Introduction
Conversing with people having a hearing disability is a major challenge. Deaf and Mute people use hand gesture sign language to communicate, hence normal people face problems in recognizing their language by signs made. Hence there is a need for systems that recognize the different signs and conveys the information to normal people. Let’s discuss sign language recognition from the lens of Computer Vision!
This article was published as a part of the Data Science Blogathon!
Table of contents
What is Sign Language?
People who are deaf often communicate manually using sign language. People who are deaf from different countries speak distinct sign languages, proving that sign language is not universal. In sign language, the motions or symbols are arranged structurally. Every distinct motion is referred to as a sign. The handshape, hands position, and hands movement are the three separate components of each sign. The most widely used sign language in the US is American Sign Language (ASL).
Sign language is a visual language. It mainly consists of 3 major components:
- Fingerspelling: Spell out words character by character, and word level association which involves hand gestures that convey the word meaning. The static Image Dataset is used for this purpose.
- World-level sign vocabulary: The entire gesture of words or alphabets is recognized through video classification. (Dynamic Input / Video Classification)
- Non-manual features: Facial expressions, tongue, mouth, body positions
.png)
Existing Methods of Sign Language Recognition
Identification of sign gesture is mainly performed by the following methods:
- Glove-based method in which the signer has to wear a hardware glove, while the hand movements are getting captured.
- Vision-based method, further classified into static and dynamic recognition. Statics deals with the detection of static gestures(2d-images) while dynamic is a real-time live capture of the gestures. This involves the use of the camera for capturing movements.
The Glove-based method, seems a bit uncomfortable for practical use, despite having an accuracy of over 90%. Hence, in this blog, I will mainly discuss the vision-based approach.
Also Read- A Computer Vision Approach to Hand Gesture Recognition
Static Hand Gesture Detection
Objective : Producing a model which can recognize Fingerspelling-based hand gestures in order to form a complete word by combining each gesture.
1. Alphabets (A-Z) in American Sign Language
Data Collection & Pre-Processing:
We will be using 2 datasets and then compare the results.
Dataset 1: MNIST Dataset : 28×28 pixels images(24 alphabets: J and Z deleted as they include gesture movements: (Dataset) [Training: 27,455 , Testing: 7172]
Dataset 2: Image Dataset: 200×200 pixels images: 29 classes, of which 26 are for the letters A-Z and 3 classes for SPACE, DELETE, and NOTHING. Dataset (J and Z were converted to static gestures by converting only their last frame)
Learning/Modeling : We will use Convolutional Neural Network, or CNN, model to classify the static images in our first dataset.
Why CNN?
- CNN’s are very effective in reducing the number of parameters without losing on the quality of models. Images have high dimensionality (as each pixel is considered as a feature) which suits the above-described abilities of CNNs.
- CNN retains the 2D spatial form of images.
- All the layers of a CNN have multiple convolutional filters working and scanning the complete feature matrix and carry out the dimensionality reduction. This enables CNN to be a very apt and fit network for image classifications and processing.
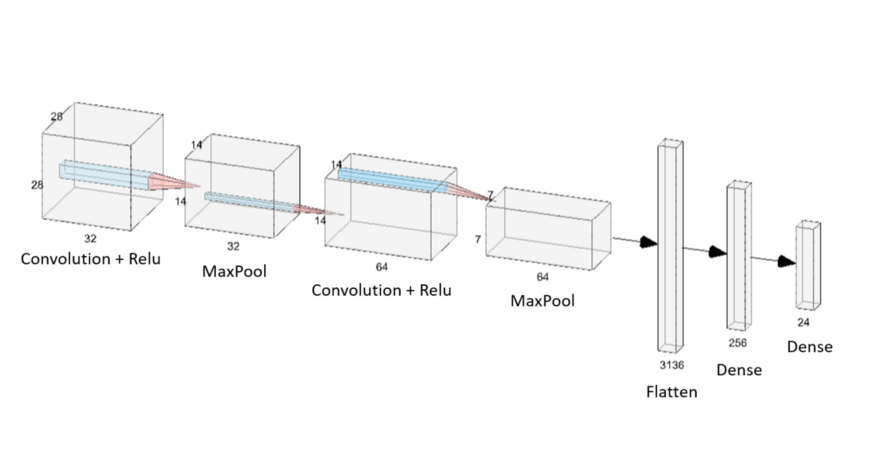
Model
model = Sequential()
#First Convolution Layer
#Learning a total of 64 filters , which is then downsampled by maxpooling layer (2x2)
#kernel_size 3x3 : specifying height and width of 2D convolution window
#padding same: spatial dimensions such that: output value size matches the input volume size
#Relu: activation function used
model.add(Conv2D(64, (3, 3), padding='same', input_shape=(28, 28, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#Second Convolution Layer
model.add(Conv2D(128, (3, 3), padding='same', input_shape=(28, 28, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#Third Convolution Layer
model.add(Conv2D(256, (3, 3), padding='same', input_shape=(28, 28, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#Batch normalization allows every layer of the network to do learning more independently. It is used to normalize the output of the previous layers.
