This article was published as a part of the Data Science Blogathon
Overview
In this blog, I will be briefly explaining the concepts of MLOps and how to productionize ML models in laymen and easy-to-understand ways. It is assumed the reader of this blog already has some knowledge of machine learning and AWS cloud services. Machine learning models are experimental in nature, and we need to try multiple models with various hyperparameters to arrive at the best model, yet more than 85% of ML models do not get to production because there is a disconnect between IT and data scientist and most IT organizations are simply unfamiliar with the software tools and specialized hardware, such as Nvidia GPUs, that are required to effectively deploy ML models.
MLOps bridges this Gap and is a process of taking an experimental ML model into production systems by integrating the best practices from Data Scientists, the DevOps team, and machine learning engineers to work in cohesion to transition the algorithms to production systems. Thus MLOps cover end-to-end life cycle stages of machine learning models as listed below.
· Train Model
· Package (Versioning) Model
· Validate (Testing) Model
· Deploy Model
· Monitor (Models may degrade over time due to high data variability) Model
· Retrain Model
Let us now understand few formal terms often used in MLOps workflow.
DevOps: DevOps is a combination of development and operations practices and tools designed to increase an organization’s ability to deliver applications and services faster than traditional software development processes. It shortens the system development life cycle while delivering features, fixes, and updates frequently in close alignment with business objectives.
ML Pipelines: Machine learning a sequential process. ML Pipeline is the process of automating the multiple ML steps like data extraction, pre-processing, and deployment to finally produce a final ML model.
CI, CD, and CT of MLOps: The full benefits from DevOp’s shortened development cycle and increased deployment with dependable releases, are achieved using two concepts in the software development, CI – Continuous Integration and CD -Continuous delivery. ML system is very similar to software systems in CI (source versioning, testing) and CD (packaging), however, in ML there is another component CT (Continues training) as the model may degrade over time due to high data variability. So in the ML system
CI is more of testing and validating data and models.
CD is more about training a pipeline (instead of a single s/w package) and automatically deploy a model prediction service.
CT is unique to the ML system and does the job of automatic model retraining whenever the set model threshold is breached.
MLOps Maturity Model Levels

As per google papers, MLOps maturity can be measured in three phases:
Level 0: Here there are no MLOps, but everything is manual.
Level 1: At this level, the team can do
- Rapid Prototyping and experimentation
- Continuous model orchestration and training
- Fully managed feature store and model metadata
Level 2: In this level, CI, CD, CT pipeline automated.
- Complete End to End pipeline with automated decision-making in Staging and Production.
- Automatically retrain and deploy new models.
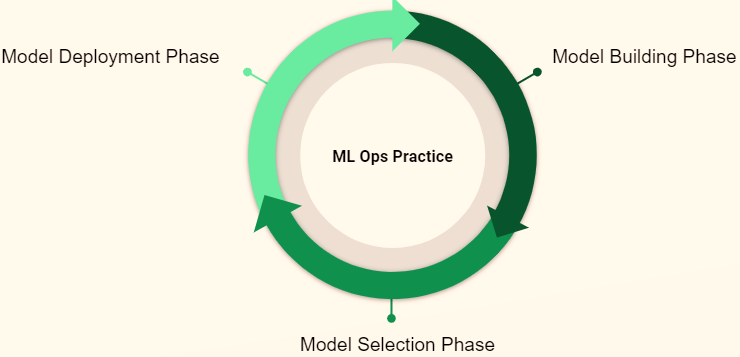
Different phases of MLOps
· Model Building phase: Data scientist Build ML models as per business needs, use on-premise computer instance using Jupyter notebook or ML models in a cloud instance.
· Model Selection Phase: In this phase, the data scientist would have created multiple models and it is time to select the best model based on the chosen evaluation metrics.
