This article was published as a part of the Data Science Blogathon
Introduction
Speech Recognition is a supervised learning task. In the speech recognition problem input will be the audio signal and we have to predict the text from the audio signal. We can’t take the raw audio signal as input to our model because there will be a lot of noise in the audio signal. It is observed that extracting features from the audio signal and using it as input to the base model will produce much better performance than directly considering raw audio signal as input. MFCC is the widely used technique for extracting the features from the audio signal.
Let’s dive into the MFCC algorithm.
New Feature
Get Personalized Learning Path! Set your goal and timeline. Get a path—under 2 mins.
Mel-frequency cepstral coefficients(MFCC):
MFCC is a feature extraction technique widely used in speech and audio processing. MFCCs are used to represent the spectral characteristics of sound in a way that is well-suited for various machine learning tasks, such as speech recognition and music analysis.
In simpler terms, MFCCs are a set of coefficients that capture the shape of the power spectrum of a sound signal. They are derived by first transforming the raw audio signal into a frequency domain using a technique like the Discrete Fourier Transform (DFT), and then applying the mel-scale to approximate the human auditory perception of sound frequency. Finally, cepstral coefficients are computed from the mel-scaled spectrum.
MFCCs are particularly useful because they emphasize features of the audio signal that are important for human speech perception while discarding less relevant information. This makes them effective for tasks like speaker recognition, emotion detection, and speech-to-text conversion.
The road map of the MFCC technique is given below.
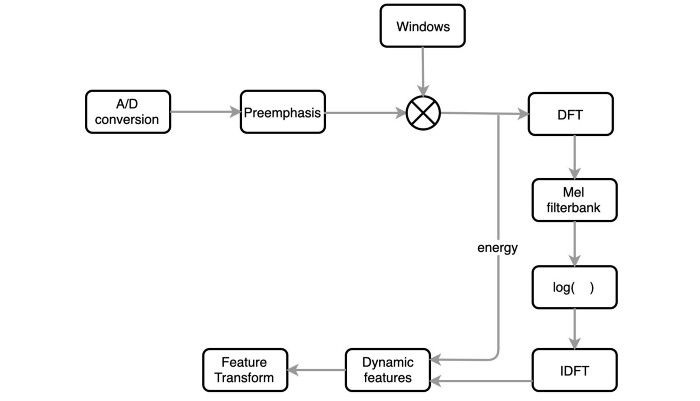
We will look into each step-by-step.
A/D Conversion:
In this step, we will convert our audio signal from analog to digital format with a sampling frequency of 8kHz or 16kHz.
Preemphasis:
Preemphasis increases the magnitude of energy in the higher frequency. When we look at the frequency domain of the audio signal for the voiced segments like vowels, it is observed that the energy at a higher frequency is much lesser than the energy in lower frequencies. Boosting the energy in higher frequencies will improve the phone detection accuracy thereby improving the performance of the model.
Preemphasis is done by the first order high-pass filter as given below
The frequency domain of the audio signal for vowel ‘aa’, before and after the preemphasis is given below
Windowing:
The MFCC technique aims to develop the features from the audio signal which can be used for detecting the phones in the speech. But in the given audio signal there will be many phones, so we will break the audio signal into different segments with each segment having 25ms width and with the signal at 10ms apart as shown in the below figure. On average a person speaks three words per second with 4 phones and each phone will have three states resulting in 36 states per second or 28ms per state which is close to our 25ms window.
From each segment, we will extract 39 features. Moreover, while breaking the signal, if we directly chop it off at the edges of the signal, the sudden fall in amplitude at the edges will produce noise in the high-frequency domain. So instead of a rectangular window, we will use Hamming/Hanning windows to chop the signal which won’t produce the noise in the high-frequency region.
DFT( Discrete Fourier Transform):
We will convert the signal from the time domain to the frequency domain by applying the dft transform. For audio signals, analyzing in the frequency domain is easier than in the time domain.
Mel-Filter Bank:
The way our ears will perceive the sound is different from how the machines will perceive the sound. Our ears have higher resolution at a lower frequency than at a higher frequency. So if we hear sound at 200 Hz and 300 Hz we can differentiate it easily when compared to the sounds at 1500 Hz and 1600 Hz even though both had a difference of 100 Hz between them. Whereas for the machine the resolution is the same at all the frequencies. It is noticed that modeling the human hearing property at the feature extraction stage will improve the performance of the model.
So we will use the mel scale to map the actual frequency to the frequency that human beings will perceive. The formula for the mapping is given below.
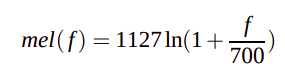
Applying Log:
Humans are less sensitive to change in audio signal energy at higher energy compared to lower energy. Log function also has a similar property, at a low value of input x gradient of log function will be higher but at high value of input gradient value is less. So we apply log to the output of Mel-filter to mimic the human hearing system.
IDFT:
In this step, we are doing the inverse transform of the output from the previous step. Before knowing why we have to do inverse transform we have to first understand how the sound produced by human beings.
