This article was published as a part of the Data Science Blogathon
Overview
In the previous two installments, we had understood in detail the common text terms in Natural Language Processing (NLP), what are topics, what is topic modeling, why it is required, its uses, types of models and dwelled deep into one of the important techniques called Latent Dirichlet Allocation (LDA).
In this last leg of the Topic Modeling and LDA series, we shall see how to extract topics through the LDA method in Python using the packages gensim and sklearn.

Table of Contents
- Data and Steps for Working with Text
- The Work Flow for executing LDA in Python
- Implementation of LDA using gensim
- Parameters for LDA model in gensim
- Implementation of LDA using sklearn
- Parameters for LDA model in sklearn
Data and Steps for Working with Text
We will apply LDA on the corpus that we have seen in the previous articles:
- Document 1: I want to watch a movie this weekend.
- Document 2: I went shopping yesterday. New Zealand won the World Test Championship by beating India by eight wickets at Southampton.
- Document 3: I don’t watch cricket. Netflix and Amazon Prime have very good movies to watch.
- Document 4: Movies are a nice way to chill however, this time I would like to paint and read some good books. It’s been so long!
- Document 5: This blueberry milkshake is so good! Try reading Dr. Joe Dispenza’s books. His work is such a game-changer! His books helped to learn so much about how our thoughts impact our biology and how we can all rewire our brains.
