This article was published as a part of the Data Science Blogathon
Introduction
Most of the machine learning projects are stuck in the Jupyter notebooks. These models may be the best-trained and well hyper-parametrized with promising results, but it is of no use until the model is exposed to real-world data and there are no users to test the model.
I will walk you through the process of Deploying a Machine Learning model as an API using FastAPI and Heroku. Things covered in this article:
- A quick introduction to the dataset and the model
- Basics of FastAPI
- How to structure the code to use the ML model
- How to test and fetch this API?
- Deployment to Heroku
- Bonus: Docs Generation

The Dataset and Model
The problem statement I have chosen for this article series is Music Genre Classification. The dataset has been compiled by a research group called The Echo Nest. It contains various technical details about the music. These include Acousticness, Danceability, Energy, Instrumentalness, Liveness, Speechiness, Tempo, and Valence. The target variable for this data is whether the song belongs to Rock or Hip-Hop genre. Here are some details about the dataset:

The track id served no purpose to our analysis and therefore it was dropped. The genre_top is our target variable and contains either “Rock” or “Hip-Hop”. I trained a decision tree classifier for this dataset and got a good precision score. (I didn’t try other ensemble models such as Random Forest but you can test it).
After you are done with tuning the model and testing it on random data, it’s time to pickle the model. Pickling is the process of converting a python object into a byte stream. It saves the model as a file so that it can be accessed/loaded later on. Here is the code for the same if you’re not familiar:
pkl_filename = 'model.pkl'
with open(pkl_filename, 'wb') as f:
pickle.dump(model, f)
Introduction to FastAPI
It is a web framework that accelerates the backend development of a website using Python. This framework is new, adaptive, and easy to learn. It allows users to quickly set up the API, generates automatic docs for all the endpoints, offers authentication, data validation, allows asynchronous code, and much more. It is developed over Starlette which is a lightweight ASGI framework/toolkit and provides production-ready code.
On the other hand, Flask is older than FastAPI but still in use for many projects. Its minimalistic approach is promising and building APIs using flask is also not so hard. Both the frameworks have their own pros and cons.
Check out this article for a detailed comparison FastAPI: The Right Replacement for Flask?
For deploying our Machine learning model, we will be using the FastAPI approach. Before I dive into the code for making the Model API, let’s understand some FastAPI basics that will help in understanding the codebase better.
Basics of FastAPI
The FastAPI code structure is very similar to the Flask app structure. You need to create endpoints where our client service can make requests and obtain the required data. See the basic code implementation below:
import uvicorn
from fastapi import FastAPI
app = FastAPI()
@app.get('/')
def index():
return {'message': "This is the home page of this API. Go to /apiv1/ or /apiv2/?name="}
@app.get('/apiv1/{name}')
def api1(name: str):
return {'message': f'Hello! @{name}'}
@app.get('/apiv2/')
def api2(name: str):
return {'message': f'Hello! @{name}'}
if __name__ == '__main__':
uvicorn.run(app, host='127.0.0.1', port=4000, debug=True)
- The first two lines import FastAPI and uvicorn. The Uvicorn is used for implementing the server and handling all the calls in Python.
- Next, a FastAPI app instance is created.
- To Add routes/endpoints to this app instance, a function is created and a route decorator is added. This decorator registers the function for the route defined so that when that particular route is requested, the function is called and its result is returned to the client. Generally, we return a JSON object so that it can be parsed in any language.
- The best part about FastAPI is that you can define these routes directly for HTTP methods. In the Flask, you need to manually add them to a list of methods (updated in flask 2.0).
- To get the inputs from the client, you can use Path parameters, Query parameters, or Request bodies. The route “/apiv1/{name}” implements a path-based approach where the parameters are passed as paths. The route “/apiv2/” implements a query-based approach where the parameters are passed by appending the “?” at the end of the URL and using “&” to add multiple parameters.