#Flattening : converting 2d array into single long continuous vector
#Dropouts used to avoid overfitting
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dropout(0.5))
#Dense layers produce the output = activation(dot(input, kernel) + bias)
#Used to predict labels
#Softmax activation function used for output labels
model.add(Dense(1024, activation='sigmoid'))
model.add(Dense(classes, activation='softmax')
results(model)Result
| Data Set | Training, Testing Set | Layers CNN | Accuracy |
|---|---|---|---|
| MNIST Dataset(28X28) | 27,455, 7172 | 2 Layer CNN | Train: 95.3% Test: 94.7% |
| 2 Alphabet Images(200×200 pixels) | 78,300, 8700 | A. 3 Layer CNN B. 5 Layer CNN | A. Train: 99.06%Test: 98% B. Train: 97.29%Test: 99.816% |
Observation
The Inferences we can draw from the above results is:
- Two signs of letters such as “M” and “S” are confused and the CNN has some trouble distinguishing them.
- Images of high resolutions are used in Dataset 2 and hence the increase in the model accuracy is seen. As more pixels, allow for more intricate details to be extracted from the images.
Now, we will append classes by adding digits and a few words. We will apply the 5- Layer CNN.
New Result
| Data Set | Training, Testing Set | Layers CNN | Accuracy |
|---|---|---|---|
| ALPHABETS + 10 (0-9) digits (200×200 pixels Images): 38 Classes Dataset | 24026, 1265 | 5 Layer CNN | Train: 97.1% Test: 98.1% |
| 2. ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) 51 classes (200×200 pixels Images) Dataset | 182700, 20300 | 5 Layer CNN | Train: 79.25% Test: 64.84% |
Thus, we can conclude from the above results is:
More object classes make a distinction between classes harder. Additionally, a neural network can only hold a limited amount of information, meaning if the number of classes becomes large there might just not be enough weights to cope with all classes. This justifies the reduction in model accuracy after adding more classes and training data to the dataset.
Thus, to increase the accuracy we will implement Transfer Learning.
What is Transfer Learning?
A pre-trained model that has been trained on an extremely large dataset is used, and we transfer the weights which were learned through hundreds of hours of training on multiple high-powered GPUs.
We will use Inception -V3 Model for classification: Trained using a dataset of 1,000 classes from the original ImageNet dataset which was trained with over 1 million training images.
