This article was published as a part of the Data Science Blogathon
Introduction
Let’s say you have a client who has a publishing house. Your client comes to you with two tasks: one he wants to categorize all the books or the research papers he receives weekly on a common theme or a topic and the other task is to encapsulate large documents into smaller bite-sized texts. Is there any technique and tool available that can do both of these two tasks?
Lo and behold! We enter the world of Topic Modeling. I’ll break this article into three parts. In the current one, we’ll explore the basics of how text data is seen in Natural Language Processing, what are topics, what is topic modeling.
We shall see what are the applications of topic modeling, where all it is used, what are the methodologies to perform topic modeling, and what are the types of models available.
In the second article, we will dive in-depth into the most popular topic modeling technique called LDA, how it works, and in the third article how we apply it in Python.

Table of Contents
- What are Topics?
- What is Topic Modeling?
- What are the Uses of Topic Modeling?
- Topic Modeling Tools and Types of Models
- Discriminative Models
- Generative Models
But first, let us get clear on what the topic means?
What are Topics?
Topics or themes are a group of statistically significant “tokens” or words in a “corpus”.
In case, the terminologies corpus and token are new to you, so here’s a quick refresher:
- A corpus is the group of all the text documents whereas a document is a collection of paragraphs.
- A paragraph is a collection of sentences and a sentence is a sequence of words (or tokens) in a grammatical construct.
So basically, a book or research paper, which collectively has pages full of sentences, can be broken down into words. In the world of Natural Language Processing (NLP), these words are known as tokens that are a single and the smallest unit of text. The vocabulary is the set of unique tokenized words.
And, the first step to work through any text data is to split the text into tokens. The process of splitting a text into smaller units or words is known as tokenization.
For instance, the sentence “The stock price of Google is USD2,450.” Tokenizing over each word, punctuation marks, and symbols on this sentence, we have the tokens as:

Following is an illustration of a text data structure:
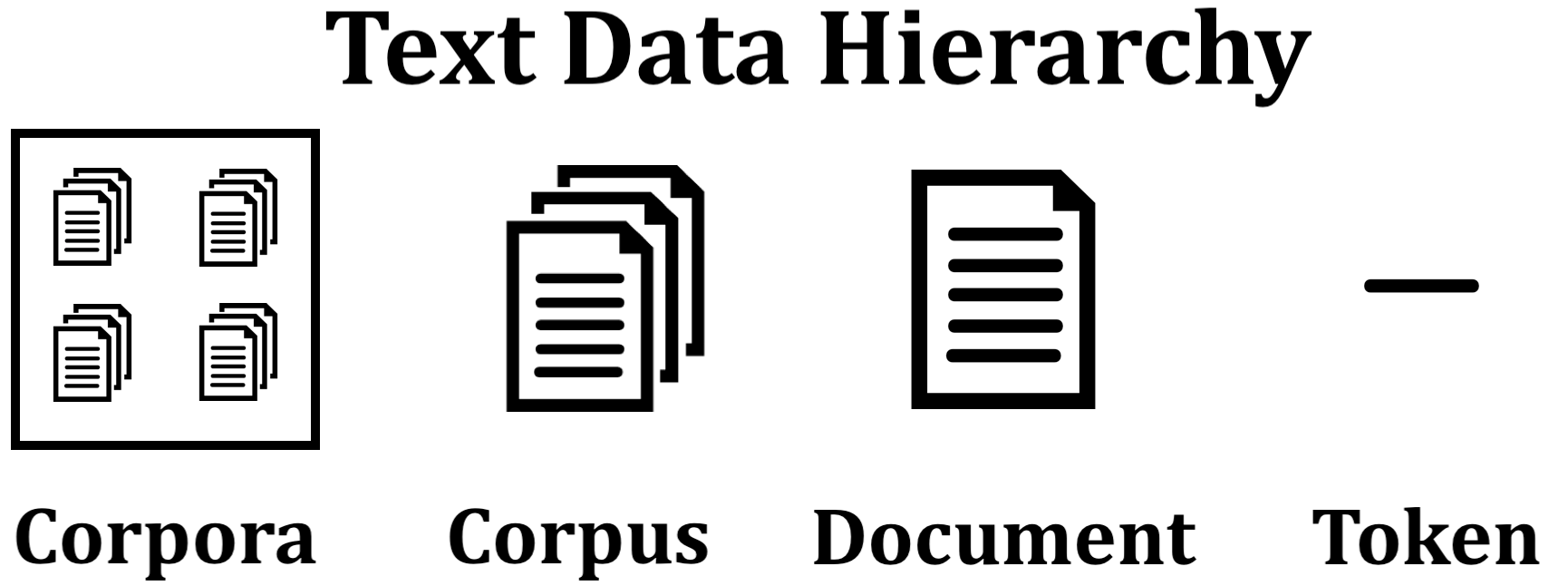
Source: miro.medium.com
Now, turning towards what are topics?