See these routes in action:
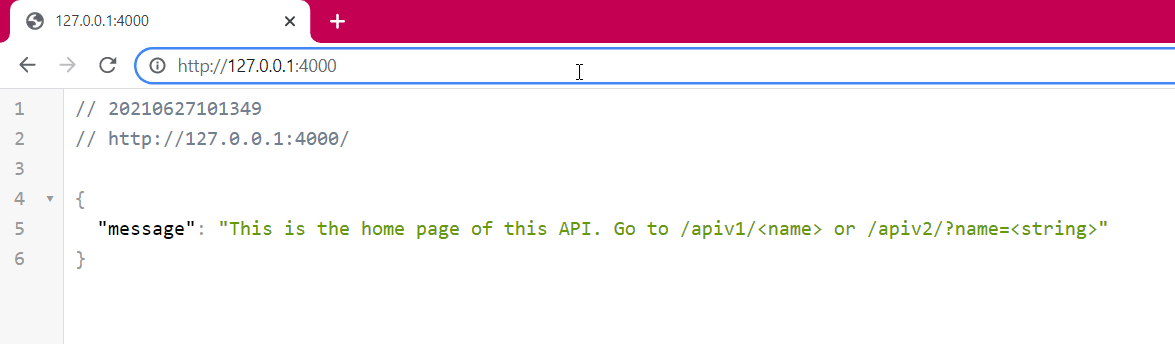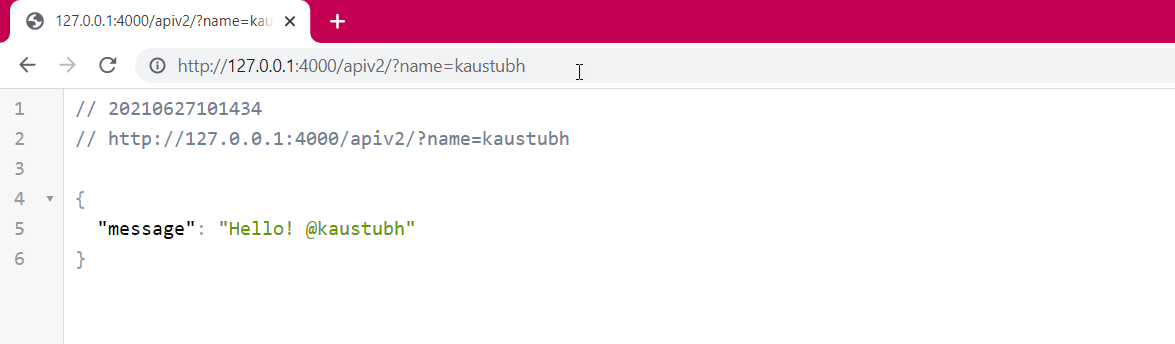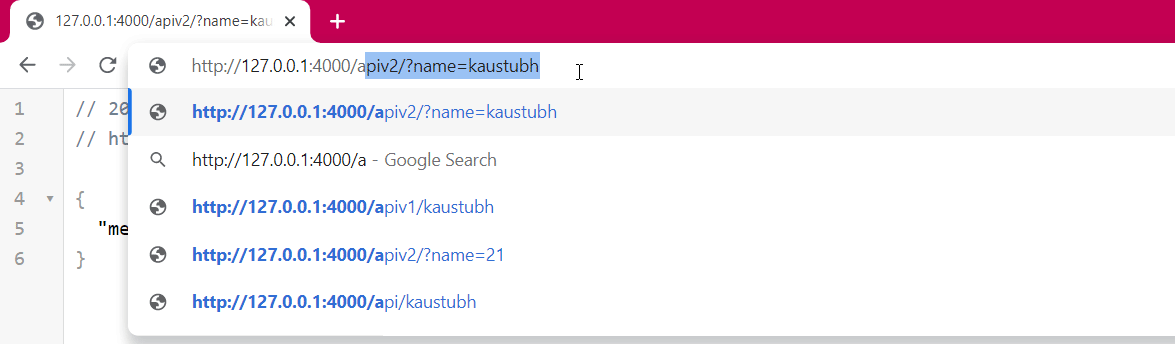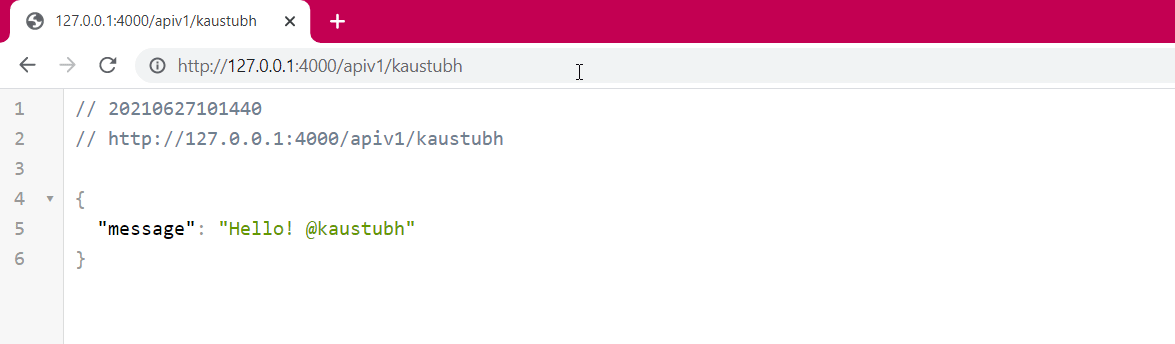
Request Body Approach
Using this approach, one can pass the data from the client to our API. In FastAPI, to simplify things, we use Pydantic models to define the data structure for the receiving data. The Pydantic does all the type checking for the parameters and returns explainable errors if the wrong type of parameter is received. Let’s add a data class to our existing code and create a route for the request body:
.