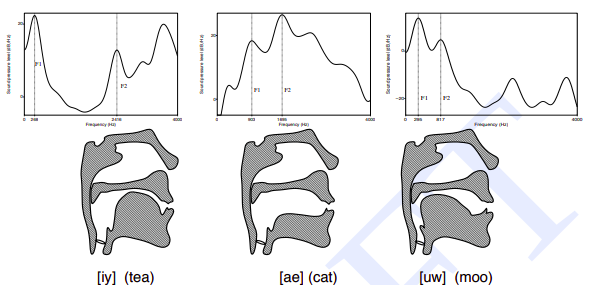
The sound is actually produced by the glottis which is a valve that controls airflow in and out of the respiratory passages. The vibration of the air in the glottis produces the sound. The vibrations will occur in harmonics and the smallest frequency that is produced is called the fundamental frequency and all the remaining frequencies are multiples of the fundamental frequency. The vibrations that are produced will be passed into the vocal cavity. The vocal cavity selectively amplifies and damp frequencies based on the position of the tongue and other articulators. Each sound produced will have its unique position of the tongue and other articulators.
The following picture shows the transfer function of the vocal cavity for different phones.
Note that the periods in the time domain and frequency domain are inverted after the transformations. So, the frequency domain’s fundamental frequency with the lowest frequency will have the highest frequency in the time domain.
Note: The inverse of the log of the magnitude of the signal is called a cepstrum.
The below figure shows the signal sample before and after the idft operation.
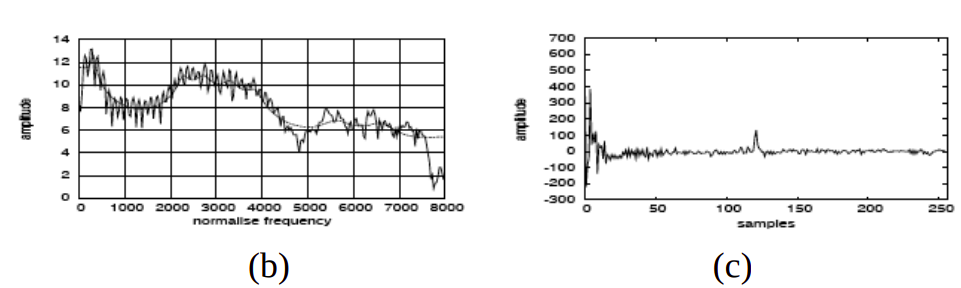
The peak frequency at the rightmost in figure(c) is the fundamental frequency and it will provide information about the pitch and frequencies at the rightmost will provide information about the phones. We will discard the fundamental frequency as it is not providing any information about phones.
The MFCC model takes the first 12 coefficients of the signal after applying the idft operations. Along with the 12 coefficients, it will take the energy of the signal sample as the feature. It will help in identifying the phones. The formula for the energy of the sample is given below.
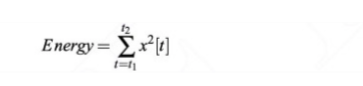
Dynamic Features:
Along with these 13 features, the MFCC technique will consider the first order derivative and second order derivatives of the features which constitute another 26 features.
Derivatives are calculated by taking the difference of these coefficients between the samples of the audio signal and it will help in understanding how the transition is occurring.
So overall MFCC technique will generate 39 features from each audio signal sample which are used as input for the speech recognition model.
References:
1. Automatic Speech Recognition
2. Phonetics
Disclaimer: All the figures in this article are taken from the above-mentioned references.
Frequently Asked Questions
Q1. What is MFCC used for?
A. MFCC (Mel Frequency Cepstral Coefficients) is used for feature extraction in speech and audio processing. It captures spectral characteristics of sound, emphasizing human auditory perception. Widely used in speech recognition, speaker identification, and music analysis, MFCCs enable efficient representation of audio data for machine learning algorithms to classify, recognize, and analyze sound patterns.
Q2. What is MFCC in AI?
A. In AI, MFCC (Mel Frequency Cepstral Coefficients) is a feature extraction method for speech and audio analysis. It transforms raw audio signals into a compact representation that captures important frequency and temporal information. Used extensively in tasks like speech recognition, emotion detection, and audio classification, MFCC enhances AI models’ ability to understand and process sound data effectively.
About Me:
Uday Kiran
IIT Madras Graduate | Electric Engineer
Connect with me on Linkedin
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
My name is Uday Kiran, and I am a data engineer with one year of experience. I am a proud graduate of the prestigious Indian Institute of Technology (IIT) Madras, where I earned my Bachelor's degree in Eectrical Engineering.
Throughout my academic and professional career, I have always been passionate about using technology to solve complex problems and improve processes. As a data engineer, I am responsible for designing, implementing, and maintaining data systems and databases that are critical to the success of businesses and organizations. I have experience working with a range of data technologies, including SQL, Python, Hadoop, and Spark, and I am always looking to expand my knowledge and skills in this field.
In addition to my technical expertise, I am a collaborative team player who is committed to delivering high-quality work and meeting project deadlines. I enjoy working with others to identify and solve problems and find innovative solutions to improve processes and efficiency.
Outside of work, I enjoy staying active and engaged in my community. I am an avid sports fan and enjoy playing cricket and badminton. I also volunteer my time with local organizations that work to improve access to education and healthcare for underserved communities.
Overall, I am a dedicated and passionate data engineer with a strong foundation in computer science and a commitment to continuous learning and growth in my field.






Ah, thanks for the easy to understand article But why do we take the inverse DFT ? From what I can decipher, we compute the DFT coeff of the audio/speech signal and perform some sort of filtering by using filter banks, and then take the log of the responses obtained. Similar to a low-pass filter that we can use on an image. To get back to our original domain, we compute the IDFT Is this correct ?