As a human, we can easily read through a text or review or book and based on this context tell what a topic the book or text is referring to, right? Yes! However, how would a machine tell us what is the topic of the book? How can you tell if a machine can rightly classify a book or text into the correct category? The only way to interpret what a machine builds for us in the language of Statistics.
Therefore, had said above that a topic or a theme is a group of statically significant words or tokens.
So, the next question that arises for us is to unravel what do we mean by statistical significance in the context of the text data? The statistically significant words imply that this collection of words are similar to each other and we see that in the following way within a text data:
- The group of words occurs together in the documents
- These words have similar TF-IDF term and inverse document frequencies
- This group of words occurs regularly at frequent intervals
Some of the examples of words having common topics are:
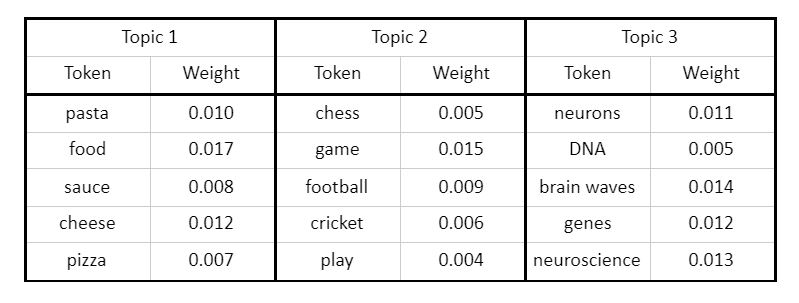
In the above table, we have three different topics. Topic 1 on food, Topic 2 talks about games, and Topic 3 have words related to neuroscience. In each case, the words that are similar to each other come together as a topic.
We will see in the later sections how we get these weights, how are the words grouped.
What is Topic Modeling?
Now that we have understood what topics are, it would be easier to grasp what topic modeling is.
Topic modeling is the process of automatically finding the hidden topics in textual data. It is also referred to as the text or information mining technique that has the aim to find the recurring patterns in the words present in the corpus.
It is an unsupervised learning method as we do not need to supply the labels to the topic modeling algorithm for the identification of the themes or the topics. Topics are automatically identified and classified by the model.
Essentially, topic modeling can be seen as a clustering methodology, wherein the small groups (or clusters) that are formed based on the similarity of words are known as topics. Additionally, topic modeling returns another set of clusters which are the group of documents collated together on the similarity of the topics. It is visually depicted below:

Source: https://v1.nitrocdn.com/
For understanding and illustrative purposes, we have a corpus with the following five documents:
- Document 1: I want to watch a movie this weekend.
- Document 2: I went shopping yesterday. New Zealand won the World Test Championship by beating India by eight wickets at Southampton.
- Document 3: I don’t watch cricket. Netflix and Amazon Prime have very good movies to watch.
- Document 4: Movies are a nice way to chill however, this time I would like to paint and read some good books. It’s been so long!
- Document 5: This blueberry milkshake is so good! Try reading Dr. Joe Dispenza’s books. His work is such a game-changer! His books helped to learn so much about how our thoughts impact our biology and how we can all rewire our brains.
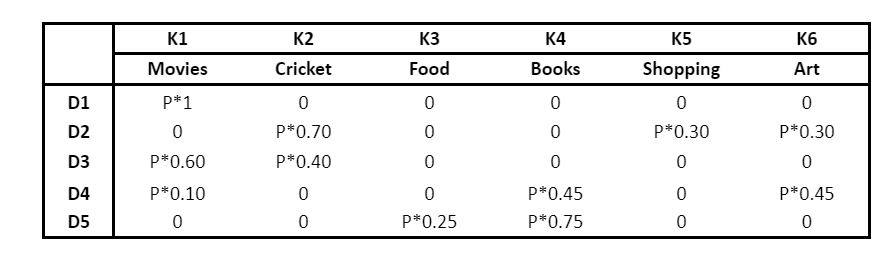
Here, P implies that the respective topic is present in the current document and 0 indicates the absence of the topic in the document.
And, if the topic is present in the document then the values (which are random as of now) assigned to it convey how much weightage does that topic has in the particular document.
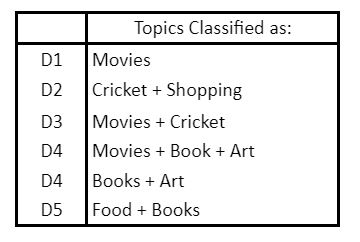
As seen above, a document may be a combination of many topics. Our intention here with topic modeling is to find the main dominant topic or the theme.
We will be working with the same set of documents in the following parts of the article as well.
What are the Uses of Topic Modeling?