.
# After other imports
from pydantic import BaseModel
class Details(BaseModel):
f_name: str
l_name: str
phone_number: int
app = FastAPI()
.
.
.
# After old routes
@app.post('/apiv3/')
def api3(data: Details):
return {'message': data}
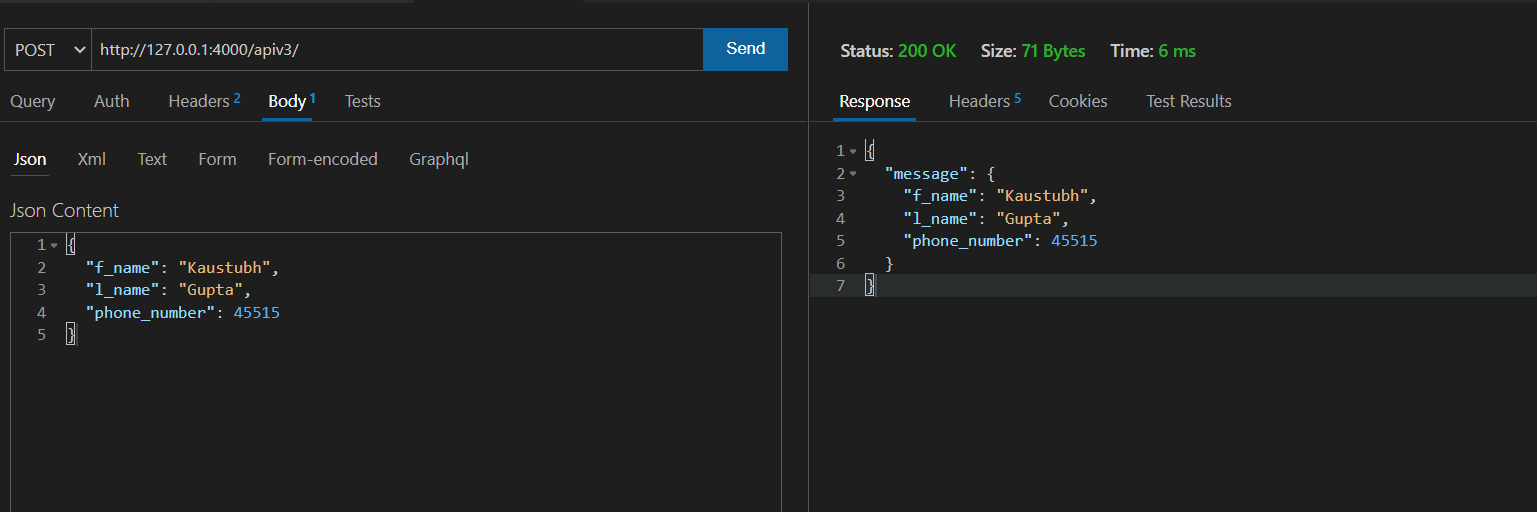
The route function declares a parameter “data” of the type “Details” defined above. This “Details” model is inherited from the Pydantic base model and offers data validation. To test out this route, I am using thunder client VS code extension to make a post request to our API “/apiv3/” route:
Wrapping The Model
Now that we have cleared out concepts on FastAPI, it’s time to integrate the model into the FastAPI code structure of making prediction requests. We will create a “/prediction” route which will take the data sent by the client request body and our API will return the response as a JSON object containing the result. Let’s see the code first and then I will explain the mechanics:
import uvicorn
import pickle
from fastapi import FastAPI
from pydantic import BaseModel
class Music(BaseModel):
acousticness: float
danceability: float
energy: float
instrumentalness: float
liveness: float
speechiness: float
tempo: float
valence: float
app = FastAPI()
with open("./FastAPI Files/model.pkl", "rb") as f:
model = pickle.load(f)
@app.get('/')
def index():
return {'message': 'This is the homepage of the API '}
@app.post('/prediction')
def get_music_category(data: Music):
received = data.dict()
acousticness = received['acousticness']
danceability = received['danceability']
energy = received['energy']
instrumentalness = received['instrumentalness']
liveness = received['liveness']
speechiness = received['speechiness']
