This article was published as a part of the Data Science Blogathon
Introduction
Data from the internet forms a huge source of information these days. We have an overwhelming amount of data available, which includes text, audio, and videos. Text information forms a major source of information amongst these. Natural language processing includes the task of analyzing, modifying, and deriving conclusions from text data.
These text or speech data are completely unstructured and messy. A great amount of effort is required to process and manipulate these data. Nevertheless thanks to the Natural Language Toolkit(NLTK) written in Python language, which makes these cumbersome tasks a smooth one. It is a Python package used for Natural language processing.
It helps in making a machine understand human language. Major areas where NLP is applied include Sentimental Analysis, Recommendation systems, Autocorrect in search Engines like google, Hiring process by Naukri, Chatbots, Spam detection in Gmail, Text Predictions, etc.
Let us look at the various operations and text analysis processes involved in NLP.
1. Tokenization
A sentence in the English language is formed by a group of meaningful words. These words are composed of tokens, which build up a sentence. Tokenization is a process which involves breaking down the entire raw text into small units which can be used for processing purpose.
There are two functions available in tokenization.
a. word_tokenize()
The entire raw text is converted into a list of words. Punctuations are also considered words during tokenization. This helps in the easy removal of punctuations which might not be necessary for analysis.
Tokenizing in Python is fairly simple. Take a close look at the below code sample.
import nltk corpus = """Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from structured and unstructured data,and apply knowledge and actionable insights from data across a broad range of application domains. Data science is related to data mining, machine learning and big data. Data science is a "concept to unify statistics, data analysis, informatics, and their related methods" in order to "understand and analyze actual phenomena" with data.It uses techniques and theories drawn from many fields within the context of mathematics, statistics, computer science, information science, and domain knowledge. However, data science is different from computer science and information science.Turing Award winner Jim Gray imagined data science as a "fourth paradigm" of science (empirical, theoretical, computational, and now data-driven) and asserted that "everything about science is changing because of the impact of information technology" and the data deluge""" # Tokenizing words words= nltk.word_tokenize(corpus)
I have taken a part of the text from Wikipedia regarding Data science and trying to tokenize it into words. nltk provides a function called word_tokenize(), which accepts any text and splits it into a list of words.
Let us execute the same in Python and see how the result looks like.

As you can see, even the punctuations are treated as a word. If you want to remove all punctuations, use the below code.
import string
word=[]
for i in words:
if i not in string.punctuation:
word.append(i)

string.punctuation consists of a list of punctuations(‘!”#$%&'()*+,-./:;<=>?@[\]^_`{|}~‘), which can be removed from the list of words. Now the new list of words is only alphanumeric characters.
b. sent_tokenize()
Similar to the above process where we try to extract each word from the entire text, sentence tokenization returns a list consisting of individual sentences of the entire text.
Let us try to read a text file and split the content into sentences.
alice_book=open(r"C:UsersXXXXXDocumentsalice_in_wonderland.txt","r")#create a handle for the text file book=alice_book.read()#Read the file content sentences = nltk.sent_tokenize(book)#Sentence tokenize the content
Let us execute the above code in Jupiter Notebook and examine the output.

sent_tokenize() creates a comma-separated list of sentences.
Each sentence can now be accessed using the indexing of the list. For instance, sentences[0] gives access to the first sentence in the text.
Let us execute the same and see the output

Let us remove the escape sequence characters present in the sentence. we will take the help of the word_tokenize() function to achieve this task.
for i in range(len(sentences)):
words = nltk.word_tokenize(sentences[i])
words = [word for word in words if word.isalnum()]
sentences[i] = ' '.join(words)
Each sentence is further condensed down to words using word_tokenizer(), and each word is checked whether it is an alphanumeric character or not. A new sentence is built which only has words separated by words, escape character being removed. The process is repeated for the entire list of sentences.
Execution of the above code gives the following result.

Having a clear idea of how tokenization is performed, let us move on to see what other features are available for NLP.
2. Lemmatization
To understand lemmatization, let us see what it really means. The Wikipedia definition of Lemmatization says, “Lemmatisation (or lemmatization) in linguistics is the process of grouping together the inflected forms of a word so they can be analyzed as a single item, identified by the word’s lemma, or dictionary form“.
Let us see how lemmatization is performed in Python.
import nltk
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
lemmatizer = WordNetLemmatizer() #Initialize the lemmatizer
# Lemmatization
for i in range(len(sentences)): #Loop through each sentence
words = nltk.word_tokenize(sentences[i]) #Extract each word from the sentence
words = [lemmatizer.lemmatize(word) for word in words if word not in set(stopwords.words('english'))] #Lemmatize each word
sentences[i] = ' '.join(words)

WordNetLemmatizer() consists of lemmatize() function, which takes words and return their lemma form. The sentences which were cleaned during sentence tokenization are now converted into their lemma form. Stopwords are articles, conjunction, and prepositions that are not important for sentence analysis. These stop words are first removed and the lemma form of words are saved in the sentences list.
Take a closer look at the first sentence now, pictures are converted to their lemma form picture, same with conversations.
3. Stemming
Wikipedia definition of stemming says, “In linguistic morphology and information retrieval, stemming is the process of reducing inflected (or sometimes derived) words to their word stem, base or root form”.
Let us see how stemming can be performed in Python.
import nltk
from nltk.stem import PorterStemmer
from nltk.corpus import stopwords
stemmer = PorterStemmer() #Initialize stemmer
# Stemming
for i in range(len(sentences)): #Loop through each sentence
words = nltk.word_tokenize(sentences[i]) #Extract each word from the sentence
words = [stemmer.stem(word) for word in words if word not in set(stopwords.words('english'))] #Find the stem of each word
sentences[i] = ' '.join(words)
The result looks as shown below.