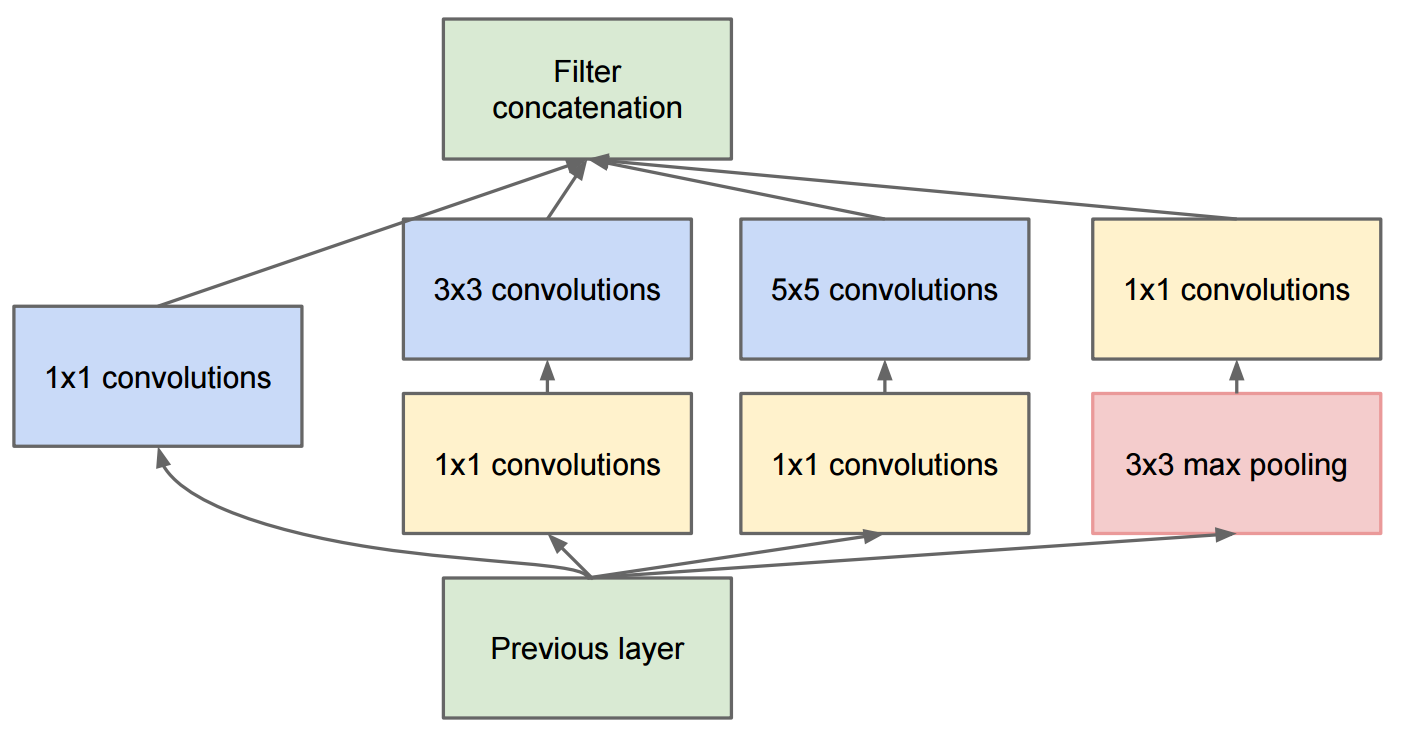
The main difference between the Inception models and regular CNNs is the inception blocks. These involve convolving the same input tensor with multiple filters and concatenating their results. In contrast, regular CNNs perform a single convolution operation on each tensor.
| MODELS | ACCURACY | ||||||||||||||||
|
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase |
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase |
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | 3-layer CNN
Inception V3 | Train: 79.25%
Test: 64.84% Train: 98.99% Test : 94.88% | ||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | ||||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | |||||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | |||||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | |||||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | |||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | |||||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | |||||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | |||||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | ||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | |||||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase | |||||||||||||||||
| ALPHABETS + 10 (0-9) digits + 15 static words ( Baby, brother, etc.) : 51 classes
(200×200 pixels Images) Datase |
Thus, we can see that Transfer Learning has increased the accuracy up to a large extent.
The codes to all above models can be found here.
Also follow- Traffic Signs Recognition using CNN and Keras in Python
Limitations of Static Datasets
- Inability (or less accuracy) to recognize moving signs, such as the letters “J” and “Z”.
- Fingerspelling for big words and sentences is not a feasible task.
- Temporal properties are not captured.
Thus, now we will be moving to dynamic (or video) Datasets.
Dynamic Gesture Detection
OBJECTIVE: Applying video classification on the video dataset of ASL signs. Take the captured videos, break them down into frames of images that can then be passed onto the system for further analysis and interpretation.
