This article was published as a part of the Data Science Blogathon
Introduction:
There is a vast amount of data available on the internet, most of it is in the unstructured format in the form of image data, audio files, text data, etc. Such data cannot be used directly to build a Machine Learning model. Industries tend to be benefitted greatly if they can find a way to extract meaningful information from unstructured data. This is where web scraping comes into the picture.
According to Wikipedia, “Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. It is a form of copying in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis.” So, web scraping basically crawls through a bunch of websites and pulls out the information required. Selenium and BeautifulSoup are the commonly used libraries for web scraping using python. However, we will be using Selenium in this project.
One should also be careful because not all websites allow scraping and one should not violate their terms and conditions. For the same reason, some of the sites like Twitter provide their own APIs using which one can download whatever data needed.
Selenium Overview:
Selenium is a powerful automation tool that is basically used to test web applications. It is compatible with different programming languages such as C#, Java, Perl, Python, etc. and supports a wide variety of browsers such as Chrome, Firefox, Safari, etc. WebDriver is the main component of Selenium which is used to interact with the web browser. It can perform operations on web elements such as clicking a button, filling a form, resizing the browser windows, handling browser popups, adding or deleting the browser cookies, etc. Further information on selenium can be accessed from here.
Installing Selenium:
Selenium can be installed in Python using pip or conda. We will also need Chrome Driver or Gecko driver depending on the browser, it can be downloaded from here.
Pip install selenium
conda install selenium
Objective:
Our main objective is to scrape through the job portal and fetch Machine Learning related jobs or any other jobs for that matter. We will also be fetching information such as Job Title, Location, Company Name, Experience needed, Salary offered, Company ratings and number of reviews of the company, etc. We will do the following,
- Open a new browser using selenium.
- Open the job portal and search for the relevant job in the search field and parse through the required number of jobs and get the relevant details.
- All this is done automatically and all you need to pass is the search term, the number of jobs to be fetched and the path to your drivers.
Note: It is assumed that you have some basic knowledge about selenium. However, all the code used in this project will be thoroughly explained.
Implementation:
1. Importing Libraries.
We will be using selenium, pandas libraries and they can be imported using the code below,
from selenium.common.exceptions import NoSuchElementException from selenium import webdriver import time import pandas as pd
2. Initializing the WebDriver and Getting the URL.
The first step before opening any URL using selenium is to initialize the WebDriver, the WebDriver basically acts as a mediator between the browser and your selenium code. The code below is used to initialize the driver and open the URL.
# initializing the chromedriver options = webdriver.ChromeOptions() driver = webdriver.Chrome(executable_path=path+"/chromedriver.exe", options=options)
# opening the URL
driver.get("https://www.naukri.com/")
3. Closing the Unwanted Popups.
For some reason, when you open the Naukri.com website using selenium, some unwanted ads in the form of popups open up as you can see below and they need to be closed. For this, we will initially note down the window handle of the main page, then loop through all the open window handles and close the ones that are not necessary. Follow the code below to do just that,
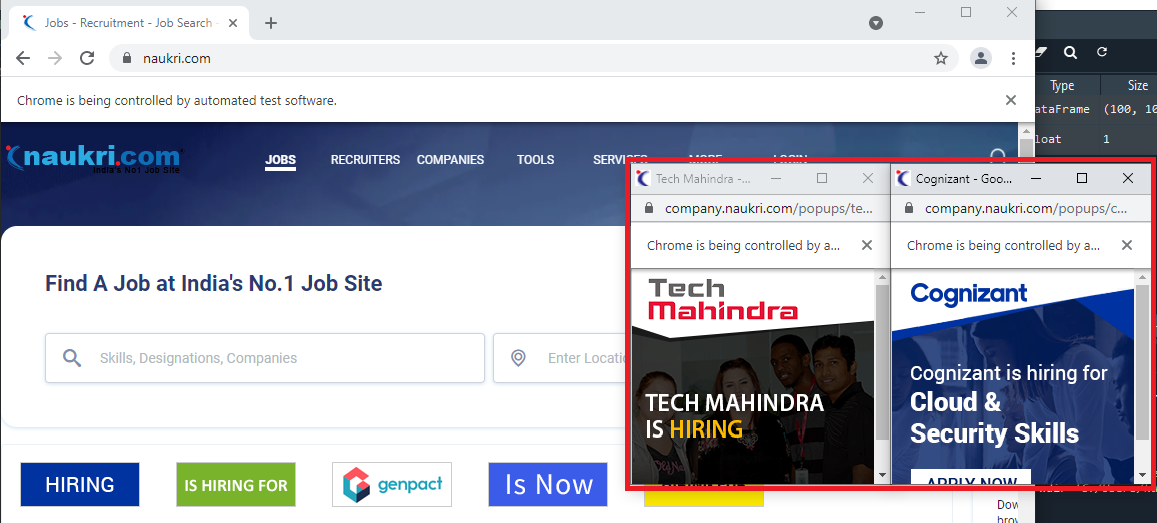
#looping through all the open windows and closing ones that are not needed
for winId in popup_windows:
if winId != Main_Window:
driver.switch_to.window(winId)
driver.close()
