This article was published as a part of the Data Science Blogathon
Introduction
This article focuses on answer retrieval from a document by using a similarity algorithm. This task falls under Natural Language Processing which is a subset of Deep Learning. In this article, we will be understanding why do we require better techniques and what are the drawbacks of using naive algorithms. Moreover, we will be implementing a similarity-based technique for answer retrieval from the document.
This article is a follow-up to NLP: Answer Retrieval from Document using Python. I strongly recommend giving it a fast read.
Why do we need a new matrix?
Problems with Euclidean Distance
If two data vectors have no component values in common, they may have a smaller distance than the other pair of data vectors containing the same component values.
Let’s say for example we have three vectors → A (1, 0 , 0) , B (0 , -2 , -2) , C (10 , 0 , 0).
Can you visualize these vectors in a 3-D plane? Good!
Now let’s calculate the distance
distance (A , C) = 9 units
distance (A , B) = 3 units
So according to the Euclidean Matrix vector, A and B are closer or more similar than vectors A and C.
Is it True?
Off-Course Not. we can clearly see that vectors A and C are in the same direction it’s just that their magnitude is different. Now let’s see it in word embedding perspective than you can visualize it like – vector or sentence A has a word ‘Born’ and vector B has words ‘Dead Dead End End’ while vector C has word ‘Generated’ or ‘Born’ 10 times. Then will conclusion from Euclidean distance will be considered true. NO.
So, in this kind of situation Euclidean distance Fail.
The key issue here is that the Euclidian norm gives the same importance to any direction. So as dimensionality increases Euclidean distance cannot be used effectively.
Problems with Cosine Similarity
The major disadvantage with cosine similarity is that it does not take magnitude into account. We have seen that cosine similarity is directly proportional to the inner product of the two vectors but do not take into account the difference in their lengths it’s just only focused on orientation.
Let’s say for example we have three vectors → A(10, 20, 30), B(100, 200, 300), C(1, 2, 3).
Can you visualize these vectors in 3-D space? Good!
Which two vectors do you think are similar according to Cosine Similarity?
The answer is all 3. Cosine similarity will give the same result because in 3d space they have angle 0 between them. Cosine Similarity will not be able to further discriminate these vectors. But we can clearly see that vector A and vector C will be closer to each other as compared to any other combination of A, B, C. This is the major drawback with cosine similarity.
So Cosine Similarity also fails.
The key issue is focused only on orientation without taking into account the magnitude of vectors.
Let’s Visualize the Use Cases
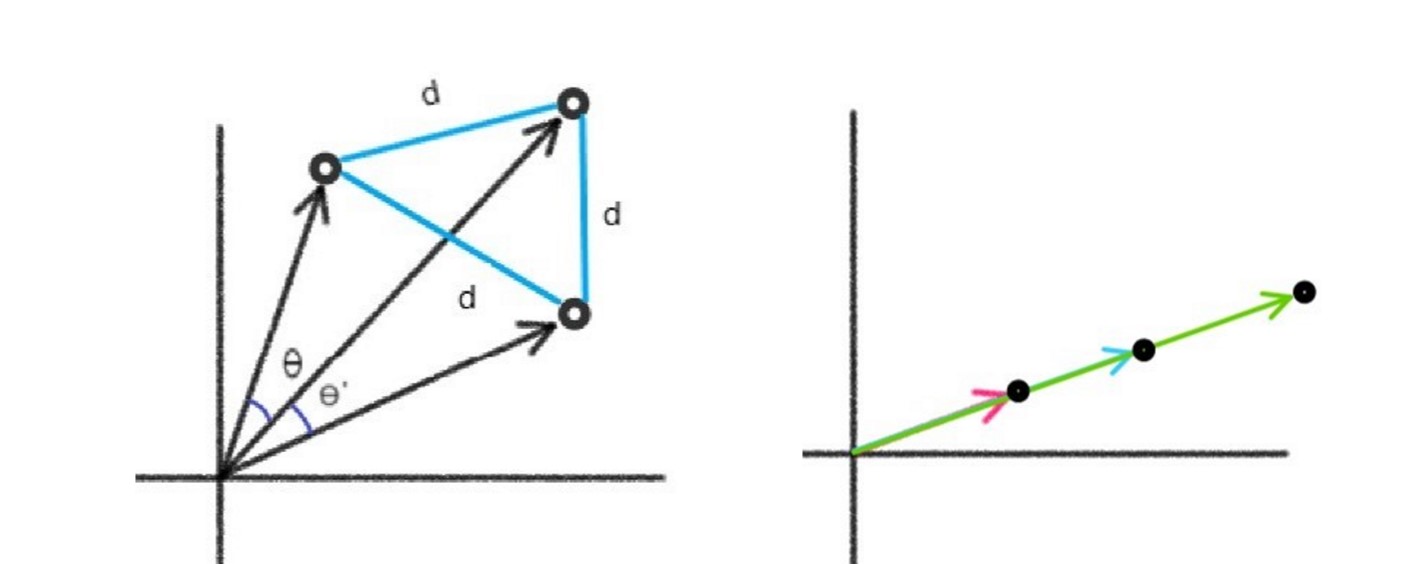
In image 1 we can see that we have different angles and the same distances between angles so in these cases it is valid to use cosine similarity instead of Euclidean because we won’t be getting any useful inference from it.
