Introduction
Data Engineers and data scientists often have to deal with an enormous amount of data Indexing in database. Dealing with such data is not a straightforward task. To process this data as efficiently as possible, we need to have a clear understanding of how the data is organized. So before moving on to the main topic, let us build a basic ground first.
This article was published as a part of the Data Science Blogathon
Table of contents
Memory in a computer system
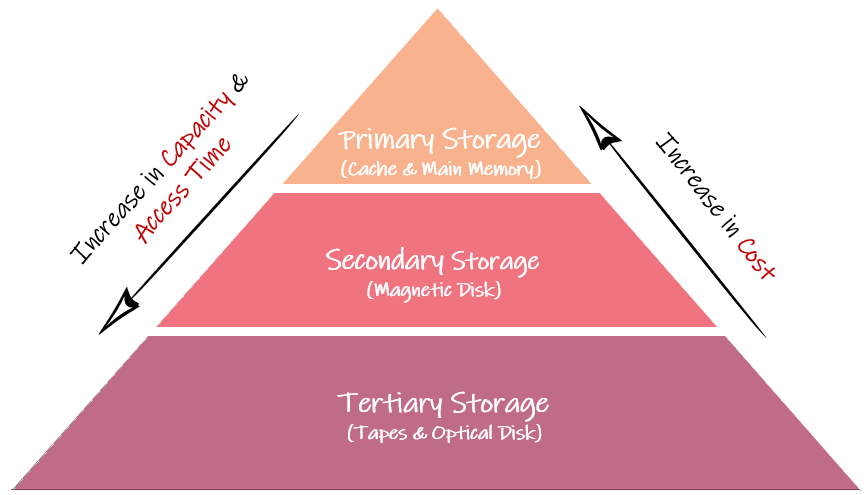
Image by author
Capacity and access time increase and cost decrease as we move from top to bottom of the hierarchy. Tapes and disks play important role in a database system. Since the amount of data is immense, storing all the data in the main memory would be very expensive.
Therefore, we store the data on tapes/disks and build a database system that brings data from the lower level of memory into the main memory for processing as and when needed.
The database is stored as a collection of files (tables). Each file is a collection of pages (blocks). Each block is a collection of records. A record is a sequence of fields.
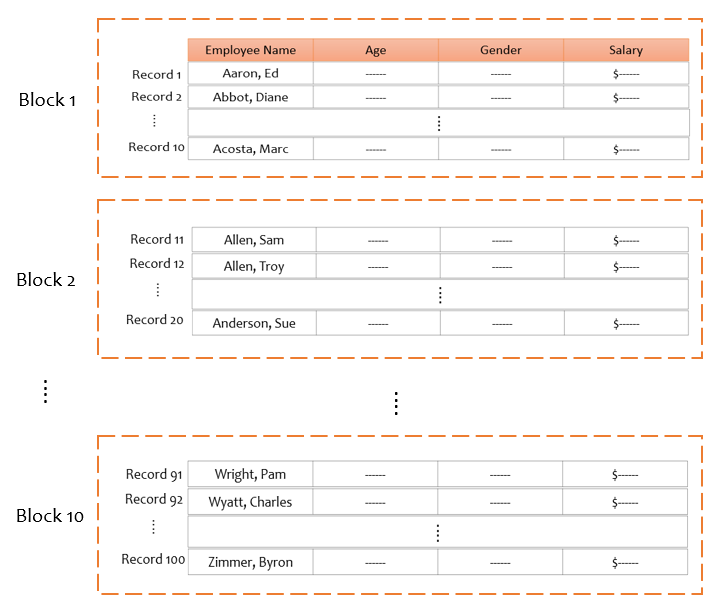
Image by author
The block is nothing but a disk block. Data is accessed from disk to main memory
block by block.
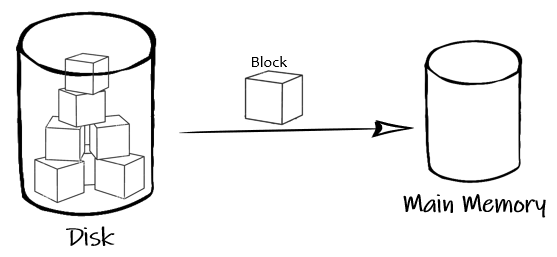
Image by author
I/O Cost: while accessing a particular record, the number of memory blocks required to access that record is called I/O Cost.
