This article was published as a part of the Data Science Blogathon
Introduction
There are many ways to compare text in python. But, often we search for an easy way to compare text. Comparing text is needed for various text analytics and Natural Language Processing purposes.
One of the easiest ways of comparing text in python is using the fuzzy-wuzzy library. Here, we get a score out of 100, based on the similarity of the strings. Basically, we are given the similarity index. The library uses Levenshtein distance to calculate the difference between two strings.

Levenshtein Distance
The Levenshtein distance is a string metric to calculate the difference between two different strings. Soviet mathematician Vladimir Levenshtein formulated this method and it is named after him.
The Levenshtein distance between two strings a,b (of length {|a| and |b| respectively) is given by lev(a,b) where
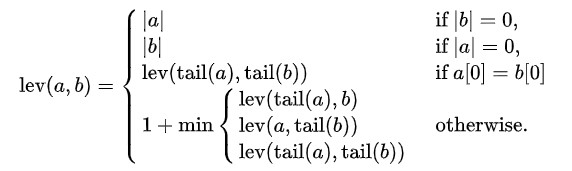
where the tail of some string x is a string of all but the first character of x, and x[n] is the nth character of the string x starting with character 0.
(Source: https://en.wikipedia.org/wiki/Levenshtein_distance)
FuzzyWuzzy
Fuzzy Wuzzy is an open-source library developed and released by SeatGeek. You can read their original blog here. The simple implementation and the unique score (out of 100) metic makes it interesting to use FuzzyWuzzy for text comparison and it has numerous applications.
Installation:
pip install fuzzywuzzy
pip install python-Levenshtein
These are the requirements that must be installed.
Let us now get started with the code by importing the necessary libraries.
Python Code:
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
# Same Strings
r1 = fuzz.ratio('London is a big city.', 'London is a big city.')
print(f"Output when both strings are same: {r1}")
# As the two strings are exactly the same here, we get the result 100, which indicates identical strings.
# Lets now try with different strings text
r2 = fuzz.ratio('London is a big city.', 'London is a very big city.')
print(f"Output when both strings are different: {r2}")
# As the strings are now different, the score is 89. So, we see the functioning of Fuzzy Wuzzy.
a1 = "Python Program"
a2 = "PYTHON PROGRAM"
Ratio = fuzz.ratio(a1.lower(),a2.lower())
print(Ratio)
Here, in this case, even though the two different strings had different cases, conversion of both to the lower case was done and the score was 100.
Substring Matching
Now, often various cases in text-matching might arise where we need to compare two different strings where one might be a substring of the other. For example, we are testing a text summarizer and we have to check how well is the summarizer performing. So, the summarized text will be a substring of the original string. FuzzyWuzzy has powerful functions to deal with such cases.
#fuzzywuzzy functions to work with substring matching b1 = "The Samsung Group is a South Korean multinational conglomerate headquartered in Samsung Town, Seoul." b2 = "Samsung Group is a South Korean company based in Seoul" Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(b1.lower(),b2.lower()) Partial_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">partial_ratio(b1.lower(),b2.lower()) print("Ratio:",Ratio) print("Partial Ratio:",Partial_Ratio)
Output:
Ratio: 64 Partial Ratio: 74
Here, we can see that the score for the Partial Ratio function is more. This indicates that it is able to recognize the fact that the string b2 has words from b1.
Token Sort Ratio
But, the above method of substring matching is not foolproof. Often the words are jumbled up and do not follow an order. Similarly, in the case of similar sentences, the order of words is different or mixed up. In this case, we use a different function.
c1 = "Samsung Galaxy SmartPhone" c2 = "SmartPhone Samsung Galaxy" Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(c1.lower(),c2.lower()) Partial_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">partial_ratio(c1.lower(),c2.lower()) Token_Sort_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(c1.lower(),c2.lower()) print("Ratio:",Ratio) print("Partial Ratio:",Partial_Ratio) print("Token Sort Ratio:",Token_Sort_Ratio)
Output:
Ratio: 56 Partial Ratio: 60 Token Sort Ratio: 100
So, here, in this case, we can see that the strings are just jumbled up versions of each other. And the two strings show the same sentiment and also mention the same entity. The standard fuzz function shows the score between them to be 56. And the Token Sort Ratio function shows the similarity to be 100.