The Work Flow for executing LDA in Python
-
After importing the required libraries, we will compile all the documents into one list to have the corpus.
-
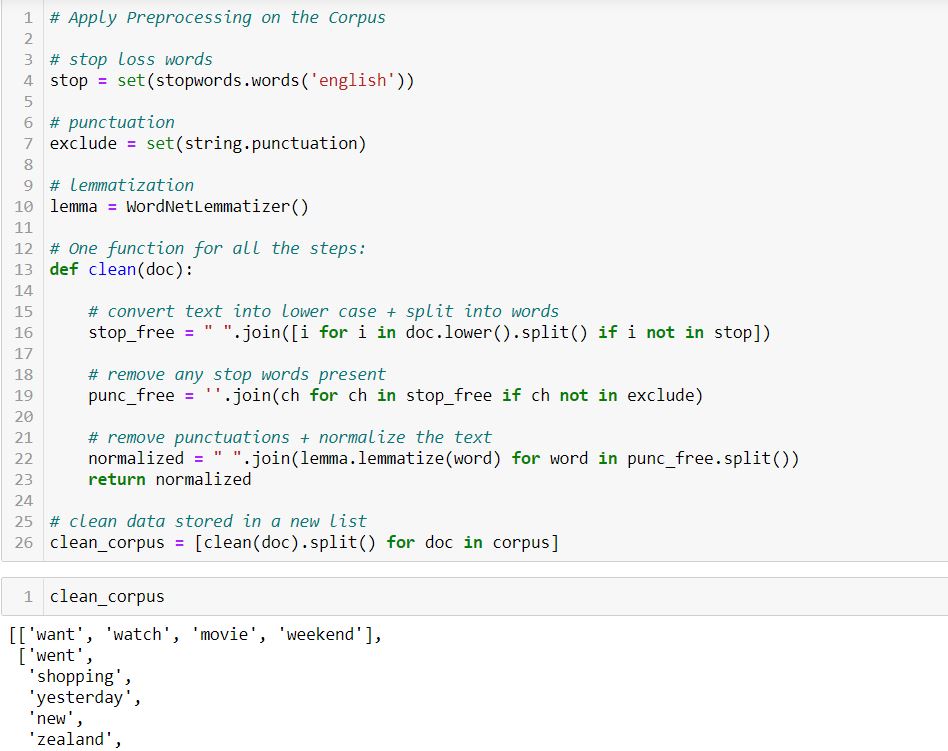
We will perform the following text preprocessing steps (can use either spacy or NLTK libraries for preprocessing):
- Convert the text into lowercase
- Split text into words
- Remove the stop loss words
- Remove the Punctuation, any symbols, and special characters
- Normalize the word (I’ll be using Lemmatization for normalization)
The next step is to convert the cleaned text into a numerical representation where the process for gensim and sklearn packages differ:
-
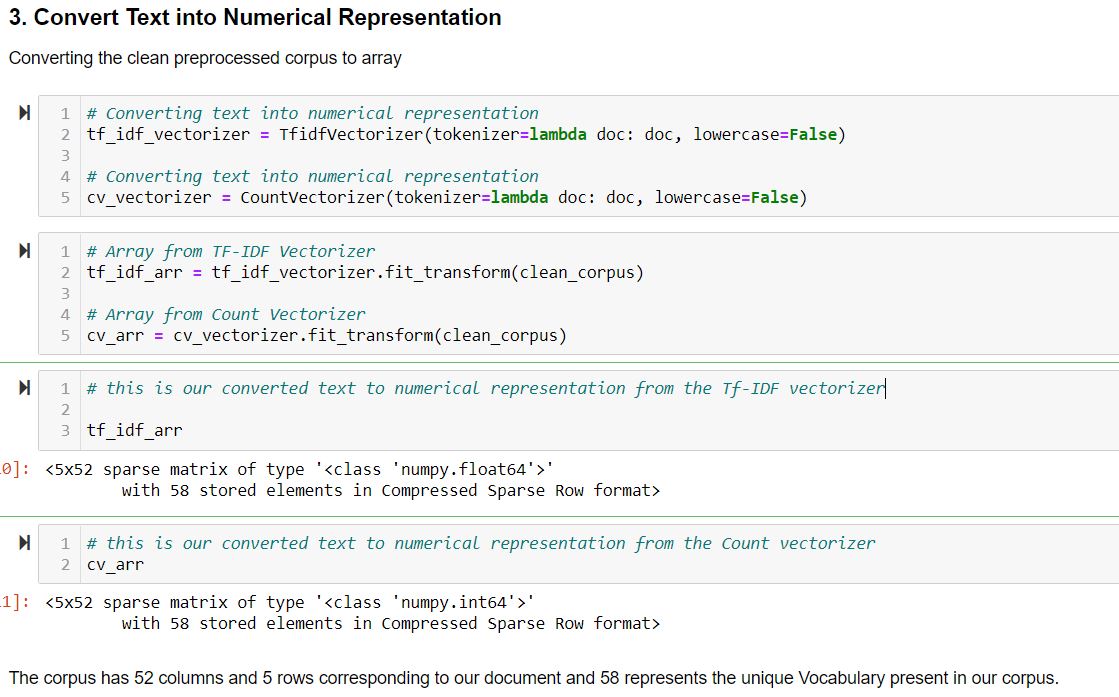
For sklearn: Use either the Count vectorizer or TF-IDF vectorizer to transform the Document Term Matrix (DTM) into numerical arrays.
-
For gensim: Using gensim for Document Term Matrix(DTM), we don’t need to explicitly create the DTM matrix from scratch. The gensim library has an internal mechanism to create the DTM.
The only requirement for the gensim package is that we need to pass the cleaned data in the form of tokenized words.
-
Next, we pass the vectorized corpus to the LDA model for both the packages gensim and sklearn.
We will see the codes for the above steps and codes can be accessed from my GitHub repository.