# switching to the main window driver.switch_to.window(Main_Window)
1. Entering the required Keyword to search.
We can find the search field using the class_name and send in the keys to search. We will also get the URL once the search results are obtained (this URL will be modified later as we will see below). Now the URL obtained is in a specific format and we need to split it based on “?” and get the two parts of the URL.
# Searching using the keyword
driver.find_element_by_class_name("sugInp").send_keys(search_keyword)
driver.find_element_by_class_name("search-btn").click()
# getting the current url which has a specific format which will be used later get_url = driver.current_url
# getting the two parts of the url by splitting with "?"
first_part = get_url.split("?")[0]
second_part = get_url.split("?")[-1]
1. Initializing Empty Lists.
We will initialize some empty lists to store the information necessary. We will use these lists at the end to build our final data frame.
# defining empty lists to store the parsed values Title = [] Company = [] Experience = [] Salary = [] Location = [] Tags = [] Reviews = [] Ratings = [] Job_Type = [] Posted = []
2. Parsing.
The search results that are obtained are divided into pages with 20 results displayed in each page. To find the number of pages to scrape through we will use the number of jobs required to be fetched and loop through all the pages. And the number of pages to be scraped through are found by using the Range function in python as below,
range(1,int(num_of_jobs/20)+1)
To loop through all the search result pages, we will use two parts of the URL that we obtained earlier and form a new URL as below,
# forming the new url with the help of two parts we defined earlier url = first_part+"-"+str(i)+"?"+second_part
# opening the URL
driver.get(url)
The way it works is, once the first page of the search result is displayed, all the data needed is gathered and is appended to the respective empty lists, then, a new URL that we formed above is opened and the information from the second page is appended and this cycle repeats. So instead of clicking on the Page Numbers at the end of each page, a new URL is formed and opened.
3. Finding Individual Elements.
There are plenty of ways to find the elements in selenium, some of them are using CSS Selectors, Class Names, ID value, XPATH, Tag Name, Partial Link Text, etc. To find the individual elements such as Experience, Salary, etc. we first obtain the list of all jobs on the page, and then from that list we will fetch individual elements. It can sometimes be difficult to find the elements if they do not have a unique selector or id value.