The syntax almost remains the same as lemmatization, except PortStemmer is used for the task. The sentence now looks a lot different from the lemma form of it. For example base word for sitting is sit, picture is picture etc.
Now let us move on to some advanced concepts of NLP.
4. Bag of words
Let us understand the concept of bag-of-words using the below three sentences.
Sentence 1: It is better to learn Data Science.
Sentence 2: It is best to learn Data Science.
Sentence 3: It is excellent to learn Data Science.
Let us first remove stopwords from these three sentences.
Sentence 1: better learn Data Science.
Sentence 2: best learn Data Science.
Sentence 3: excellent learn Data Science.
Now Bag of words creates a matrix, which shows the occurrence of a particular word in the given sentence.
For example, there are 5 unique words in all the sentences above. They form the column names for the matrix, each sentence 1,2,3 forms the row of the matrix.
The table looks as below.

A count of 1 represents the occurrence of that word in the corresponding
sentence. A 0 represents the non-occurrence of the word in that sentence.
Let us see how to implement this in Python.
sentence=['better learn Data Science', 'best learn Data Science', 'excellent learn Data Science' ]
import nltk
from nltk.stem import PorterStemmer
from nltk.corpus import stopwords
stemmer = PorterStemmer() #Initialize stemmer
# Stemming
for i in range(len(sentence)): #Loop through each sentence
words = nltk.word_tokenize(sentence[i]) #Extract each word from the sentence
words = [stemmer.stem(word) for word in words if word not in set(
stopwords.words('english'))] #Find the stem of each word
sentence[i] = ' '.join(words)
The data is cleaned as in the previous case, where stopwords are removed and each word is converted to its stem form.
The sentence looks as shown above in the output.

Let us see how to perform a bag of words in Python.
from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer() X = cv.fit_transform(sentence).toarray()
CountVectorizer() function from the sklearn library helps perform the bag of words operation. Convert the output into an array to see the matrix representation.

In machine learning, any data which helps us in prediction or drawing any conclusion is treated as a feature. In NLP, every unique word in the above sentence is taken as a feature and a matrix is created as shown in array X. We can get these feature names using the get_feature_names() function of the count vectorizer.
These unique words can also be called vocabulary. When we have a huge amount of data, we can select our vocabulary size as shown below.
cv=CountVectorizer(max_features=1000)
The above instruction says, select only 1000 unique words to form the matrix.
5. TF-IDF
TF stands for Term Frequency and IDF stands for Inverse Document Frequency.
It is calculated as below.

Let us understand how to apply this formula to our sentences in the previous example.
better learn data science
best learn data science
excel learn data science
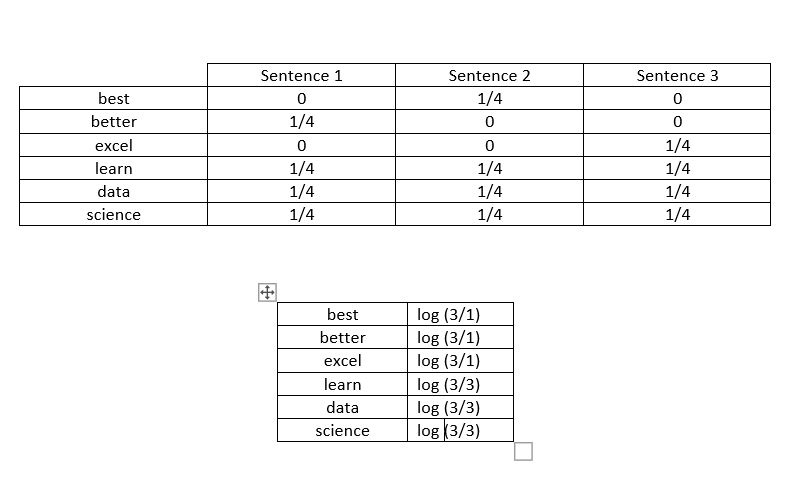
Let us analyze the term frequency table(table 1). The word ‘best’ does not appear in sentences 1 and 3, so TF is 0, whereas it appears once in sentence 2 and there are 4 words in the sentence, so the value is 1/4. Similarly for the IDF table(table 2), ‘best’ appears only once in sentence 2 and there are 3 sentences in total, so IDF is calculated as log(3/1).
Let us use the same sentence which was cleaned for the bag of words process and perform TF-IDF on the same.
The python code looks as shown below.
from sklearn.feature_extraction.text import TfidfVectorizer cv = TfidfVectorizer() X = cv.fit_transform(sentence).toarray()
We can obtain the unique words in the document with the help of the get_feature_names() function.
cv.get_feature_names()
['best', 'better', 'data', 'excel', 'learn', 'scienc']
TfidfVectorizer from the sklearn library is used to operate. Let’s convert this into an array.

In TF-IDF preference is given to those words which are less common in the sentence.
Note that for words ‘data’, ‘science’, and ‘learn’ the values are not completely 0 as we calculated previously, instead the algorithm tries to normalize the TF-IDF values in such a way that more common words are given a lower value when compared to less common words.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.