Common Text Pre-processing steps for both the packages:
Let’s turn to each of the specific packages and see what are the parameters used in Python for LDA …
Implementation of LDA using Gensim
-
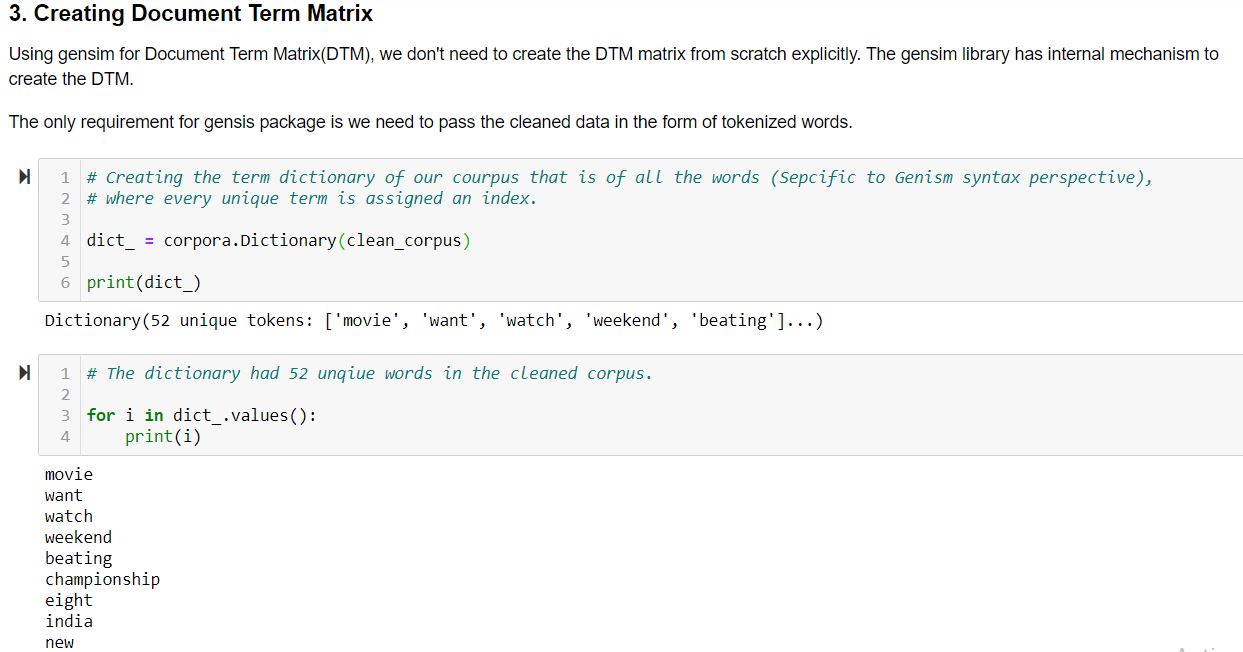
After preprocessing the text, we don’t need to explicitly create the document term matrix (DTM). Gensim package has an internal mechanism to create the DTM.
-
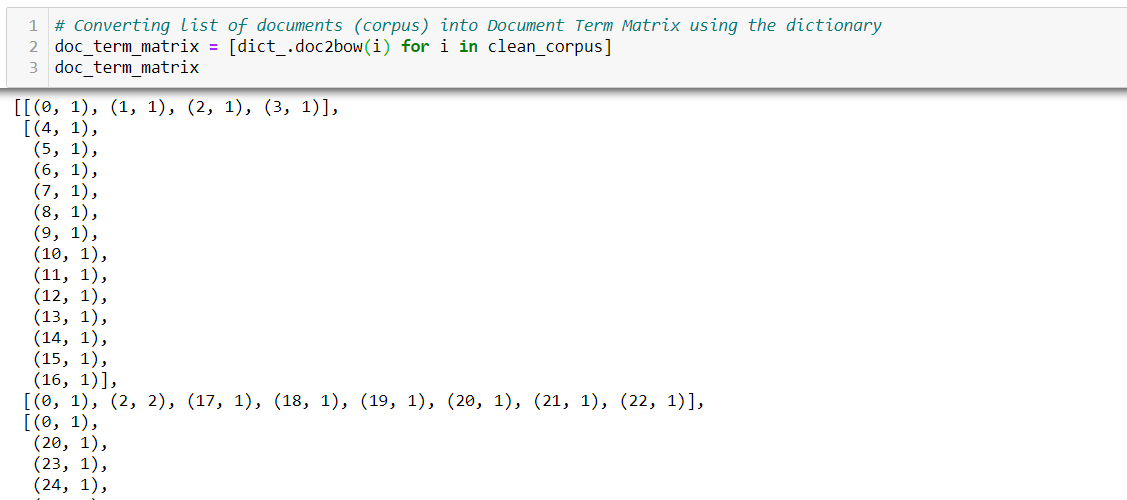
The next step is to convert the corpus (the list of documents) into a document-term Matrix using the dictionary that we had prepared above. (The vectorizer used here is the Bag of Words).