Database systems are carefully optimized to minimize this cost.
Organization of records in a file
In a file, records can be stored in two ways:
Ordered organization: When the records across the pages/blocks of a file are physically ordered based on the values of one of its fields. For example, consider an employee table that is sorted based on the employee ID field.
Unordered Organization: When the records are stored in a file in random order across the pages/blocks of a file.
Access cost from database file without indexing
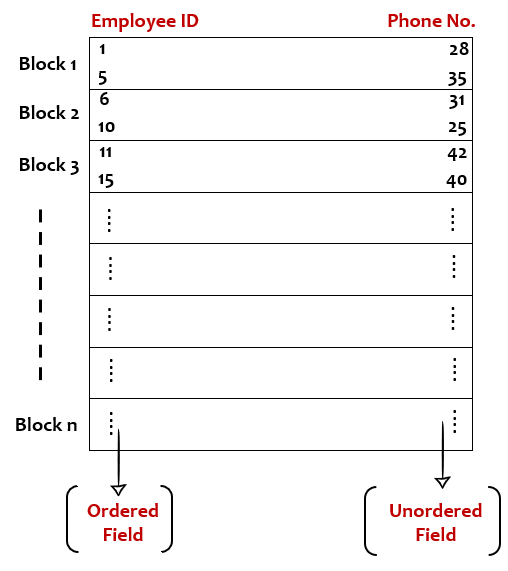
Image by author
Access cost based on unordered field:
Suppose a database Employees file/table has 1000 blocks and we want to search record whose phone no. is X.
Select *
From employees
Where phone no = x;The number of bock access will be 1000 (linear search) therefore I/O cost will be 1000.
Access cost based on ordered field:
Similarly, we want to search records from employee’s table/file whose employee ID is Y.
Select *
From employees
Where employeeID = Y;The number of bock access will be log21000 almost equal to 10 (Binary search) therefore I/O cost will be 10.
Can this I/O cost be improved any further? The answer is yes. This is where the concept of indexing comes into the picture.
Consider this to reading a book (sorted based on chapters) and not having the index page. You want to access a chapter: Photosynthesis, so you open a random page (middle page in case of binary search) and turn the pages either left or right based on the chapter number you are looking for. This will certainly take some time. What if the book contained an index page? You could have navigated to that chapter just by looking at the index page.
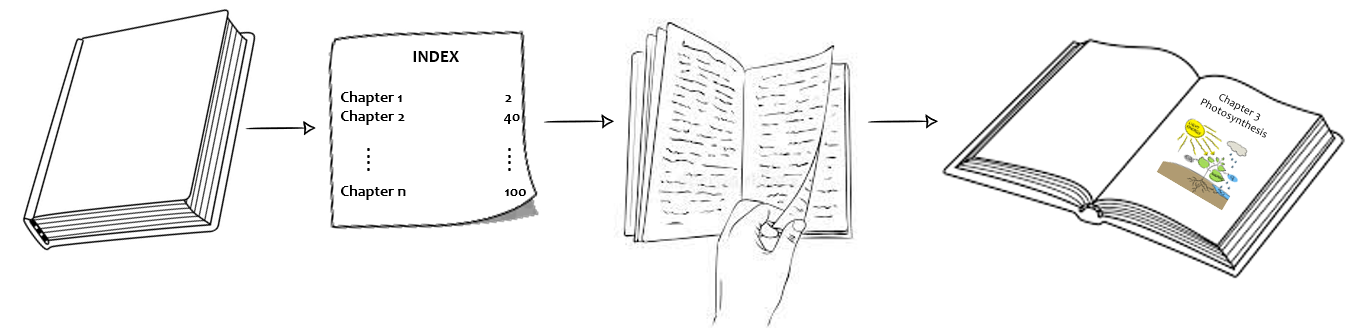
Image by author
Similarly, we can apply indexing to database files.
Indexing in Database
It is nothing but a way to optimize the performance of a database by simply minimizing the number of disk block access while processing a query. As you saw in the book analogy, the book had an additional page containing indexes similarly a database file consists of an index file that is stored in a separate disk block/page.