tempo = received['tempo']
valence = received['valence']
pred_name = model.predict([[acousticness, danceability, energy,
instrumentalness, liveness, speechiness, tempo, valence]]).tolist()[0]
return {'prediction': pred_name}
if __name__ == '__main__':
uvicorn.run(app, host='127.0.0.1', port=4000, debug=True)
- We have created a Music Model class that defines all the parameters of our ML model. All the values are float type.
- Next, we are loading the model by unpickling it and saving the model as “model”. This model object will be used to get the predictions.
- The “/prediction” route function declares a parameter called “data” of the “Music” Model type. This parameter can be accessed as a dictionary. The dictionary object will allow us to access the values of the parameters as key-value pairs.
- Now, we are saving all the parameter values sent by the client. These values are now fed to the model predict function and we have our prediction for the data provided.
All the codes discussed in this article are available on my GitHub Repository.
Testing the Model API
Now it’s time for testing the API. You can test API via two methods:
Thunder client/Postman
We are using thunder client to send a post request to the “/prediction” route with a request body. The request body contains the key-value pairs of the parameters and we should expect a JSON response with the music genre classified.
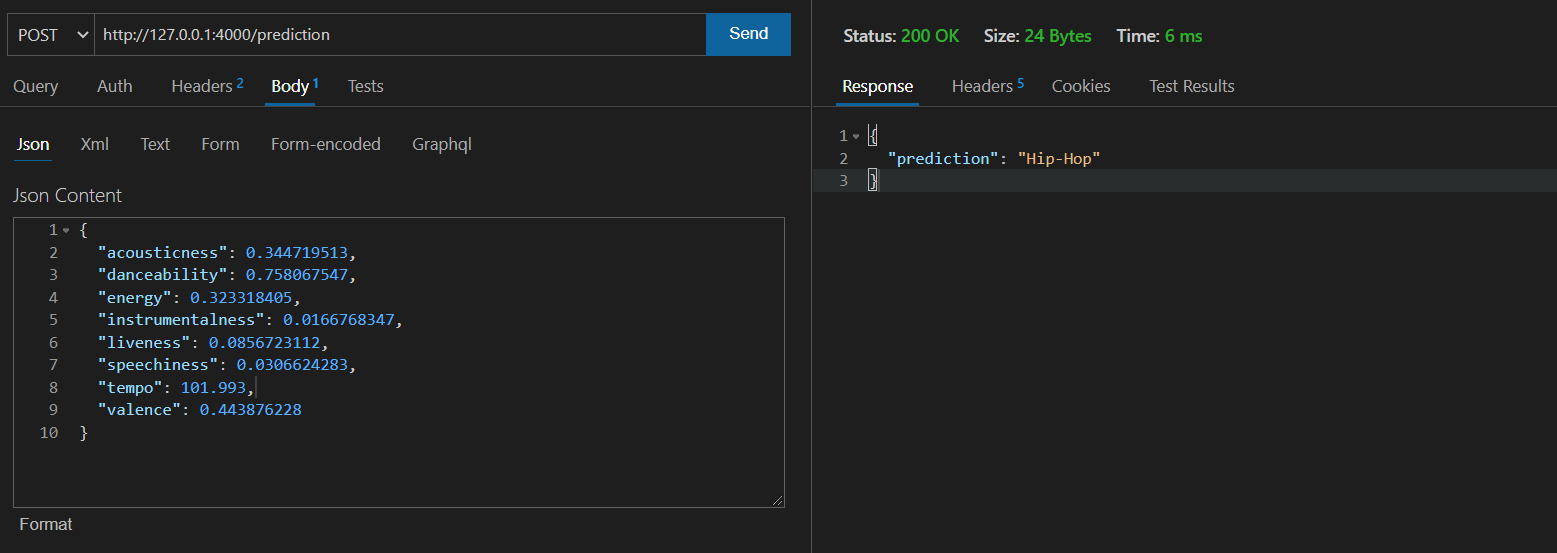
Making Request using the request module
If you don’t want to use the VSCode extensions or any API testing software, then you can simply create a separate Python program to call this API. Requests module of Python makes it possible to call APIs.