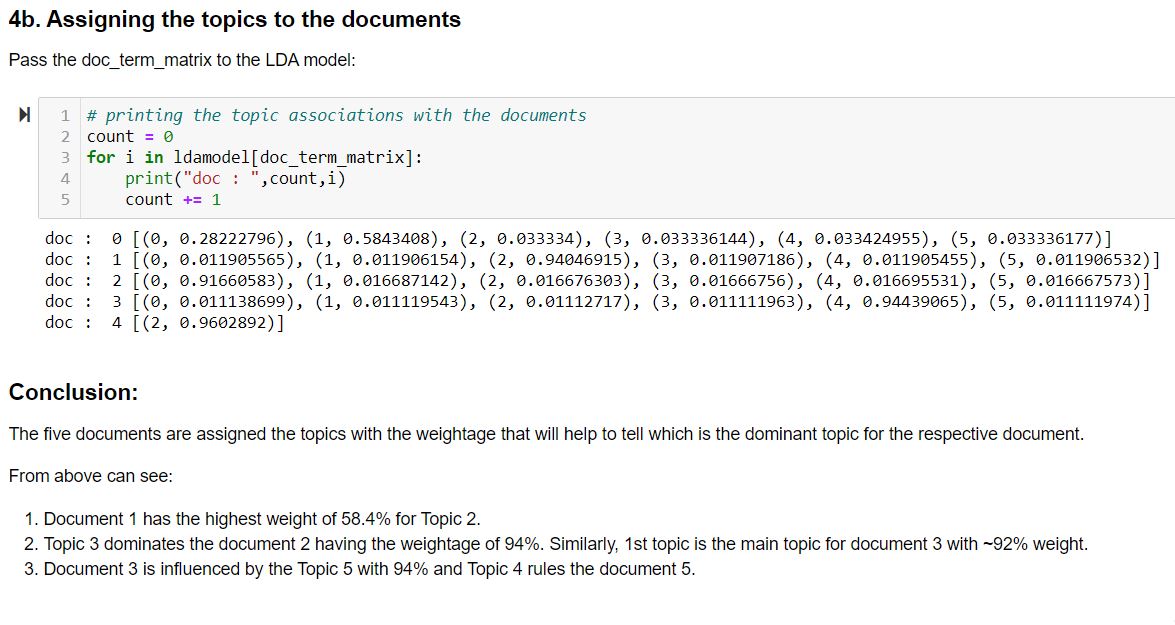
This output implies:
- Document wise we have the index of the word and its frequency.
- The 0th word is repeated 1 time, then the 1st word repeated 1, and so on …
-
Next, we implement the LDA model by creating the object and passing the required arguments:

-
We obtain the following Topics result from the above step 3:

This output means: each of the 52 unique words is given weights based on the topics. In other words, it implies which of the words dominate the topics.
-
Now, we find the topics from Corpus:
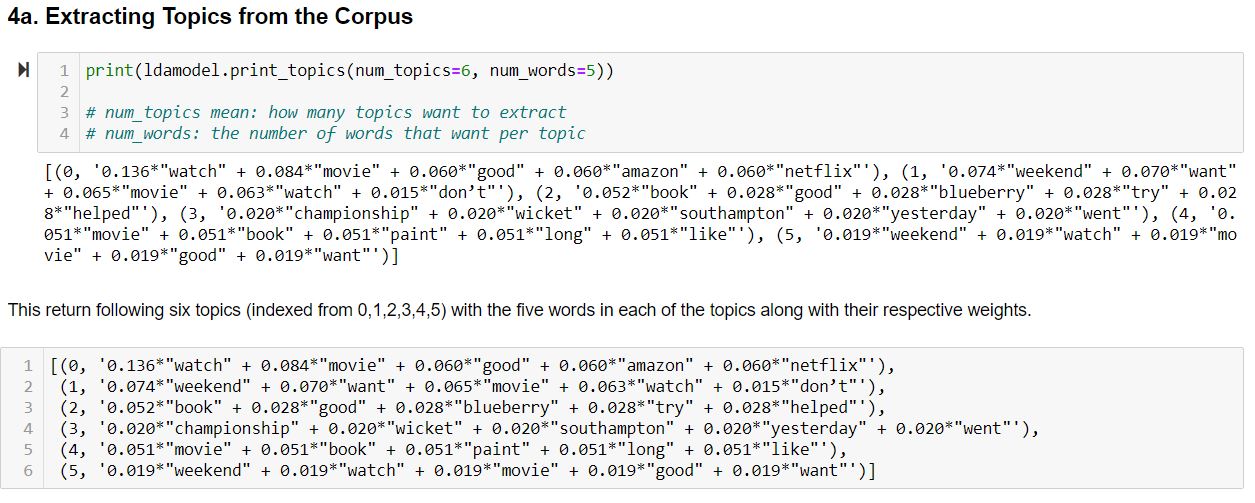
This returns the following six topics (indexed from 0,1,2,3,4,5) with the five words in each of the topics along with their respective weights.