So, it becomes clear that in some situations or applications, the Token Sort Ratio will be more useful.
Token Set Ratio
But, now if the two strings have different lengths. Token sort ratio functions might not be able to perform well in this situation. For this purpose, we have the Token Set Ratio function.
d1 = "Windows is built by Microsoft Corporation" d2 = "Microsoft Windows" Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(d1.lower(),d2.lower()) Partial_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">partial_ratio(d1.lower(),d2.lower()) Token_Sort_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(d1.lower(),d2.lower()) Token_Set_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(d1.lower(),d2.lower()) print("Ratio:",Ratio) print("Partial Ratio:",Partial_Ratio) print("Token Sort Ratio:",Token_Sort_Ratio) print("Token Set Ratio:",Token_Set_Ratio)
Output:
Ratio: 41 Partial Ratio: 65 Token Sort Ratio: 59 Token Set Ratio: 100
Ah! The score of 100. Well, the reason is that the string d2 components are entirely present in string d1.
Now, let us slightly modify string d2.
d1 = "Windows is built by Microsoft Corporation" d2 = "Microsoft Windows 10" Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(d1.lower(),d2.lower()) Partial_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">partial_ratio(d1.lower(),d2.lower()) Token_Sort_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(d1.lower(),d2.lower()) Token_Set_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(d1.lower(),d2.lower()) print("Ratio:",Ratio) print("Partial Ratio:",Partial_Ratio) print("Token Sort Ratio:",Token_Sort_Ratio) print("Token Set Ratio:",Token_Set_Ratio)
By, slightly modifying the text d2 we can see that the score is reduced to 92. This is because the text “10” is not present in string d1.
WRatio()
This function helps to manage the upper case, lower case, and some other parameters.
#fuzz.WRatio() print("Slightly change of cases:",fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio('Ferrari LaFerrari', 'FerrarI LAFerrari'))
Output:
Slightly change of cases: 100
Let us try removing a space.
#fuzz.WRatio() print("Slightly change of cases and a space removed:",fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio('Ferrari LaFerrari', 'FerrarILAFerrari'))
Output:
Slightly change of cases and a space removed: 97
Let us try some punctuation.
#handling some random punctuations g1='Microsoft Windows is good, but takes up lof of ram!!!' g2='Microsoft Windows is good but takes up lof of ram?' print(fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.WRatio'}, '*')">WRatio(g1,g2 ))
Output: 99
Thus, we can see that FuzzyWuzzy has a lot of interesting functions which can be used to do interesting text comparison tasks.
Some Suitable Applications:
FuzzyWuzzy can have some interesting applications.
It can be used to assess summaries of larger texts and judge their similarity. This can be used to measure the performance of text summarizers.
Based on the similarity of texts, it can also be used to identify the authenticity of a text, article, news, book etc. Often, we come across various incorrect text/ data. Often cross-checking each and every text data is not possible. Using text similarity, cross-checking of various texts can be done.
FuzzyWuzzy can also come in handy in selecting the best similar text out of a number of texts. So, the applications of FuzzyWuzzy are numerous.
Text similarity is an important metric that can be used for various NLP and Text Analytics purposes. The interesting thing about FuzzyWuzzy is that similarities are given as a score out of 100. This allows relative scoring and also generates a new feature /data that can be used for analytics/ ML purposes.
Summary Similarity:
#uses of fuzzy wuzzy #summary similarity input_text="Text Analytics involves the use of unstructured text data, processing them into usable structured data. Text Analytics is an interesting application of Natural Language Processing. Text Analytics has various processes including cleaning of text, removing stopwords, word frequency calculation, and much more. Text Analytics has gained much importance these days. As millions of people engage in online platforms and communicate with each other, a large amount of text data is generated. Text data can be blogs, social media posts, tweets, product reviews, surveys, forum discussions, and much more. Such huge amounts of data create huge text data for organizations to use. Most of the text data available are unstructured and scattered. Text analytics is used to gather and process this vast amount of information to gain insights. Text Analytics serves as the foundation of many advanced NLP tasks like Classification, Categorization, Sentiment Analysis, and much more. Text Analytics is used to understand patterns and trends in text data. Keywords, topics, and important features of Text are found using Text Analytics. There are many more interesting aspects of Text Analytics, now let us proceed with our resume dataset. The dataset contains text from various resume types and can be used to understand what people mainly use in resumes. Resume Text Analytics is often used by recruiters to understand the profile of applicants and filter applications. Recruiting for jobs has become a difficult task these days, with a large number of applicants for jobs. Human Resources executives often use various Text Processing and File reading tools to understand the resumes sent. Here, we work with a sample resume dataset, which contains resume text and resume category. We shall read the data, clean it and try to gain some insights from the data."