import requests
import json
url = "<local-host-url>/prediction"
payload = json.dumps({
"acousticness": 0.344719513,
"danceability": 0.758067547,
"energy": 0.323318405,
"instrumentalness": 0.0166768347,
"liveness": 0.0856723112,
"speechiness": 0.0306624283,
"tempo": 101.993,
"valence": 0.443876228
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
Replace the “local-host-url” with your URL which you get after running the FastAPI model API file. The output for this is:
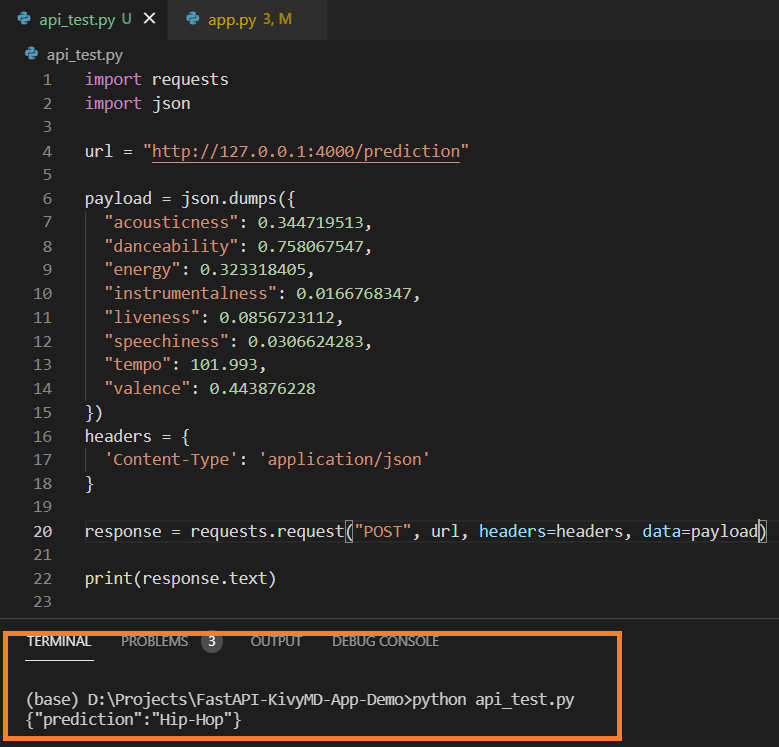
Hurray! You have successfully created an API for your Machine Learning model using FastAPI.
Deployment to Heroku
Our API is all set to be used by any type of program that makes a call to our API. But you can’t run this program all day on your local system, that’s practically not possible. Therefore, you need to deploy your service to a cloud platform that can run your code and return the returns.
Heroku is one such platform that offers free hosting. To deploy our API to Heroku, we need to create these files:
- Requirements.txt: This file should list all the external modules you used in your application. For our case, it was FastAPI, scikit-learn, uvicorn, and some other helper modules.
- runtime.txt: This file specifies the Python version to be installed by Heroku on its end.