Topic Modeling is a very important Natural Language Processing tool that is extensively used for the following objectives:
-
Document Categorization: The goal is to categorize or classify a large set of documents into different categories based on the common underlying theme. We saw above to classify the books or the research papers into different categories.
-
Document Summarization: It is a very handy tool for generating summaries of large documents; say in our case we want to summarize the large stack of research papers.
-
Intent Analysis: Intent analysis means what each sentence (or tweet or post or complaint) refers to. It tells what is the text trying to explain in a particular document.
-
Information Retrieval: Information retrieval, concerned with storing, searching, and retrieving information also leverages the utility of topic modeling by deciphering the themes and content of the larger data.
-
Dimensionality Reduction: In any model, reducing dimensions is a key aspect. It’s a hassle to make a model with a large number of dimensions. Topic modeling helps to decrease the dimensions or features of the text data as the documents which at the start contain words are further converted into documents consisting of the topics. Hence, similar words are clubbed together to form the topics, which reduces the dimensions of the corpus.
-
Recommendation Engines: Recommendation engines are also built and the engines are used to share the preferred content with the users based on the themes filtered after applying topic modeling.
Topic Modeling Tools and Types of Models
Now, moving on to the techniques for executing topic modeling on a corpus. There are many methods for topic modeling such as:
- Latent Dirichlet Allocation (LDA)
- Latent Semantic Allocation (LSA)
- Non-negative Matrix-Factorization (NNMF)
Of the above techniques, we will dive into LDA as it is a very popular method for extracting topics from textual data.
Now, we’ll take a small detour from topic modeling to the types of models. We will soon see the need for that. There are two types of model available:
- Discriminative models, and
- Generative models
Discriminative models
The discriminative models are a type of logistical model and are mostly used for supervised learning problems. This type of model uses conditional probabilities to predict. The model learns to predict by calculating the conditional probability distribution P(Y|X), which is the probability of Y given X. It implies what are the chances of occurrence of event Y given event X. It is applied for business cases related to regression and classification.
Discriminative models are more analogous and differentiate the classes with the observed data as defect or no-defect, having the disease or no disease. These models are applied in all spheres of artificial intelligence:
- Logistic Regression
- Decision Tree
- Random Forest
- Support Vector Machine (SVM)
- Traditional Neural Network
Generative Models
On the other hand, generative models use statistics to generate or create new data. These models estimate the probabilities using the joint probability distribution P(X, Y). These not only estimate the probabilities but also models the data points and differentiates the classes based on these computed probabilities of the class labels. These types of models are known as statistical or conditional models.
As compared to the discriminative models, the generative models have the capacity of handling more complicated tasks and are empowered with the ability to create more data to build the model on. These are unsupervised learning techniques that are used to discover the hidden patterns within the data.
In NLP, the generative models are the Naive Bayes, N-gram Language Model. The Naive Bayes classifiers and Bayesian networks are constructed on the underlying Bayes theorem which uses the joint probability.
Examples of other generative models are:
- Gaussian Mixture Model (GMM)
- Hidden Markov Model (HMM)
- Linear Discriminant Analysis (LDA)
- Generative Adversarial Networks (GANs)
- Autoencoders
- Boltzmann Machines
Moving back to our discussion on topic modeling, the reason for the diversion was to understand what are generative models.
The topic modeling technique, Latent Dirichlet Allocation (LDA) is also a breed of generative probabilistic model. It generates probabilities to help extract topics from the words and collate documents using similar topics. We will see in part 2 of this blog what LDA is, how does LDA work? How is LDA similar to PCA and in the last part we will implement LDA in Python. Stay tuned for more!
About me
Hi there! I am Neha Seth, a technical writer for AnalytixLabs. I hold a Postgraduate Program in Data Science & Engineering from the Great Lakes Institute of Management and a Bachelors in Statistics. I have been featured as Top 10 Most Popular Guest Authors in 2020 on Analytics Vidhya (AV).
My area of interest lies in NLP and Deep Learning. I have also passed the CFA Program. You can reach out to me on LinkedIn and can read my other blogs for ALabs and AV.
Hi there! I am Neha Seth. I work as a Data Scientist in Larsen & Toubro Infotech (LTI). I hold a Postgraduate Program in Data Science & Engineering from the Great Lakes Institute of Management and a Bachelors in Statistics. I have been featured as Top 10 Most Popular Guest Authors in 2020 on Analytics Vidhya (AV).
My area of interest lies in NLP and Deep Learning. I have also passed the CFA Program. You can reach out to me on LinkedIn and can read my other blogs for AV.







Dear Neha, Your article is very helpful and easy to understand. I help me a lot in understanding the concept of LDA. I am new to machine learning, could you please help me to understand section What is topic modeling? In table Topic Classified as , why D2 does not contain Art (K6) I really need your explanation Thank you and have a great day -norhasliza-