The above is the original text.
output_text="Text Analytics involves the use of unstructured text data, processing them into usable structured data. Text Analytics is an interesting application of Natural Language Processing. Text Analytics has various processes including cleaning of text, removing stopwords, word frequency calculation, and much more. Text Analytics is used to understand patterns and trends in text data. Keywords, topics, and important features of Text are found using Text Analytics. There are many more interesting aspects of Text Analytics, now let us proceed with our resume dataset. The dataset contains text from various resume types and can be used to understand what people mainly use in resumes."
Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.ratio'}, '*')">ratio(input_text.lower(),output_text.lower()) Partial_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.partial_ratio'}, '*')">partial_ratio(input_text.lower(),output_text.lower()) Token_Sort_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_sort_ratio'}, '*')">token_sort_ratio(input_text.lower(),output_text.lower()) Token_Set_Ratio = fuzz.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.fuzz.token_set_ratio'}, '*')">token_set_ratio(input_text.lower(),output_text.lower()) print("Ratio:",Ratio) print("Partial Ratio:",Partial_Ratio) print("Token Sort Ratio:",Token_Sort_Ratio) print("Token Set Ratio:",Token_Set_Ratio)
Output:
Ratio: 54 Partial Ratio: 79 Token Sort Ratio: 54 Token Set Ratio: 100
We can see the various scores. The partial ratio does show that they are quite similar, which should be the case. Also, the token set ratio is 100, which is evident as the summary is completely taken from the original text.
Best possible String match:
Let us use the process library to find the best possible string match among a list of strings.
#choosing the possible string match #using process library query = 'Stack Overflow' choices = ['Stock Overhead', 'Stack Overflowing', 'S. Overflow',"Stoack Overflow"] print("List of ratios: ") print(process.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.process.extract'}, '*')">extract(query, choices)) print("Best choice: ",process.<a onclick="parent.postMessage({'referent':'.fuzzywuzzy.process.extractOne'}, '*')">extractOne(query, choices))
Output:
List of ratios:
[('Stoack Overflow', 97), ('Stack Overflowing', 90), ('S. Overflow', 85), ('Stock Overhead', 64)]
Best choice: ('Stoack Overflow', 97)
Hence, the similarity scores and the best match are given.
Final Words
FuzzyWuzzy library is created on top of the difflib library. And python-Levenshtein used for optimizing the speed. So we can understand that FuzzyWuzzy is one of the best ways for string comparison in Python.
Do check out the code on Kaggle here.
About me:
Prateek Majumder
Data Science and Analytics | Digital Marketing Specialist | SEO | Content Creation
Connect with me on Linkedin.
My other articles on Analytics Vidhya: Link.
Thank You.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Prateek is a dynamic professional with a strong foundation in Artificial Intelligence and Data Science, currently pursuing his PGP at Jio Institute. He holds a Bachelor's degree in Electrical Engineering and has hands-on experience as a System Engineer at TCS Digital, where he excelled in API management and data integration. Prateek also has a background in product marketing and analytics from his time with start-ups like AppleX and Milkie Way, Inc., where he was involved in growth campaigns and technical blog management. Recognized for his structured thinking and problem-solving abilities, he has received accolades like the Dr. Sudarshan Chakraborty Award for Best Student Performance. Fluent in multiple languages and passionate about technology, Prateek continues to expand his expertise in the rapidly evolving AI and tech landscape.




Great overview of the FuzzyWuzzy Python Library! I’ve been looking for effective tools for text matching, and your insights on its functionalities and potential applications in NLP are really helpful. Can't wait to try it out in my projects!
This article made me stop and think. This was very informative and practical. I like the balance between theory and practice.