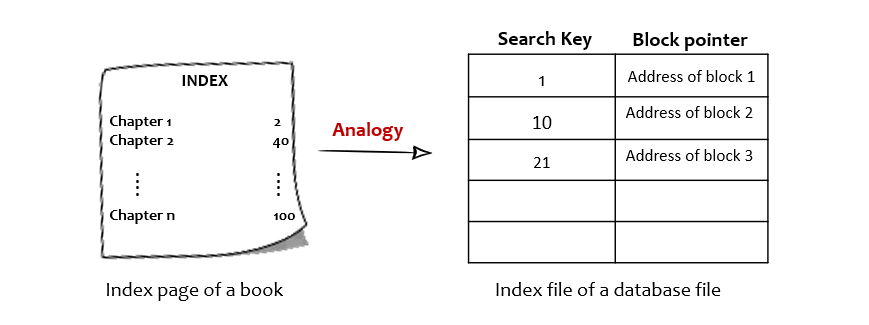
Image by author
Each entry of the index file consists of two fields <search key, pointer>.

- The first column i.e., the Search key contains a copy of the primary key or candidate keys or non-keys of the table.
- The second column i.e., the pointer contains a pointer or the address of the dick block where that particular Search key value can be found.
The index file is also divided into blocks.
Suppose a database file has N blocks. We create an Index file for the database file. The index file is further divided into M blocks (as you can see in the diagram below).
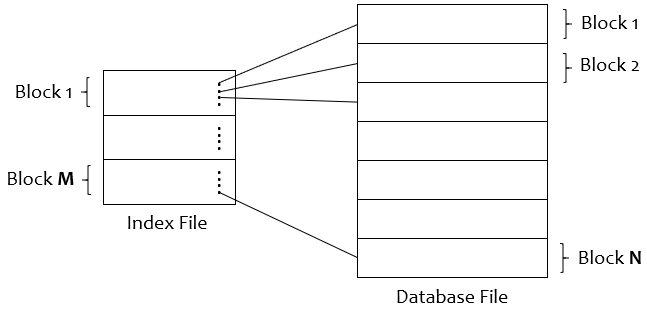
Image by author
Number of Index Blocks (M) << Number of database file blocks (N)
The number of block access or the I/O cost with indexing = log2M +1, which is very less than the previous case.
Points to remember:
- In the original database file, records can be sorted based on one field only.
- The index file is present in the disk block in sorter order.
- Binary search is used to search through the indices of the index file.
- To access a record using the indexed entries, the average number of block accesses required = log2M + 1, where M is the number of blocks in the Index file.
Categories of Index:
Now, based on the order of your database file and the number of entries/records you are going to maintain in the index file, indices can be broadly classified as:
Dense Index: It has index entries for every search key value (and hence every record) in the database file. The dense index can be built on order as well as unordered fields of the database files.
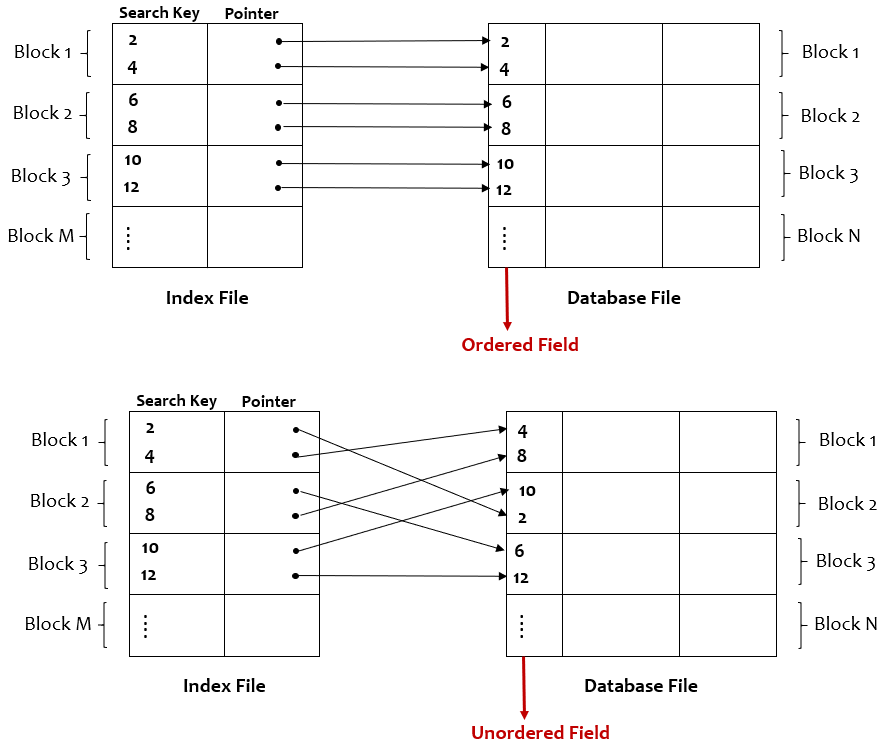
Image by author
Sparse Index: It has index entries for only some of the search key values/records in the database file. The sparse index can be built only on the ordered field of the database file. The first record of the block is called the anchor record.