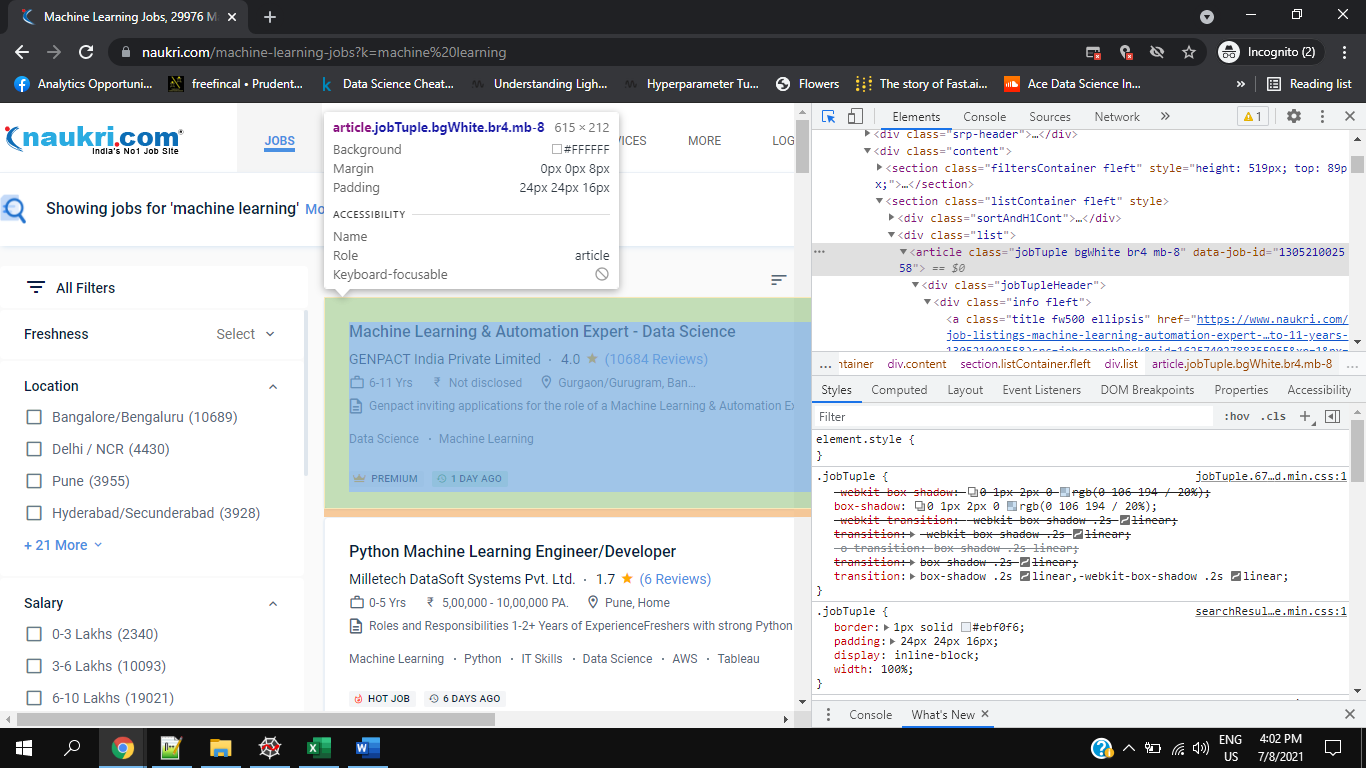
# getting job listing details
job_list = driver.find_elements_by_class_name("jobTuple.bgWhite.br4.mb-8")
We will also be using try and expect statements to find if the element is missing and if so, we will be appending an appropriate value to the list. You can see a sample code to find the elements below,
# getting the number of days before which the job was posted
try:
days = element.find_element_by_css_selector('div.type.br2.fleft.grey').text
Posted.append(days)
except NoSuchElementException:
try:
days = element.find_element_by_css_selector('div.type.br2.fleft.green').text
Posted.append(days)
except NoSuchElementException:
Posted.append(None)
4. Final Data Frame.
Once the parsing of all results is completed, and all the values are appended to the respective empty lists, we initialize an empty data frame and then create the columns of the data frame using the lists, data frame can then be exported to any format needed.
# initializing empty dataframe df = pd.DataFrame()
# assigning values to dataframe columns df['Title'] = Title df['Company'] = Company df['Experience'] = Experience df['Location'] = Location df['Tags'] = Tags df['Ratings'] = Ratings df['Reviews'] = Reviews df['Salary'] = Salary df['Job_Type'] = Job_Type df['Posted'] = Posted
df.to_csv("Raw_Data.csv",index=None)
Conclusion:
Although it is easy to parse a few hundred job listings it can be time-consuming if you need to scrape through tens of thousands of jobs. This was also challenging because it was difficult to find some elements because of differences in class names (Eg: Posted element had two different CSS Selectors as you can see in the code above). You also need to give ample time so that all the required elements are loaded else you are bound to face “No Such Element Exception”. So, this was just one way of scraping through data, one can also use the BeautifulSoup library to do the same task, but it has its set of advantages and disadvantages.
Note: The entire code for this project can be found on the following GitHub page: Code_File. This is also part of my Data Analysis project from a scratch project (In Progress) which will be updated in the same GitHub repo.
This is my first blog, there is always room for improvement, and any tips, suggestions are always welcome 😊.






Quite informative, well written