This article was published as a part of the Data Science Blogathon
Introduction
Natural Language Processing (NLP) is a field at the convergence of artificial intelligence, and linguistics. The aim is to make the computers understand real-world language or natural language so that they can perform tasks like Question Answering, Language Translation, and many more.
NLP has lots of applications in different fields.
1. NLP enables the recognition and prediction of diseases based on electronic health records.
2. It is used to obtain customer reviews.
3. To help to identify fake news.
4. Chatbots.
5. Social Media monitoring etc.
What is the Transformer?
The Transformer model architecture was introduced by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin in their paper “Attention Is All You Need”. [1]
The Transformer model extracts the features for each word using a self-attention mechanism to know the importance of each word in the sentence. No other recurrent units are used to extract this feature, they are just activations and weighted sums, so they can be very efficient and parallelizable.
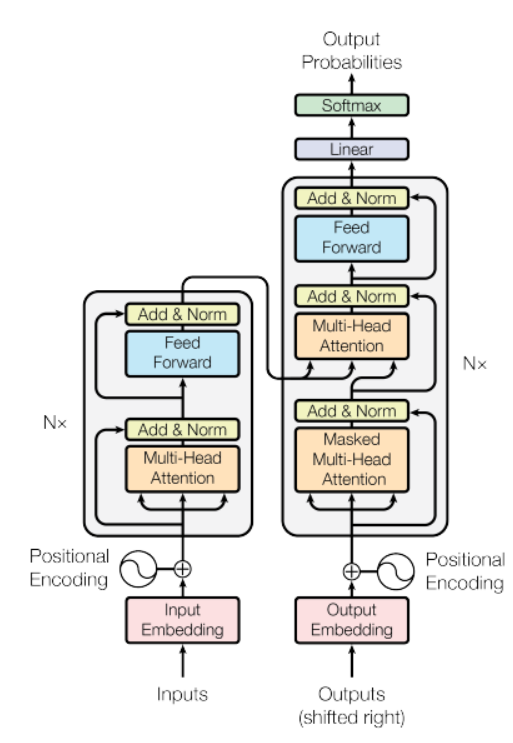
Source: ” Attention Is All You Need” paper
In the above figure, there is an encoder model on the left side and the decoder on the right. Both encoder and decoder contain a core block of attention and a feed-forward network repeated N number of times.
In the above figure, there is an encoder model on the left side and the decoder on the right. Both encoder and decoder contain a core block of attention and a feed-forward network repeated N number of times.
It has a stack of 6 Encoder and 6 Decoder, the Encoder contains two layers(sub-layers), that is a multi-head self-attention layer, and a fully connected feed-forward network. The Decoder contains three layers(sub-layers), a multi-head self-attention layer, another multi-head self-attention layer to perform self-attention over encoder outputs, and a fully connected feed-forward network. Each sub-layer in Decoder and Encoder has a Residual connection with layer normalization.
Let’s Start Building Language Translation Model
Here we will be using the Multi30k dataset. Don’t worry the dataset will be downloaded with a piece of code.
First the Data processing part we will use the torchtext module from PyTorch. The torchtext has utilities for creating datasets that can be easily iterated for the purposes of creating a language translation model. The below code will download the dataset and also tokenizes a raw text, build the vocabulary, and convert tokens into a tensor.