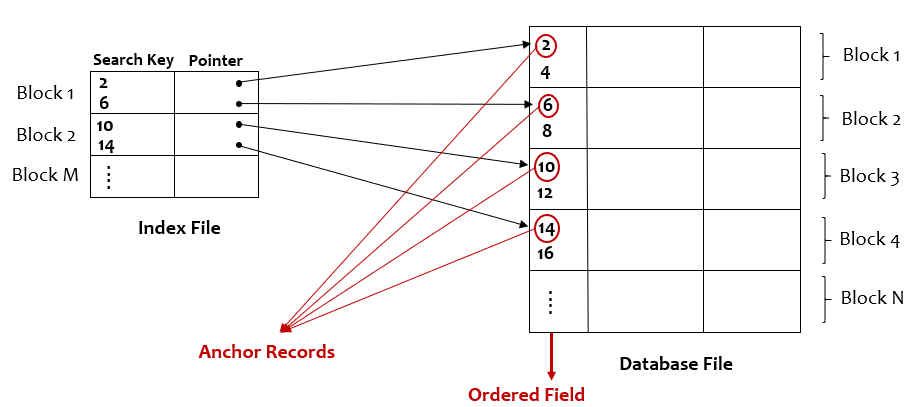
Image by author
Type of Indexing in database
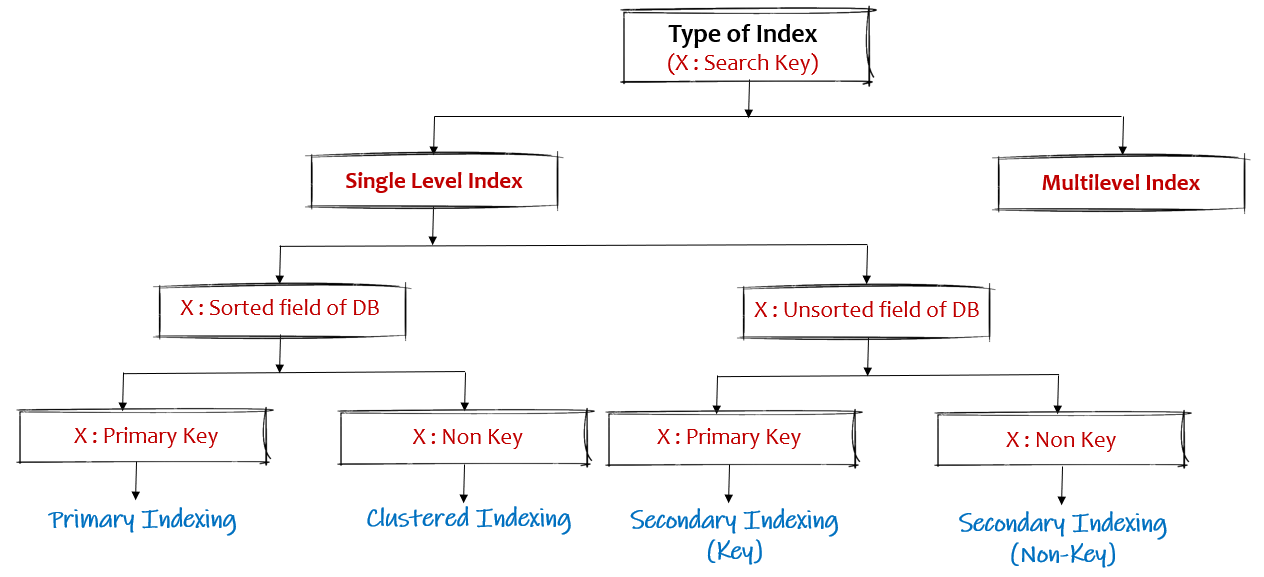
In this blog, we will cover single-level indexing.