-
Now, we assign these resultant topics to the documents via:
Parameters for LDA model in gensim
Following are the important and commonly used parameters for LDA for implementing in the gensim package:
- The corpus or the document-term matrix to be passed to the model (in our example is called doc_term_matrix)
- Number of Topics: num_topics is the number of topics we want to extract from the corpus.
- id2word: It is the mapping from word indices to words. Each of the words has an index that is present in the dictionary.
- Number of Iterations: it is represented by Passes in Python. Another technical word for iterations is ‘epochs’. Passes control how often we want to train the model on the entire corpus for convergence.
- Chunksize: It is the number of documents to be used in each training chunk. The chunksize controls how many documents can be processed at one time in the training algorithm.
-
LDA’s model parameters:
- Alpha: is the document-topic density
- Beta: (In Python, this parameter is called ‘eta’): is the topic word density
- For, the higher values of alpha —> the documents will be composed of more topics, and
- The lower values of alpha —> returns documents with fewer topics.
Similarly, for the values of Beta:
- The higher beta —> has more number of words in a given topic, and
- The lower value of beta —> topics contains few words.
It is better to keep alpha and beta parameters as ‘auto’ because the model is automatically learning these two parameters.
And, finishing with the implementation on sklearn …
Implementation of LDA using Sklearn
-
In sklearn, after cleaning the text data, we transform the cleaned text to the numerical representation using the vectorizer. I have used both the TF-IDF and the count vectorizer here.
-
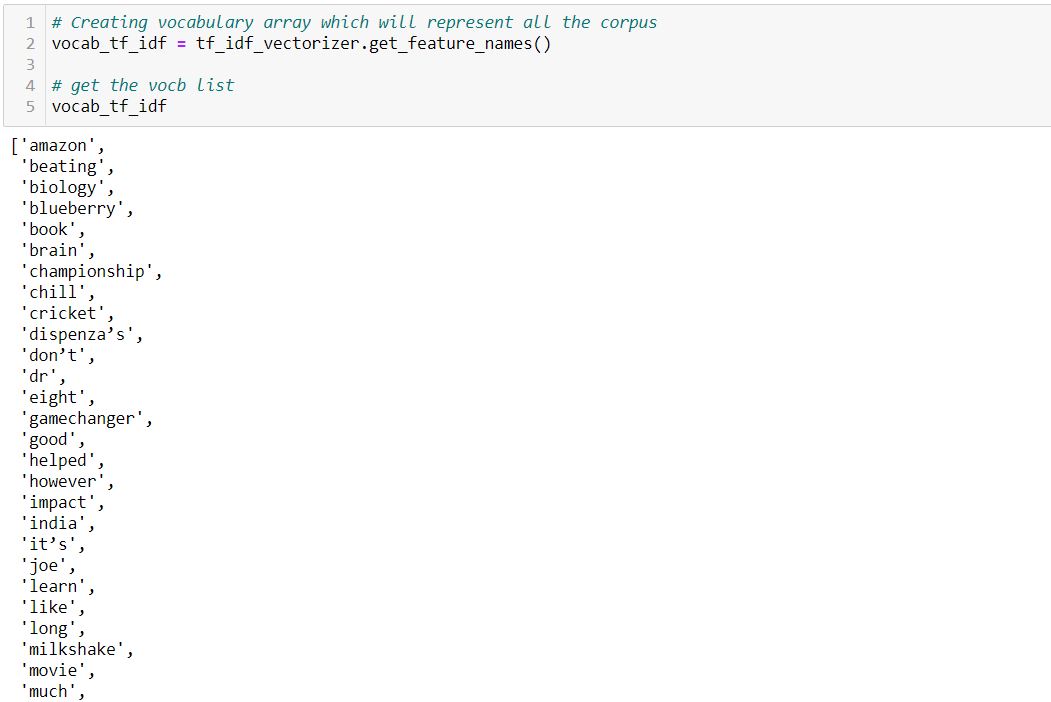
Next, we create the vocabulary:
-
Once we have the vocabulary, we build the LDA model by creating the LDA class:
Inside this class of LDA, we define the components such as how many topics want to retrieve (n_components) and specify the number of iterations that the model must run (max_iter)
Post this, using the saved LDA model, we perform fit_transform on the model on the vectorizer. This returns the topics (called X_topics) and using lda_model.components_ we obtain the topics.