- Procfile: This file is the interface file between our Python code and the Heroku platform. Note: Most of you don’t create this file properly. It’s not a text file. This file has no extension. To create such files, you can use GitHub add files or Vs code or cmd in windows or terminal in Linux. This file would contain the following command for FastAPI:
web: gunicorn -w 4 -k uvicorn.workers.UvicornWorker :app
Here, replace the file_name with the name of the Python file where you created the FastAPI code. After this:
- Put all these files (Model, Python file, requirements.txt, Procfile) in a GitHub repo
- Login into Heroku and create a new app. Connect your GitHub repo
- Click on Deploy Branch and your API will be up and running for anyone to use with the link!
Bonus: Docs Generation
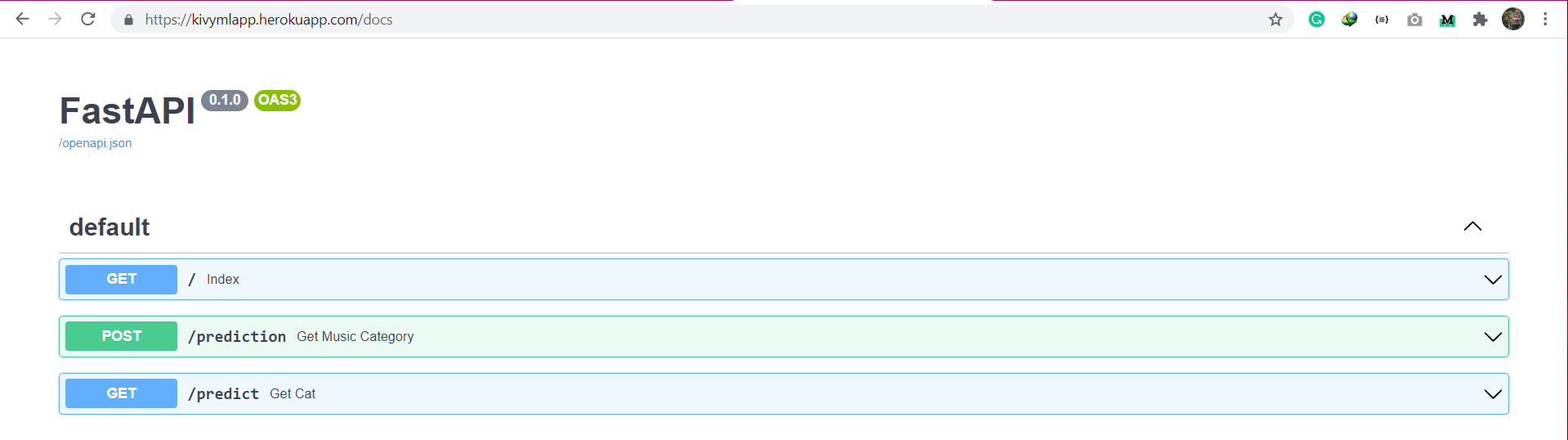
FastAPI has a special feature. It automatically generates docs for the API endpoints created. To access these docs, simply visit the “/docs” endpoint and you get a nice looking GUI created using Swagger and OpenAI. Now that we have deployed the service, the screenshot below is from the Heroku Deployed application. (Link: https://kivymlapp.herokuapp.com/)
Conclusion
In this detailed article, I introduced you to FastAPI, its basics, how to create the API file for the machine learning model, how to test this API, and how to deploy this API on the Heroku platform. We also saw how to access the docs endpoint which is automatically generated by FastAPI.
In the next article, I will show how to use the API made in this article to create an Android Music Prediction App using Python and we will also convert that Python file to APK!
Note: You can use this link, Master link to all my articles on Internet, which is updated every time I publish a new article to find that article.
If you have any doubts, queries, or potential opportunities, then you can reach out to me via
1. Linkedin – in/kaustubh-gupta/
2. Twitter – @Kaustubh1828
3. GitHub – kaustubhgupta
Kaustubh Gupta is a skilled engineer with a B.Tech in Information Technology from Maharaja Agrasen Institute of Technology. With experience as a CS Analyst and Analyst Intern at Prodigal Technologies, Kaustubh excels in Python, SQL, Libraries, and various engineering tools. He has developed core components of product intent engines, created gold tables in Databricks, and built internal tools and dashboards using Streamlit and Tableau. Recognized as India’s Top 5 Community Contributor 2023 by Analytics Vidhya, Kaustubh is also a prolific writer and mentor, contributing significantly to the tech community through speaking sessions and workshops.