Primary Indexing
In primary Indexing, the index is created on the ordered primary key field of the database file.
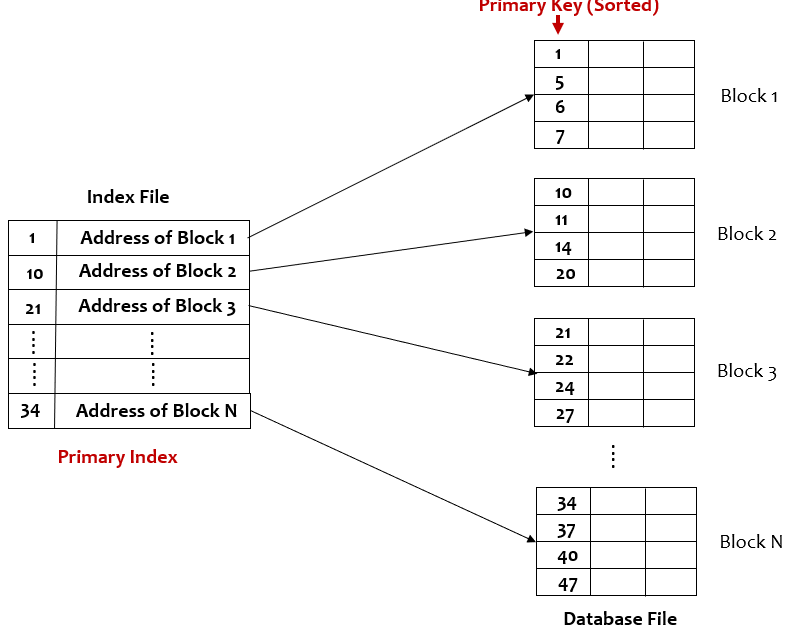
Image by author
1. It can be dense or sparse but sparse indexing is preferred.
2. The first record of each block is called block anchors.
3. The number of index entries = The number of blocks in the original database file.
4. For any database file, at most one primary index is possible because of indexing over the ordered field.
5. Binary search is used to search through the indices of the index file.
6. I/O Cost to access record using primary index = log2M + 1, where M is the number of blocks in the Index file.
Clustered Indexing
In clustered Indexing, the index is created on the ordered nonkey field of the database file.
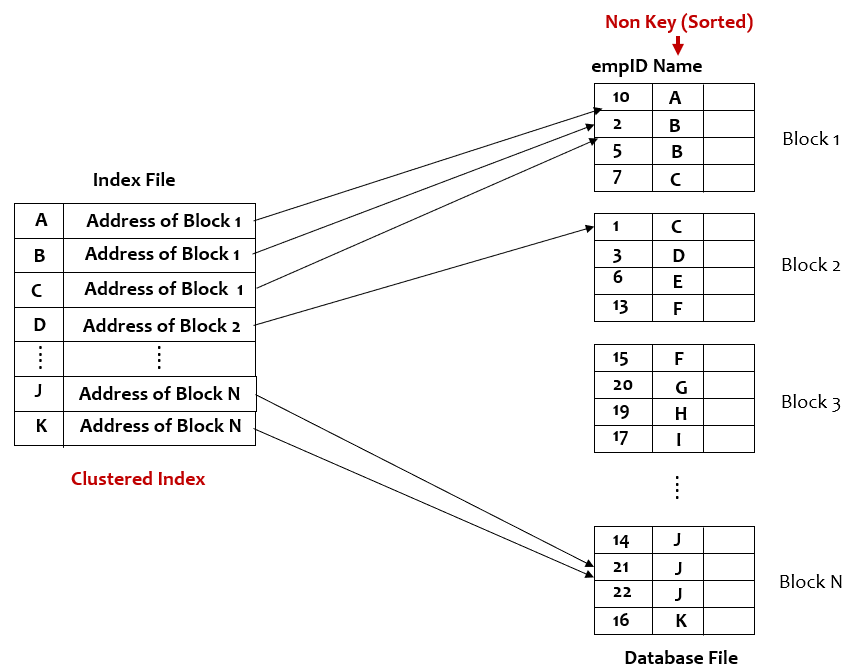
Image by author
- Clustered indexing is a mostly sparse index (dense index is also possible)
- I/O Cost to access record using primary index >= log2M + 1, where M is the number of blocks in the Index file.