import math import torchtext import torch import torch.nn as nn from torchtext.data.utils import get_tokenizer from collections import Counter from torchtext.vocab import Vocab from torchtext.utils import download_from_url, extract_archive from torch.nn.utils.rnn import pad_sequence from torch.utils.data import DataLoader from torch import Tensor from torch.nn import (TransformerEncoder, TransformerDecoder,TransformerEncoderLayer, TransformerDecoderLayer) import io import time
url_base = 'https://raw.githubusercontent.com/multi30k/dataset/master/data/task1/raw/'
train_urls = ('train.de.gz', 'train.en.gz')
val_urls = ('val.de.gz', 'val.en.gz')
test_urls = ('test_2016_flickr.de.gz', 'test_2016_flickr.en.gz')
train_filepaths = [extract_archive(download_from_url(url_base + url))[0] for url in train_urls]
val_filepaths = [extract_archive(download_from_url(url_base + url))[0] for url in val_urls]
test_filepaths = [extract_archive(download_from_url(url_base + url))[0] for url in test_urls]
de_tokenizer = get_tokenizer('spacy', language='de_core_news_sm')
en_tokenizer = get_tokenizer('spacy', language='en_core_web_sm')
def build_vocab(filepath, tokenizer):
counter = Counter()
with io.open(filepath, encoding="utf8") as f:
for string_ in f:
counter.update(tokenizer(string_))
return Vocab(counter, specials=['<unk>', '<pad>', '<bos>', '<eos>'])
de_vocab = build_vocab(train_filepaths[0], de_tokenizer)
en_vocab = build_vocab(train_filepaths[1], en_tokenizer)
def data_process(filepaths):
raw_de_iter = iter(io.open(filepaths[0], encoding="utf8"))
raw_en_iter = iter(io.open(filepaths[1], encoding="utf8"))
data = []
for (raw_de, raw_en) in zip(raw_de_iter, raw_en_iter):
de_tensor_ = torch.tensor([de_vocab[token] for token in de_tokenizer(raw_de.rstrip("n"))],
dtype=torch.long)
en_tensor_ = torch.tensor([en_vocab[token] for token in en_tokenizer(raw_en.rstrip("n"))],
dtype=torch.long)
data.append((de_tensor_, en_tensor_))
return data
train_data = data_process(train_filepaths)
val_data = data_process(val_filepaths)
test_data = data_process(test_filepaths)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
BATCH_SIZE = 128
PAD_IDX = de_vocab['<pad>']
BOS_IDX = de_vocab['<bos>']
EOS_IDX = de_vocab['<eos>']
Then we will use the PyTorch DataLoader module which combines a dataset and a sampler, and it enables us to iterate over the given dataset. The DataLoader supports both iterable-style and map-style datasets with single or multi-process loading, also we can customize loading order and memory pinning.
# DataLoader
def generate_batch(data_batch):
de_batch, en_batch = [], []
for (de_item, en_item) in data_batch:
de_batch.append(torch.cat([torch.tensor([BOS_IDX]), de_item, torch.tensor([EOS_IDX])], dim=0))
en_batch.append(torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0))
de_batch = pad_sequence(de_batch, padding_value=PAD_IDX)
en_batch = pad_sequence(en_batch, padding_value=PAD_IDX)
return de_batch, en_batch
train_iter = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True, collate_fn=generate_batch) valid_iter = DataLoader(val_data, batch_size=BATCH_SIZE, shuffle=True, collate_fn=generate_batch) test_iter = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=True, collate_fn=generate_batch)
Then we are designing the transformer. Here the Encoder processes the input sequence by propagating it through a series of Multi-head Attention and Feedforward network layers. The output from this Encoder is referred to as memory below and is fed to the decoder along with target tensors. Encoder and decoder are trained in an end-to-end fashion.
# transformer
class Seq2SeqTransformer(nn.Module):
def __init__(self, num_encoder_layers: int, num_decoder_layers: int,
emb_size: int, src_vocab_size: int, tgt_vocab_size: int,
dim_feedforward:int = 512, dropout:float = 0.1):
super(Seq2SeqTransformer, self).__init__()
encoder_layer = TransformerEncoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_encoder = TransformerEncoder(encoder_layer, num_layers=num_encoder_layers)
decoder_layer = TransformerDecoderLayer(d_model=emb_size, nhead=NHEAD,
dim_feedforward=dim_feedforward)
self.transformer_decoder = TransformerDecoder(decoder_layer, num_layers=num_decoder_layers)
self.generator = nn.Linear(emb_size, tgt_vocab_size)
self.src_tok_emb = TokenEmbedding(src_vocab_size, emb_size)
self.tgt_tok_emb = TokenEmbedding(tgt_vocab_size, emb_size)
self.positional_encoding = PositionalEncoding(emb_size, dropout=dropout)
def forward(self, src: Tensor, trg: Tensor, src_mask: Tensor,
tgt_mask: Tensor, src_padding_mask: Tensor,
tgt_padding_mask: Tensor, memory_key_padding_mask: Tensor):
src_emb = self.positional_encoding(self.src_tok_emb(src))
tgt_emb = self.positional_encoding(self.tgt_tok_emb(trg))
memory = self.transformer_encoder(src_emb, src_mask, src_padding_mask)
outs = self.transformer_decoder(tgt_emb, memory, tgt_mask, None,
tgt_padding_mask, memory_key_padding_mask)
return self.generator(outs)
def encode(self, src: Tensor, src_mask: Tensor):
return self.transformer_encoder(self.positional_encoding(
self.src_tok_emb(src)), src_mask)
def decode(self, tgt: Tensor, memory: Tensor, tgt_mask: Tensor):
return self.transformer_decoder(self.positional_encoding(
self.tgt_tok_emb(tgt)), memory,
tgt_mask)
The Text which is converted to tokens is represented by using token embeddings. The Positional encoding function is added to the token embedding so that we can get the notions of word order.
