minima: Batch gradient descent may get stuck in local minima, limiting optimization effectiveness in non-convex loss surfaces.
- Slow Convergence on Large Datasets: Since weights are updated after processing the entire dataset, convergence can be extremely slow for large datasets, delaying training.
- High Memory Demand: Calculating gradients on the entire dataset requires substantial memory, making it challenging to implement on limited-memory systems or massive datasets.
Stochastic Gradient Descent
To overcome some of the disadvantages of the GD algorithm, the SGD algorithm comes into the picture as an extension of the Gradient Descent. One of the disadvantages of the Gradient Descent algorithm is that it requires a lot of memory to load the entire dataset at a time to compute the derivative of the loss function. So, In the SGD algorithm, we compute the derivative by taking one data point at a time, i.e., try to update the model’s parameters more frequently. Therefore, the model parameters are updated after the loss computation on each training example.
So, let’s have a dataset that contains 1000 rows, and when we apply SGD, it will update the model parameters 1000 times in one complete cycle of a dataset instead of one time as in Gradient Descent.
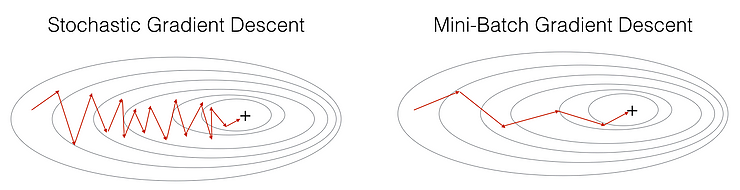
Algorithm: θ=θ−α⋅∇J(θ;x(i);y(i)) , where {x(i) ,y(i)} are the training examplesWe want the training, even more, faster, so we take a Gradient Descent step for each training example. Let’s see the implications in the image below:
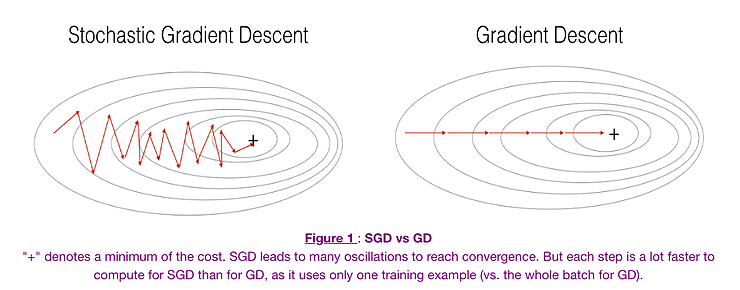
Let’s try to find some insights from the above diagram:
- In the left diagram of the above picture, we have SGD (where 1 per step time), where we take a Gradient Descent step for each example, and on the right diagram, we have GD (1 step per entire training set).
- SGD seems quite noisy, but it is also much faster than others and might not converge to a minimum.
It is observed that in SGD, the updates take more iterations to reach minima than in GD. On the contrary, GD takes fewer steps to reach minima. Still, the SGD algorithm is noisier and takes more iterations as the model parameters are frequently updated with high variance and fluctuations in loss functions at different intensities values.
Its code snippet simply adds a loop over the training examples and finds the gradient for each one.
for x in range(epochs):
np.random.shuffle(data)
for example in data:
params_gradient = find_gradient(loss_function, example, parameters)
parameters = parameters - learning_rate * params_gradientAdvantages of Stochastic Gradient Descent
- Faster Convergence: With frequent updates to model parameters, SGD converges more quickly than other methods, ideal for large datasets.
- Lower Memory Usage: SGD processes one data point at a time, eliminating the need to store the entire loss function and saving memory.
- Better Minima Exploration: The random updates allow SGD to escape local minima potentially, increasing the chance of reaching a better global minimum.
Disadvantages of Stochastic Gradient Descent
- High Parameter Variability: The frequent updates introduce high variance in model parameters, which can cause unstable convergence.
- Risk of Overshooting: Even near the global minimum, SGD can overshoot due to its fluctuating updates, complicating precise convergence.
- Learning Rate Adjustment Needed: To match the stable convergence of gradient descent, the learning rate must be gradually reduced over time, requiring careful tuning.
Mini-Batch Gradient Descent
To overcome the problem of large time complexity in the case of the SGD algorithm. MB-GD algorithm comes into the picture as an extension of the SGD algorithm. It’s not all, but it also overcomes the Gradient descent problem. Therefore, It’s considered the best among all the variations of gradient descent algorithms. MB-GD algorithm takes a batch of points or a subset of points from the dataset to compute derivate.