- For any database file, at most one clustered index is possible because of indexing over the ordered field.
NOTE: A file has at most one physical ordering field, so it can have at most one primary index or one secondary index but not both.
Secondary Indexing Over Primary Key Field
In secondary Indexing over the key field, the index is created on the unordered key field of the database file. It is always a dense index.
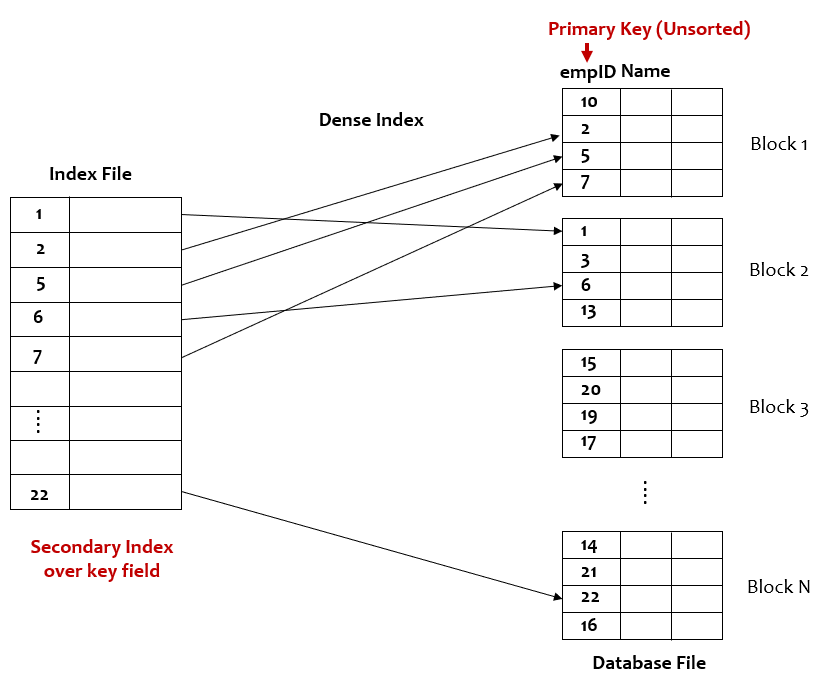
Image by author
Indexing in database
Let’s create a table named Employees consisting of the following records:
- Employee_ID
- Name
- Age
- Gender
Create table employees with Employee_ID as the primary key.
CREATE TABLE Employee (
Employee_ID int PRIMARY KEY,
Name varchar(25) NOT NULL,
Age int NOT NULL,
Gender varchar(6) NOT NULL
);The command for creating an index is as follows:
CREATE INDEX index_name
ON table_name (column_1, column_2, ...);Let’s create an index on the Employee_ID field (primary indexing).
CREATE INDEX index_id
On Employee (Employee_ID);The command for dropping an index is as follows:
ALTER TABLE table_name
DROP INDEX index_name;Conclusion
The document provides a comprehensive understanding of computer memory systems, record organization in files, and the cost implications of accessing a database file without indexing. It further delves into the concept of indexing in databases, categorizing them and explaining types such as primary, clustered, and secondary indexing over the primary key field. The knowledge gained from this content is crucial for efficient database management, as it highlights the importance of indexing in reducing access costs and improving system performance. The content is presented in an easy-to-understand manner, making it accessible for both beginners and experts in the field. It emphasizes the need for strategic data organization and management in today’s digital age.
Points To remember
- Create indices based on the attributes that are used in your ‘WHERE’ clause.
- If there is a field that appears in the ‘where’ clause in multiple queries so we may consider creating an index on
that attribute. - The list of attributes that are used in the select clause does not influence what attributes you should create indices on. (We have to look at the ‘WHERE’ clause).
The media shown in this article on Sign Language Recognition are not owned by Analytics Vidhya and are used at the Author’s discretion.






this was best article for indexing on the internet so well explained with easy language publish more articles like this