This article was published as a part of the Data Science Blogathon
Introduction
We will learn the basics of text preprocessing in this article.
Humans communicate using words and hence generate a lot of text data for companies in the form of reviews, suggestions, feedback, social media, etc. A lot of valuable insights can be generated from this text data and hence companies try to apply various machine learning or deep learning models to this data to gain actionable insights. Text preprocessing is used to prepare raw unstructured text data for further processing.
Text preprocessing is required to transform the text into an understandable format so that ML algorithms can be applied to it.
Why text preprocessing is required
If we don’t preprocess the text data then the output of the algorithm built on top of it would be meaningless. It will not hold any business value. The output of the algorithm would be garbage(useless) like its input data(garbage).
The below image is taken from http://www.accutrend.com/it-still-comes-down-to-garbage-in-garbage-out/

Machine learning algorithms don’t understand the unstructured text and hence there is a need for treatment of the text data so that it can be consumed by various NLP algorithms. Sometimes unstructured text data contains noise that needs to be treated as well. This whole exercise of standardization of the text data so that it could be used by machine learning algorithms is known as text preprocessing.
Clients’ data are always messy and noisy. Therefore it is important for us to be equipped with knowledge of text preprocessing. There are endless ways to preprocess a text and we will learn some famous steps below.
Converting text data into lowercase
Python provides the lower() function to lowercase the text data. It is important to lowercase the text data because we don’t want machine learning algorithms to read Laptop, LAPTOP, and laptop as three separate words.
text = "LAPTOP, laptop and Laptop"
print("Output without lower function n",text)
lower = text.lower()
print("n Output of lower function n",lower)
Removal of non-alphabetical characters
There are various scenarios where numerical characters don’t add much value to the context of the text and hence we remove them
Below code 1 will replace all non-alphabetical characters like numerals and special characters with blank space and code 2 will replace only numerals with blank space.
import re
text = "I ate 4 chapati and 5 idlis. I am still hungry. I will buy 3 burgers and 2 pizzas."
##Code 1 - Removing non-alphabatical characters from text
text_char = re.sub('[^A-Za-z]', ' ', text)
print(text_char)
##Code 2 - Removing only numbers from text
text_d = re.sub('d+','',text)
print(text_d)
Companies that work in the sports domain e.g. cricbuzz, don’t want to exclude numbers from the text as players’ stats are very important for the context of the sentence. We need to handle numbers differently in that case instead of removing them.
Using inflect library we can convert numbers into words. Using the below code you can compare the output of the inflect library with the one where we have excluded all numeric characters.
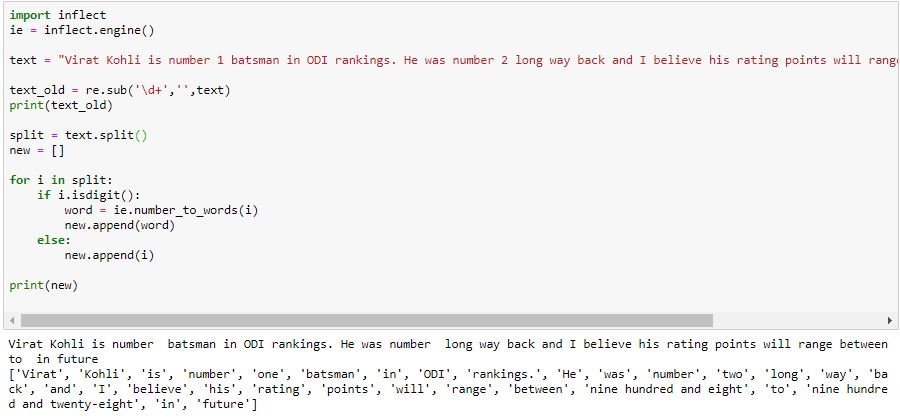
import inflect
ie = inflect.engine()
text = "Virat Kohli is number 1 batsman in ODI rankings. He was number 2 long way back and I believe his rating points will range between 908 to 928 in future"
text_old = re.sub('d+','',text)
print(text_old)
split = text.split()
new = []
for i in split:
if i.isdigit():
word = ie.number_to_words(i)
new.append(word)
else:
new.append(i)
print(new)
Removal of punctuations and stopwords
It is important to remove punctuations as they do not contribute much to the information or meaning of a text. With their removal, we can reduce the size of the data as well as increase the computation speed.
