This article was published as a part of the Data Science Blogathon
Introduction
A technology that makes the interaction between humans and machines in natural language possible, is an Artificial Intelligence Chatbot! They act like a typical search engine but with more enhanced features. Applications of Artificial Intelligence Chatbots are spread over various domains including eCommerce, healthcare, education, travel, automation, finance, hospitality, insurance, and so on. The chatbots are domain-specific and do what they are intended for. The applications in their domain include: answering customer queries, booking services like flights, movie tickets, product recommendation, feedback collection, reminders, bill payments, money transfers, and several others depending on the domain in which they are used.
Chatbots can be built from scratch or you can use existing frameworks offered. Some of the frameworks include Microsoft Bot Framework, Wit.ai, Dialogflow, IBM Watson, Pandorabots, and MobileMonkey. Rasa Stack is one such framework based on Machine Learning. Some of the features include Custom Models, Connect your APIs, Exact entities, Recognize Intents, and Full Data Control. The two main components of Rasa Stack are RASA NLU and RASA Core. In this article, we will look at what it does and how it does.
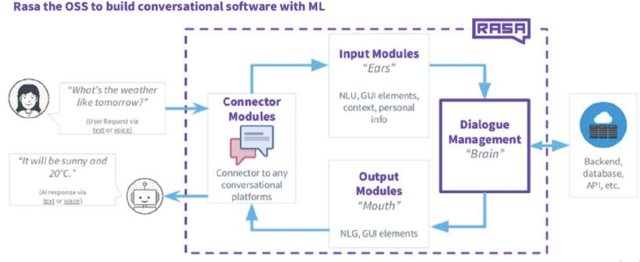
The RASA NLU is for understanding user messages. This part of the framework is a tool/library for intent classification and entity extraction from the query text. The goal is to extract structured info from user messages. Response retrieval is enabled by the entities and intents and composition of the utterance text. It has different components for extracting the intents and entities, which might need additional dependency. Eg.: Spacy, Tensorflow. Though you need to install spacy separately, TensorFlow is installed automatically when you do Rasa.
The RASA Core holds conversations and decides what’s next. This component is the dialogue engine for the framework and helps in building more complex AI assistants that are capable of handling context while responding. You can connect and deploy your bot in a messaging platform of your choice such as Telegram, Slack, Facebook Messenger, Cisco Webex, and even in your own website.
What is happening?
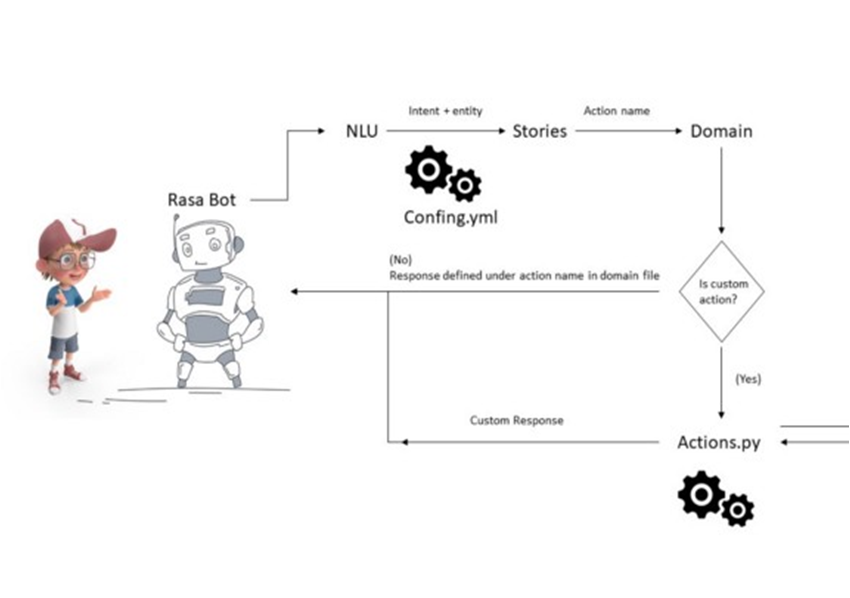
When a message is given as input by the user, it is passed on to the interpreter which then converts it into a dictionary.
The tracker keeps track of the conversation state. When a new message has come, it receives that info. And the policy then receives the current state of the tracker.
The policy decides the action to be taken which is again logged by the tracker. It is to keep track of the path or flow of the conversation.
A response as chosen by the policy is then finally sent to the user. The user then responds to the message received from the bot.
And the cycle goes on till the user breaks it.
Intents, Entities, and Stories
NLU Training Data consists of examples of user utterances categorized by intents. Training examples can also include entities. Entities are structures pieces of information that can be extracted from a user’s message. What a user is trying to say or do in a given message is called the intent.
For example, message: How to send an email? The user here asks about sending an email to someone. He intends to send an email. That is the intent then. Intent: Send an email.
Structured pieces of information that are extracted from user’s messages are called entities. The information that an assistant needs for its user goals can be extracted for entities. Other than that, everything else can be removed.
Eg.: Message: How to send an email to my dad? Intent: Send an email. The entity here is, my dad. That’s the information needed in addition to the intent.
In addition to that, items that can be defined under the NLU key are Synonyms, Lookup tables, Training examples, and Regular expressions.
What are stories? It is a representation of a conversation between a user and an AI assistant. It is similar to telling someone what happened. We don’t tell every word by word unless it is necessary. We only tell them the intents and entities when needed and the reply. But in these stories, the responses are expressed as action names.
For example, look at this conversation.
User: Hello.
Chatbot: Hey ya! How can I help you?
User: Who are you?
Chatbot: I am a chatbot, developed by Keerthz.
User: Can you tell me about football in Hindi?
Chatbot:
User: Bye.
Chatbot: You can ask me anything at any time.
When this conversation is converted into story,
story: football info
steps:
– intent: greet
– action: utter_ask_howcanhelp
– intent: intro
– action: utter_intro
– intent: intro_football
– entities: language: ‘Hindi’
– action: utter_football_intro
– intent: bye
– action: utter_helpanytime

An example of a story.
Rasa Configuration
__init__.py is an empty file that helps Python with finding your actions.
Custom actions are to be defined here at actions.py. Multiple python scripts can be created for Rasa custom actions.
config.yml – configuration for NLU and core models. The pipeline needs to be defined here if you are using any (Spacy or Tensorflow). Machine learning or Deep learning knowledge is required to handle this file.
If you are connecting your bot with other services, the credentials and token is to be maintained at credentials.yml. If you are planning to deploy your bot in Telegram, the credentials of the same should go here.
Your training data should be defined at data/nlu.md. Things like intents go here.
Stories can be added to data/stories.md
domain.yml is your assistant’s domain. This file combines Different Intents which a chatbot can detect and a list of Bot’s replies.
Conclusion
These are the ABCs of creating a chatbot. You can create a simple chatbot easily in few steps. So, why wait. Try making one.
I’m Keerthana, a data science student fascinated by Math and its applications in other domains. I’m also interested in writing Math and Data Science related articles. You can connect with me on LinkedIn and Instagram. Check out my other articles here.