It is observed that the derivative of the loss function for MB-GD is almost the same as a derivate of the loss function for GD after several iterations. However, the number of iterations to achieve minima is large for MB-GD compared to GD, and the computation cost is also large.
Therefore, the weight updation depends on the derivate of loss for a batch of points. The updates in the case of MB-GD are much more noisy because the derivative does not always go towards minima.
It updates the model parameters after every batch. This algorithm divides the dataset into batches, updating the parameters after every batch.
Algorithm: θ=θ−α⋅∇J(θ; B(i)), where {B(i)} are the batches of training examplesIn the code snippet, instead of iterating over examples, we now iterate over mini-batches of size 30:
for x in range(epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=30):
params_gradient = find_gradient(loss_function, batch, parameters)
parameters = parameters - learning_rate * params_gradientAdvantages of Mini Batch Gradient Descent
- Frequent, Stable Updates: Mini-batch gradient descent offers frequent updates to model parameters while lowering variance, balancing speed and stability.
- Moderate Memory Requirement: It balances memory usage, needing only a medium amount to store mini-batches, making it feasible for large datasets.
Disadvantages of Mini Batch Gradient Descent
- Higher Noise in Updates: Mini-batch updates introduce noise in parameter updates, which can lead to less precise optimization compared to full-batch gradient descent.
- Slower Convergence: Compared to batch gradient descent, converging may take longer, requiring more iterations to reach the minimum.
- Risk of Local Minima: Mini-batch gradient descent can still get stuck in local minima, especially in non-convex optimization problems.
Challenges with All Types of Gradient-based Optimizers
- Optimum Learning Rate: We must choose an optimum learning rate value. If we choose a learning rate that is too small, gradient descent may take a long time to converge. For more about this challenge, refer to the above section on Learning Rate, which we discussed in the Gradient Descent Algorithm.
- Constant Learning Rate: All the parameters have a constant learning rate, but there may be some parameters that we do not want to change at the same rate.
- Local minimum: You may get stuck at local minima, i.e., you may not reach the local minimum.
Conclusion
In conclusion, gradient-based optimization techniques, such as Batch, Stochastic, and Mini-Batch Gradient Descent (the GD optimizer), play a crucial role in enhancing neural network performance by fine-tuning model parameters to minimize loss functions. Each optimizer offers unique advantages and faces specific challenges that impact convergence speed, memory efficiency, and stability. By understanding these gradient-based optimization methods, data scientists can tailor training strategies according to dataset characteristics, significantly improving the model’s potential for achieving optimal performance. By mastering these optimization techniques, data scientists can harness the power of gradient-based optimization in deep learning to its fullest capacity, facilitating advancements across various applications.
Frequently Asked Questions
Q1. What is a gradient-based optimizer?
A. A gradient-based optimizer is an algorithm that adjusts the parameters of a machine learning model by utilizing gradients (derivatives) of the loss function. It aims to minimize the loss by iteratively updating parameters in the direction of the steepest descent, thus improving model performance.
Q2. What is a gradient descent optimizer?
A. A gradient descent optimizer is a specific type of gradient-based optimizer that updates model parameters by calculating the gradient of the loss function with respect to the parameters. It adjusts parameters iteratively to converge towards a local or global minimum of the loss function, enhancing model accuracy.
Q3. What is the concept of gradient-based learning?
A. Gradient-based learning refers to a learning paradigm where algorithms optimize a model by minimizing a loss function using gradients. By computing these gradients, the model adjusts its parameters iteratively, leading to improved performance. This concept is foundational in training deep learning and neural network models.
Q4. What is the gradient search method in optimization?
A. The gradient search method is an optimization technique that finds the minimum or maximum of a function by following the direction of the gradient. It iteratively evaluates the function’s slope and updates parameters accordingly, gradually approaching the optimal solution. This method is widely used in machine learning and mathematical optimization.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
I am a B.Tech. student (Computer Science major) currently in the pre-final year of my undergrad. My interest lies in the field of Data Science and Machine Learning. I have been pursuing this interest and am eager to work more in these directions. I feel proud to share that I am one of the best students in my class who has a desire to learn many new things in my field.







Very Nice article Chirag. Easy to understand. Thanks