In image 2 we can see that angle between 3 vectors is 0 so if we use cosine similarity it will say they both are the same and we will get no inference about our case. So here we can not use cosine similarity effectively but we can surely use Euclidean distance because that will give us a non-zero value.
We will not be able to separate these problems while dealing with data. That’s the main reason why we require a better matrix for judging text similarity.
From the above discussion, we can surely say we want some algorithm that can combine both metrics. This is exactly what TS-SS Similarity Algorithm does. Let’s see what is TS-SS.
TS-SS Similarity
TS-SS stands for Triangle Area Similarity – Sector Area Similarity.
According to the paper,
A Hybrid Geometric Approach for Measuring Similarity Level Among Documents and Document Clustering. TS-SS computes the similarity between two vectors from diverse perspective and generates the similarity value from two vectors not only from the angle and Euclidean distance between them, but also the difference between their magnitudes.
Let’s start our discussion with TS in TS-SS.
TRIANGLE AREA SIMILARITY
Triangle area similarity includes three major characteristics for computing similarity
1. Angle
2. Euclidean Distance between vectors
3. Magnitude of vectors
The intuition behind the usage of TS is when we draw the Euclidean distance line between two vectors as we have in the figure above we can clearly see that if vectors are closer ED is small, the angle between vectors also changes and even the are of triangle decreases. So all these factors got affected if two vectors come close to each other. It’s wise to incorporate them together to create a metric component. Below is the formula for TS
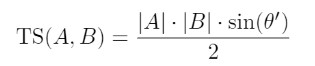
⊖’ = arccos(cosine(A,B)) + 10
For calculating cosine(A,B) we will be using
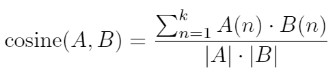
What is 10 in the above ⊖’ calculation?
The whole idea of our calculations completely depends on triangle formation. If we have overlapping vectors ⊖’ will become zero and we will not be having a triangle. So to ensure the formation of the triangle we have added a minimum angle to ⊖’ calculation.
So whenever two vectors come closer to each other the area inside the triangle formed by these vectors decreases proportionally.
SHOW ME THE CODE NOW!
Cosine Similarity
def Cosine(question_vector, sentence_vector):
dot_product = np.dot(question_vector, sentence_vector.T)
denominator = (np.linalg.norm(question_vector) * np.linalg.norm(sentence_vector))
return dot_product/denominator
The output will be a matrix depending upon the dimensions of the vectors used. You can simply take mean in case it is a matrix. You can also refer to code in the algorithmic pipeline section.
Euclidean Distance
def Euclidean(question_vector, sentence_vector):
vec1 = question_vector.copy()
vec2 = sentence_vector.copy()
if len(vec1)<len(vec2): vec1,vec2 = vec2,vec1
vec2 = np.resize(vec2,(vec1.shape[0],vec1.shape[1]))
return np.linalg.norm(vec1-vec2)
The output will be the float value which will represent the Euclidean distance between the two vectors.
You can refer Article for an explanation of the above codes and the creation of the vectors/word-embedding.
Though I will be providing a full code later in this article.
Theta
def Theta(question_vector, sentence_vector):
return np.arccos(Cosine(question_vector, sentence_vector)) + np.radians(10)
In the above code, we have used arccos to find the inverse of cosine that is our angle ⊖’ and we have also added 10 radians according to the formula. The output will be float value.