Stopwords are the most common words in a language. For example in English language “is”, “am”, “the”, “how”, “to” etc. are stopwords. These words convey less meaning than other words and hence their removal can help to focus more on important keywords in the text. We have used the NLTK library here to remove the stopwords. We can also create a list of custom stopwords based on our requirements.
Before removing stopwords we will tokenize the text i.e. we will split the entire text into separate meaningful pieces called tokens. Again we have used the NLTK library for tokenization. There are other popular libraries like SpaCy and TextBlob also serve the same purpose.
Below is the python implementation of the same.
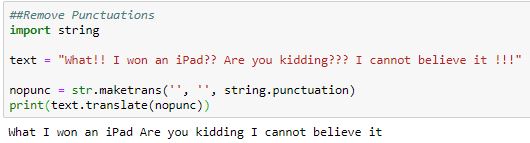
##Remove Punctuations
import string
text = "What!! I won an iPad?? Are you kidding??? I cannot believe it !!!"
nopunc = str.maketrans('', '', string.punctuation)
print(text.translate(nopunc))
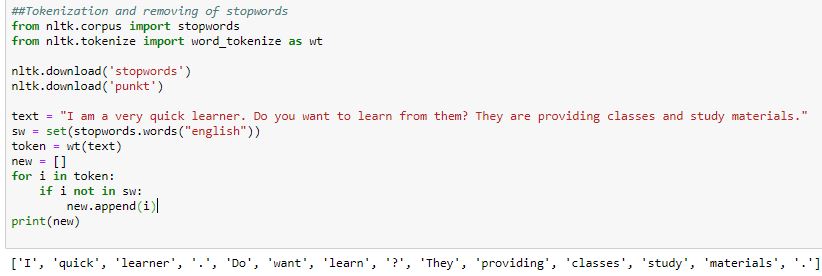
##Tokenization and removing of stopwords
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize as wt
nltk.download('stopwords')
nltk.download('punkt')
text = "I am a very quick learner. Do you want to learn from them? They are providing classes and study materials."
sw = set(stopwords.words("english"))
token = wt(text)
new = []
for i in token:
if i not in sw:
new.append(i)
print(new)
Stemming and Lemmatization
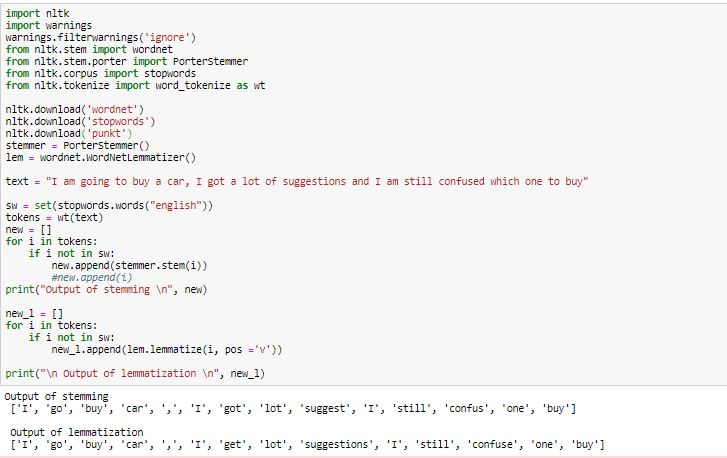
Stemming helps to find the root of words. By removing prefix or suffix we will create the stem word. The output of stemming may or may not result in an actual word. For example, “run“, “running“, “runs” is stemmed into “run“.
Porter Stemmer is the most used stemmer. Other stemmers are snowball and Lancaster.
In the case of Lemmatization, we will always get a valid word. The process is similar to stemming where we try to find the root word but we also pass the ‘part of speech‘ parameter that brings the context to the words unlike stemming. For example, “bad“,”worse” and “worst” is lemmatized into “bad“
You can compare the output of stemming and lemmatization from the below snippet.
import nltk
import warnings
warnings.filterwarnings('ignore')
from nltk.stem import wordnet
from nltk.stem.porter import PorterStemmer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize as wt
nltk.download('wordnet')
nltk.download('stopwords')
nltk.download('punkt')
stemmer = PorterStemmer()
lem = wordnet.WordNetLemmatizer()
text = "I am going to buy a car, I got a lot of suggestions and I am still confused which one to buy"
sw = set(stopwords.words("english"))
tokens = wt(text)
new = []
for i in tokens:
if i not in sw:
new.append(stemmer.stem(i))
#new.append(i)
print("Output of stemming n", new)
new_l = []
for i in tokens:
if i not in sw:
new_l.append(lem.lemmatize(i, pos ='v'))
print("n Output of lemmatization n", new_l)
Chunking
Chunking is the process of extracting phrases from an unstructured text.