Dataset
We will use WLASL(World-Level American Sign Language ) 2000 Dataset. The Dataset has 2000 classes, 21083 videos made by around 119 signers.
Link: Click Here
Algorithm:
We will use Inception 3D (I3D) algorithm, which is a 3D video classification algorithm.
The original I3D network is trained on ImageNet and fine-tuned on Kinetics-400. We will be using transfer learning and use this on our dataset. More info about the network:
- Weights and biases were taken from Inception v3 model(pre-trained from ImageNet Dataset). When inflating the 2D model into 3D, they simply took the weights and biases of each 2D layer and “stacked them up” to form a 3rd dimension.
- The final I3D architecture was trained on the Kinetics dataset, a massive compilation of YouTube URLs for over 400 human actions and over 400 video samples per action.
Data Preprocessing
- We will convert the videos to mp4, extract Youtube frames and create video instances.
- Total number of videos for training: 18216, Total number of videos for testing: 2879
- Mode used: RGB Frames [Other option: optical flow] ( Dataset consists of RGB-only videos)
Model Set-Up
In order to better model the Spatio-temporal information of the sign language, such as focusing on the hand shapes and orientations as well as arm movements, we need to fine-tune the pre-trained I3D.
- Original model: Inception I3d (400, in_channels=3) : 400 classes and 3 input channels // In the original kinetic dataset Ref
- Tuned Model: The class number varies in our WLASL dataset, only the last classification layer is modified in accordance with the class number. So, the last layer is replaced from 400 to 2000 neurons.
- Evaluation Metrics: Mean scores of top-K classification accuracy with K = {1, 5, 10} over all the sign instances.

The verb “Wish” (top) and the adjective “hungry” (bottom) correspond to the same sign
As seen in the Figures, different meanings have very similar sign gestures, and those gestures may cause errors in the classification results. However, some of the erroneous classifications can be rectified by contextual information. Therefore, it is more reasonable to use top-K predicted labels for the word-level sign language recognition.
Top-1Top-5Top-10
I3D Algorithm 40.6%71.58%81.03%
The complete code can be found here: Click Here
Conclusion
Sign language recognition represents a pivotal advancement in technology, offering a bridge between the hearing and deaf communities. Through the lens of computer vision, this article delved into the intricacies of static hand gesture detection and dynamic gesture recognition, employing Convolutional Neural Networks (CNNs) and Transfer Learning techniques. While static datasets have their limitations, the transition to dynamic datasets opens new avenues for capturing temporal properties. By leveraging machine learning algorithms and sophisticated models like Inception I3D, sign language recognition systems can achieve impressive accuracies, paving the way for more inclusive communication and accessible technology. As the field continues to evolve, addressing challenges and refining methodologies will be key to advancing the efficacy and applicability of sign language recognition systems.
Frequently Asked Questions
Q1. What is sign language recognition system?
A. A sign language recognition system is a technology that uses machine learning and computer vision to interpret hand gestures and movements used in sign language and translate them into written or spoken language.
Q2. Which algorithm is used for sign language recognition?
A. Different algorithms can be used for sign language recognition, including Convolutional Neural Networks (CNNs), Hidden Markov Models (HMMs), and Support Vector Machines (SVMs). CNNs are currently one of the most popular approaches due to their accuracy and efficiency in image recognition tasks.
Q3. What is sign language recognition in artificial intelligence?
A. Sign language recognition in artificial intelligence is a subfield of computer vision that focuses on developing algorithms that can interpret hand gestures and movements used in sign language. It aims to create technology that can bridge the communication gap between deaf or hard-of-hearing individuals and the hearing population.
Q4. Why do we need sign language recognition?
A. Sign language recognition is needed to provide an effective means of communication for deaf or hard-of-hearing individuals who use sign language as their primary means of communication. It can also benefit hearing individuals who want to learn sign language and improve their communication with the deaf community. Additionally, it can help in the creation of more accessible technology and services for the deaf community.
The media shown in this article on Sign Language Recognition are not owned by Analytics Vidhya and are used at the Author’s discretion.