Triangle
def Triangle(question_vector, sentence_vector):
theta = np.radians(Theta(question_vector, sentence_vector))
return ((np.linalg.norm(question_vector) * np.linalg.norm(sentence_vector)) * np.sin(theta))/2
The output will be float value.
WOAH! So finally TS part is over with the code. Next, we will be looking at the SS part.
SECTOR AREA SIMILARITY
TS will not be able to completely solve our problem because like cosine similarity it is missing an important component which is the difference in magnitude of vectors. TS can be understood as an enhancement to cosine similarity but we also have to combine Euclidean distance, which will be covered in this part.
The formula for Magnitude Difference
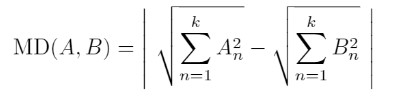
According to creators, summation of Magnitude Difference and Euclidean Difference when rotated with angle (formed between the two vectors) gives us a sector. And this sector can be used as a similarity metric. This means that we will be having a sector with radius = ED+MD, and angle of rotation as ⊖’.
So Formula for SS will come out to be
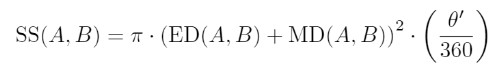
Let’s see the CODE now.
Magnitude Difference
def Magnitude_Difference(vec1, vec2):
return abs((np.linalg.norm(vec1) - np.linalg.norm(vec2)))
The output will be float value representing the difference between the two vectors.
Sector Area Similarity
def Sector(question_vector, sentence_vector):
ED = Euclidean(question_vector, sentence_vector)
MD = Magnitude_Difference(question_vector, sentence_vector)
theta = Theta(question_vector, sentence_vector)
return math.pi * (ED + MD)**2 * theta/360
The output will be float value representing sector area.
TS-SS METHOD
We multiply TS and SS together for the calculation of TS-SS similarity. TS and SS fulfill each other’s flaws and hence perform better than Cosine and Euclidean similarity techniques. The reason for choosing multiplication over summation is that in some cases value of TS and SS is disproportionate to each other where one becomes extremely large than the other.
Range of TS-SS if from 0 to ∞ (infinity)
similarity_value = Triangle(question_vector,sentence_vector) * Sector(question_vector,sentence_vector)
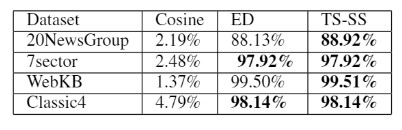
Results Comparison
When TS-SS, Cosine Similarity, and Euclidean Distance are applied to the below-mentioned datasets we found that in most cases TS-SS performed better, the same is shown in the table below.
Datasets :
1. 20NewsGroup
2. 7sector
3. WebKB
4.Classic4
Algorithmic Pipeline
1. Convert paragraph into sentences matrix.
2. Cleaning the data.
3. Conversion of sentences to corresponding word embedding
4. Conversion of question into the word embedding
5. Apply TS-SS similarity
6. Put the results in heap with index.
7. Pop and Print the result.
This will be the whole pipeline for our code.
You can find my complete code
Kaggle : Click Here (Like + Comment)
Github : Click Here (Star + Fork)
More similar the words in question to document better will be the accuracy.
EndNote
With TS-SS we successfully combined features of Cosine Similarity and Euclidean Distance. We were able to increase the accuracy of the answering system without increasing time complexity. If you still want to increase the accuracy for the proper context-based answering system then you should have to pay the computational cost for it because that would require advanced models like BERT, XLNET, etc.
This model can be used for creating applications like Plagiarism Checker, Fill-in-the-blanks solver, finding solutions from Comprehensions, etc.
Thank You for giving your precious time.
Hope You like it.
References
[1] A. Heidarian and M. Dinneen, “A Hybrid Geometric Approach for Measuring Similarity Level Among Documents and Document Clustering,” in 2016 IEEE Second International Conference on Big Data Computing Service and Applications (BigDataService), Oxford, United Kingdom, 2016 pp. 142-151.
doi: 10.1109/BigDataService.2016.14
url: https://doi.ieeecomputersociety.org/10.1109/BigDataService.2016.14
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.