-
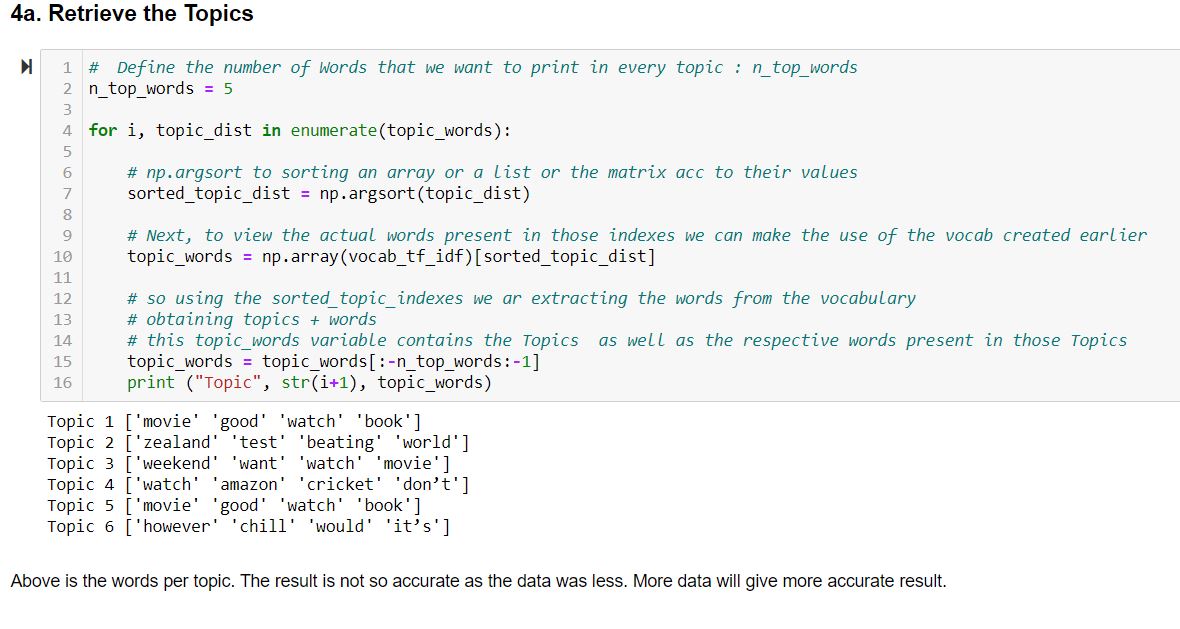
Next, we view the obtained topics using the following steps:
- N_top_words: first define the number of words that want to print on every topic.
- Then, iterate through the documents i.e iterating over topic_words, which we obtained in the last step.
- Each of the topic_word will be represented with a probability, which will indicate the importance of that word in the topic.
- Now, to view the most important words we can either create a sorted array or a sorted topic distribution.
- Next, to view the actual words present in the array, we can use the indexes present in the vocabulary which was created above.