class PositionalEncoding(nn.Module):
def __init__(self, emb_size: int, dropout, maxlen: int = 5000):
super(PositionalEncoding, self).__init__()
den = torch.exp(- torch.arange(0, emb_size, 2) * math.log(10000) / emb_size)
pos = torch.arange(0, maxlen).reshape(maxlen, 1)
pos_embedding = torch.zeros((maxlen, emb_size))
pos_embedding[:, 0::2] = torch.sin(pos * den)
pos_embedding[:, 1::2] = torch.cos(pos * den)
pos_embedding = pos_embedding.unsqueeze(-2)
self.dropout = nn.Dropout(dropout)
self.register_buffer('pos_embedding', pos_embedding)
def forward(self, token_embedding: Tensor):
return self.dropout(token_embedding +
self.pos_embedding[:token_embedding.size(0),:])
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size: int, emb_size):
super(TokenEmbedding, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.emb_size = emb_size
def forward(self, tokens: Tensor):
return self.embedding(tokens.long()) * math.sqrt(self.emb_size)
Here in the below code, a subsequent word mask is created to stop a target word from attending to its subsequent words. Here the masks are also created, for masking source and target padding tokens.
def generate_square_subsequent_mask(sz):
mask = (torch.triu(torch.ones((sz, sz), device=DEVICE)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def create_mask(src, tgt):
src_seq_len = src.shape[0]
tgt_seq_len = tgt.shape[0]
tgt_mask = generate_square_subsequent_mask(tgt_seq_len)
src_mask = torch.zeros((src_seq_len, src_seq_len), device=DEVICE).type(torch.bool)
src_padding_mask = (src == PAD_IDX).transpose(0, 1)
tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)
return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
Then define the model parameters and instantiate the model.
SRC_VOCAB_SIZE = len(de_vocab)
TGT_VOCAB_SIZE = len(en_vocab)
EMB_SIZE = 512
NHEAD = 8
FFN_HID_DIM = 512
BATCH_SIZE = 128
NUM_ENCODER_LAYERS = 3
NUM_DECODER_LAYERS = 3
NUM_EPOCHS = 50
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
transformer = Seq2SeqTransformer(NUM_ENCODER_LAYERS, NUM_DECODER_LAYERS,
EMB_SIZE, SRC_VOCAB_SIZE, TGT_VOCAB_SIZE,
FFN_HID_DIM)
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
transformer = transformer.to(device)
loss_fn = torch.nn.CrossEntropyLoss(ignore_index=PAD_IDX)
optimizer = torch.optim.Adam(
transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9
)
Define two different functions, that is for train and evaluation.
def train_epoch(model, train_iter, optimizer):
model.train()
losses = 0
for idx, (src, tgt) in enumerate(train_iter):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = model(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
optimizer.zero_grad()
tgt_out = tgt[1:, :]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
loss.backward()
optimizer.step()
losses += loss.item()
torch.save(model, PATH)
return losses / len(train_iter)
def evaluate(model, val_iter):
model.eval()
losses = 0
for idx, (src, tgt) in (enumerate(valid_iter)):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:-1, :]
src_mask, tgt_mask, src_padding_mask, tgt_padding_mask = create_mask(src, tgt_input)
logits = model(src, tgt_input, src_mask, tgt_mask,
src_padding_mask, tgt_padding_mask, src_padding_mask)
tgt_out = tgt[1:, :]
loss = loss_fn(logits.reshape(-1, logits.shape[-1]), tgt_out.reshape(-1))
losses += loss.item()
return losses / len(val_iter)
Now training the model.
for epoch in range(1, NUM_EPOCHS+1):
start_time = time.time()
train_loss = train_epoch(transformer, train_iter, optimizer)
end_time = time.time()
val_loss = evaluate(transformer, valid_iter)
print((f"Epoch: {epoch}, Train loss: {train_loss:.3f}, Val loss: {val_loss:.3f}, "
f"Epoch time = {(end_time - start_time):.3f}s"))
This model is trained using transformer architecture in such a way that it trains faster and also it converges to a lower validation loss compared to other RNN models.