· Model Deployment Phase: In this phase, the best ML model identified above needs to be deployed to automate the ml flow process. The Deployment would usually be creating a Docker Image of the ML Model from External ML Libraries (Sci-Kit Learn/TensorFlow) or by making use of the Cloud Native ML Algorithms’ Image if external ML Libraries (Sci-Kit Learn/TensorFlow) are not used and creating an endpoint on a Cloud Platform like AWS, GoogleCloud or Azure
MLOps sample code using AWS SageMaker
Below a sample code snippet from AWS Sagmaker depicting MLOps – 0.
This is just a reference (placeholder) code to understand the underlying concept
1. Import all the necessary packages & libraries.
Import numpy as np
Import pandas as pd
Import matplotlib.pyplot as plt
from IPython.display import Image
from IPython.display import display
from time import gmtime,strftime
import sys
import math
import Json
import boto3
import sagemaker
session =sagemaker.Session() # establish Sagemaker session
region = session.boto_region_name # get region name
bucket = ‘mlopsbucket’ # s3 bucket
prefix = ’sagemaker/mlops-sample’
role = sagemaker.get_execution_role() # get permission
2. Load your dataset & do pre-processing
Raw_data_ filename = ‘ YOUR .csv DATA’
s3 = boto.resource(‘s3’,region_name=region)
s3.bucket(bucket).download_file(raw_data_filename,’mlops.csv’) # download the dataset from s3 bucket to notebook instance
data = pd.read_csv(‘./mlops.csv’) # Now you can do regular pre-processing like shape, Nan’s,feature engineering,categorical and numerical data handling etc
…………………….
……………………
……………………
3. Splitting the dataset to train , validation and test 70:20:10
train_data,validation_data,test_data = np.split(data.sample(frac=1,random_state=42),
[int(0.7*len(data)),int(0.9*len(data))])
4. Build xgboost and linear learner model
# xgboost model using sagemaker
From sagemaker.amazon.amazon_estimator import get_image_uri # docker image
container = get_image_uri(region,’xgboost’)
xgb = sagemake.estimator.Estimator(container,
role,
base_job_name = ‘xgboost model’,
train_instance_count = 1, # Number of instance to train
train_instance_type = ‘m1.c5.xlarge’, # type of server cpu,gpu etc
output_path =’s3//{}/{}/output’.format(bucket,prefix),
sagemaker_session=session)
xgb.set_hyperparameters(max_depth =5,
eta=0.1,
subsample=0.5,
eval_metric=’auc’,
objective=’binary:logistic’,
scale_pos_weight=2.0,
num_round=100)
xgb.fit({‘train’:s3_input_train,’validation’:s3_input_validation}) # initiate training job
# linear learner model
container = get_image_uri(region,’linear-learner:latest’)
linear = sagemaker.estimator.Estimator(containers[boto3.Session().region_name],
role=role,
train_instance_count=1,
train_instance_type='ml.p2.xlarge',
output_path=output_location,
sagemaker_session=sess)
%%time
linear.set_hyperparameters(feature_dim=2,
mini_batch_size=4,
predictor_type='binary_classifier')
linear.fit({'train': s3_train_data})
5. Monitor the training jobs either through console (in AWS) or through API
import boto3
search_params={
"MaxResults": 10, # number of training jobs running
"Resource": "TrainingJob",
"SearchExpression": {
"Filters": [{
"Name": "TrainingJobName",
"Operator": "Contains",
"Value": "xgboost"
}]},
"SortBy": "Metrics.train:binary_classification_accuracy",
"SortOrder": "Descending"
}
smclient = boto3.client(service_name='sagemaker')
results = smclient.search(**search_params)
6. Suppose we got xgboost as best model then next step is to deploy the model and create an end point
Xgb_predictor = xgb.deploy(initial_instance_count=1,
Instance_type =’ml.m5.xlarge’)
Check if the Endpoint is created
As we automate the stages mentioned above, using pipeline we will move to a higher level of MLOps maturity
Conclusion:
MLOps is a growing area that will gain momentum in the future. The main goal of MLOps is to use ML models more efficiently to solve business problems. Some of the best practices are listed below
1. Create models with reusable ML pipelines
2. Automatically create audit trails
3. Display and Monitor Performance
4. Observe data shift
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.



{kind=link}