-
Last but not least, the assignment of the topics to the documents:
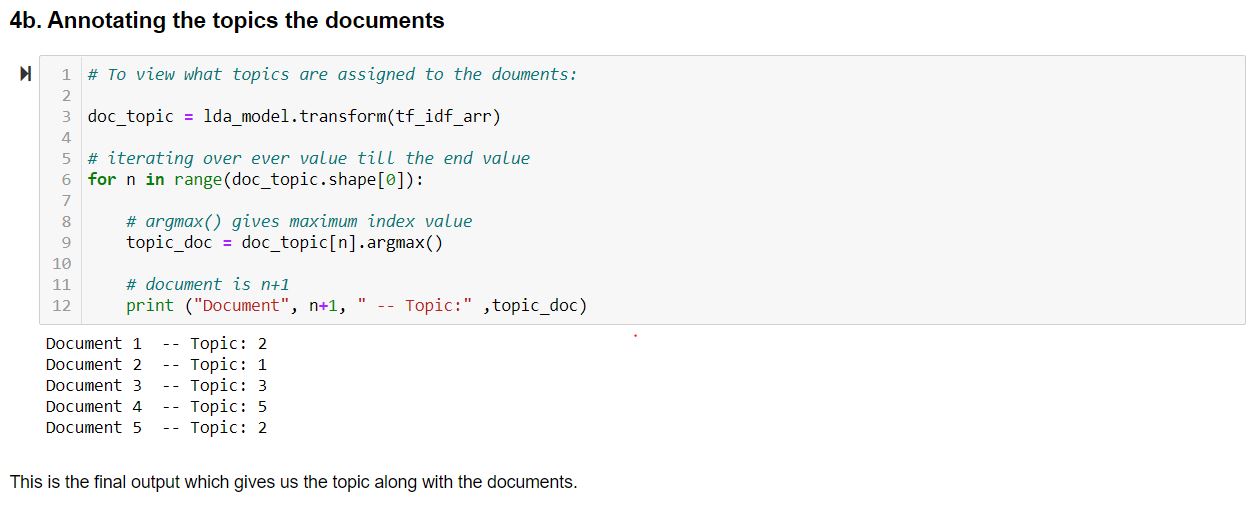
Parameters for LDA model in sklearn
The arguments used in the sklearn package are:
- The corpus or the document-term matrix to be passed to the model (in our example is called doc_term_matrix)
- Number of Topics: n_components is the number of topics to find from the corpus.
- The number of maximum iterations: max_iter: It is the number of maximum iterations allowed for the LDA algorithm to converge.
So, finally, with that, we come to the end of our 3-part series of Topic Modeling and LDA using gensim and sklearn. I hope it was helpful to you and you enjoyed learning as much as I enjoyed writing about it. If you want to share your feedback feel free to use the comments section below or can reach me via Linkedin. Thank You for stopping by to read and helping in sharing the article with your network 🙂
Happy Learning! 🙂
About me
Hi there! I am Neha Seth, a technical writer for AnalytixLabs. I hold a Postgraduate Program in Data Science & Engineering from the Great Lakes Institute of Management and a Bachelors in Statistics. I have been featured as Top 10 Most Popular Guest Authors in 2020 on Analytics Vidhya (AV).
My area of interest lies in NLP and Deep Learning. I have also passed the CFA Program. You can reach out to me on LinkedIn and can read my other blogs for ALabs and AV.
Hi there! I am Neha Seth. I work as a Data Scientist in Larsen & Toubro Infotech (LTI). I hold a Postgraduate Program in Data Science & Engineering from the Great Lakes Institute of Management and a Bachelors in Statistics. I have been featured as Top 10 Most Popular Guest Authors in 2020 on Analytics Vidhya (AV).
My area of interest lies in NLP and Deep Learning. I have also passed the CFA Program. You can reach out to me on LinkedIn and can read my other blogs for AV.




Hi, Thank you, this is very useful. I just wanted to learn how to decide the optimum number of topics. I don't know if there is a similar parameter in Python but as far as I know, there is a coherence value in R, that helps you understand the optimum number of topics you should choose? So can you help regarding this?
Hi Miss Neha Seth I appreciate you because of this very good description you represent to us and it helps me to complete my data science PHD course. thanks a lot
Hi Neha, Very good article. After 4a, I am little confused. What are the names of Topics for index (0,1,2,3,4,5)? I want to know the 6 keywords. Please clarify.