def greedy_decode(model, src, src_mask, max_len, start_symbol):
src = src.to(device)
src_mask = src_mask.to(device)
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type(torch.long).to(device)
for i in range(max_len-1):
memory = memory.to(device)
memory_mask = torch.zeros(ys.shape[0], memory.shape[0]).to(device).type(torch.bool)
tgt_mask = (generate_square_subsequent_mask(ys.size(0))
.type(torch.bool)).to(device)
out = model.decode(ys, memory, tgt_mask)
out = out.transpose(0, 1)
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.item()
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=0)
if next_word == EOS_IDX:
break
return ys
def translate(model, src, src_vocab, tgt_vocab, src_tokenizer):
model.eval()
tokens = [BOS_IDX] + [src_vocab.stoi[tok] for tok in src_tokenizer(src)] + [EOS_IDX]
num_tokens = len(tokens)
src = (torch.LongTensor(tokens).reshape(num_tokens, 1))
src_mask = (torch.zeros(num_tokens, num_tokens)).type(torch.bool)
tgt_tokens = greedy_decode(model, src, src_mask, max_len=num_tokens + 5, start_symbol=BOS_IDX).flatten()
return " ".join([tgt_vocab.itos[tok] for tok in tgt_tokens]).replace("<bos>", "").replace("<eos>", "")
Now, let’s test our model on translation.
output = translate(transformer, "Eine Gruppe von Menschen steht vor einem Iglu .", de_vocab, en_vocab, de_tokenizer) print(output)
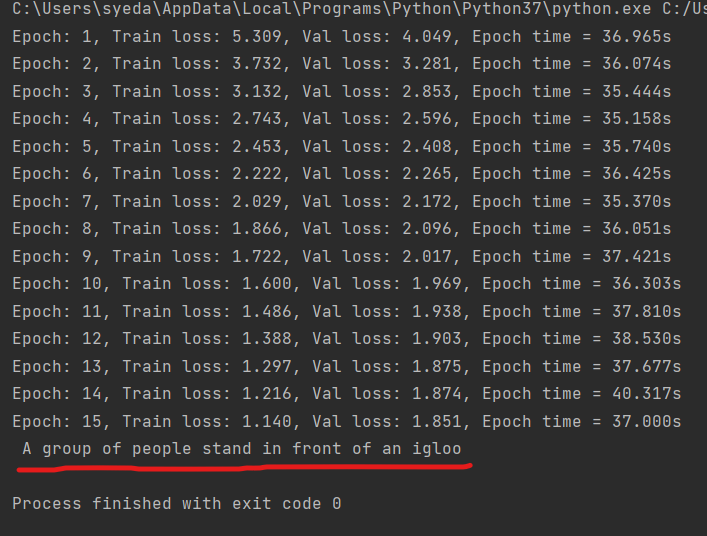
Above the red line is the output from the translation model. You can also compare it with google translator.
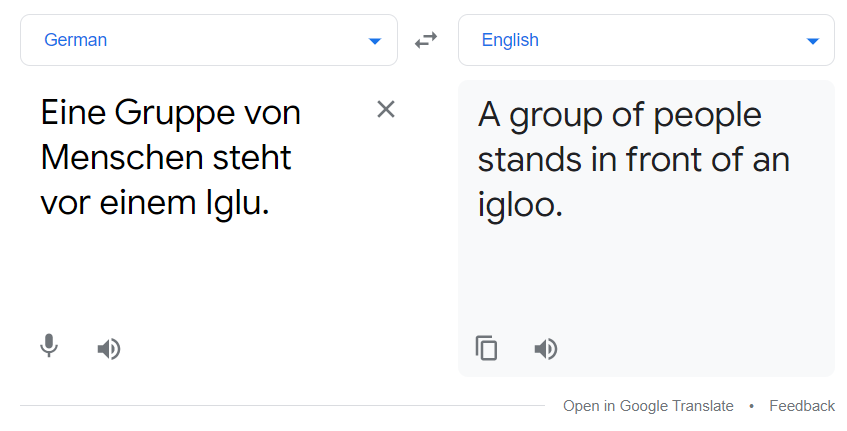
The above translation and the output from our model matched. The model is not the best but still does the job up to some extent.
Reference
[1]. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin: Attention Is All You Need, Dec 2017, DOI: https://arxiv.org/pdf/1706.03762.pdfAlso for more information refer to https://pytorch.org/tutorials/
Thank you
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
I thrive on the thrill of the challenge, tackling complex problems and crafting innovative AI solutions that make a difference. Whether it's optimizing or building sustainable AI ecosystems, I believe in harnessing the power of AI for the greater good. Let's brainstorm, collaborate, and change the world, one byte at a time.




Can you please provide me or help me yo find tenserflow code for the same..