For example, tokens ‘Sri‘ and ‘Lanka‘ will not be able to convey the meaning of the sentence. In this case phrase, ‘Sri Lanka‘ is useful as a single word.
In the above scenarios, chunking is used to extract phrases out of the unstructured text. We need to do POS (Part of Speech) tagging before performing chunking on a text.
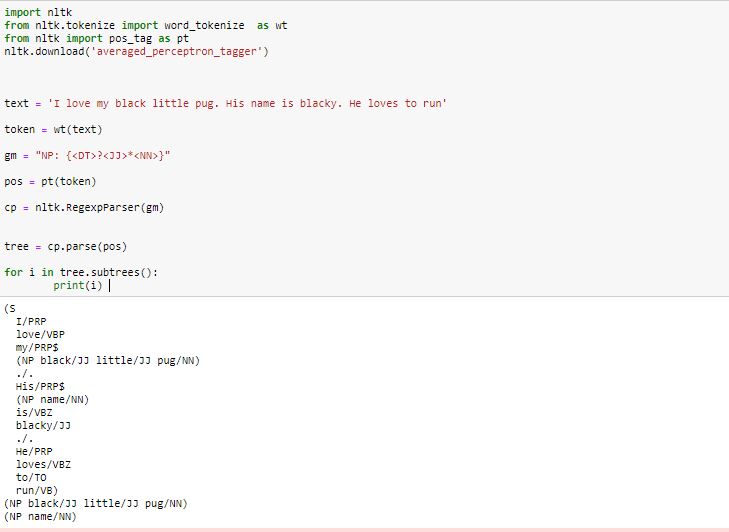
In the code below we have defined the grammar using a regular expression to form the noun phrases.
import nltk
from nltk.tokenize import word_tokenize as wt
from nltk import pos_tag as pt
nltk.download('averaged_perceptron_tagger')
text = 'I love my black little pug. His name is blacky. He loves to run'
token = wt(text)
gm = "NP: {<DT>?<JJ>*<NN>}"
pos = pt(token)
cp = nltk.RegexpParser(gm)
tree = cp.parse(pos)
for i in tree.subtrees():
print(i)
Named Entity Recognition
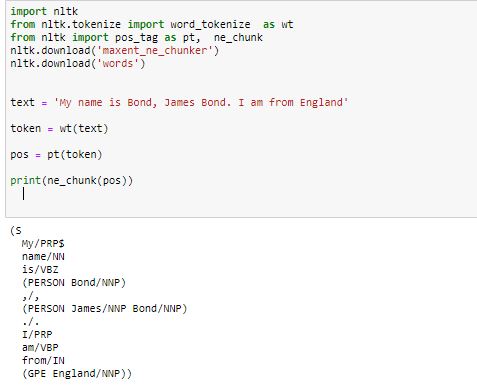
Named Entity Recognition is used when we need to segregate entities into the name, location, etc from an unstructured text. NLTK built-in method nltk.ne_chunk() can recognise various entities. We have implemented the same using python.
import nltk
from nltk.tokenize import word_tokenize as wt
from nltk import pos_tag as pt, ne_chunk
nltk.download('maxent_ne_chunker')
nltk.download('words')
text = 'My name is Bond, James Bond. I am from England'
token = wt(text)
pos = pt(token)
print(ne_chunk(pos))
Closing Notes
In this article, we learned the basic text preprocessing steps required before applying any machine learning model to the text data. In the next article, we will learn a complete end-to-end implementation of the text analytics model.
Hope you found this article insightful!
Author
Himanshu Kunwar is a data science consultant helping business stakeholders across multiple domains with actionable data insights. You can connect with him on LinkedIn.
His other blogs on analytics Vidhya can be found here.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.



