This article was published as a part of the Data Science Blogathon
Introduction:
This article will go through how to implement a neural network model using Keras on the FIFA dataset. The complete process would include some data pre-processing and cleaning and we feed it to our Neural Network model to predict some results.
Understanding FIFA dataset:

Source: https://www.ea.com/games/fifa/news/fifa-19-gameplay
The dataset used for our problem has complete data about all the players and their attributes data in FIFA-19 games by EA Sports. It includes all competitive football player’s details. We can get the dataset from this link: https://www.kaggle.com/karangadiya/fifa19
We have 18207 player’s details with around 88 features for each player. The position of the player is a feature which we would like to predict with the help of the rest of the features available with us. So here we train our Deep learning model to classify the test data and predict to which position the player would be belonging to with all the attributes associated with that player. Before diving into the neural network model let us wrangle a bit of the dataset. The following shows the heatmap of some of the features that are important for our classification task:
.png)
We can see at the bottom all the goalkeeper’s attributes are highly linked with each other. If we see the first column then we can see that concerning finishing most of the value above 0.8 includes features like Volleys, Dribbling, Long Shot, Positioning, etc.. and we know these are traits of an attacker or a top-class midfield and players with these traits are wonderful finishers. We can see similar correlations between many other features in our correlation matrix.
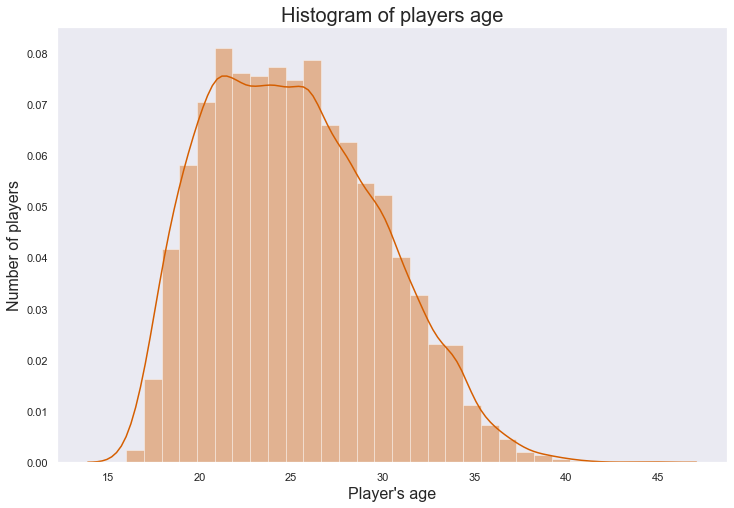
Using the histogram, we can understand that most players age ranges from 20 to 26. In football, the age of 26 is considered to be prime. Players usually start to retire after the age of 30 and that is the reason why we have a dip in bin heights from age 30.
As we know that we intend to predict the position of the player given their attributes. So, let us now visualize how is the position distribution in our dataset.
.png)
The striker position is the highest number followed by GoalKeepers. Attacking midfielders and Wing forward players are the lowest in the dataset. We group these positions into categories. Attacker – 3, Midfielder – 2, Defender – 1, Goalkeeper – 0
.png)
Even though striker positions were highest-numbered when we group them into categories, we can observe that midfield is dominating the overall count.
Finally, the top 5 players with the highest overall score are:

Source:https://timesofindia.indiatimes.com/sports/football/champions-league/top-stories/never-saw-lionel-messi-as-a-rival-says-cristiano-ronaldo/articleshow/79643091.cms
We just went through and understood a bit about the dataset. We categorized each of the positions into a category and there are four key positions. Now, we can use a Neural Network and implement perform multi-class classification.
Keras Implementation:
1. Import all the required libraries and read data:
# Data visualization import matplotlib.pyplot as plt import seaborn as sns import numpy as np import pandas as pd import seaborn as sns # Keras from keras.models import Sequential from keras.layers import Dense from keras.optimizers import SGD, Adam, Adadelta, RMSprop import keras.backend as K # Train-Test from sklearn.model_selection import train_test_split # Scaling data from sklearn.preprocessing import StandardScaler # Classification Report from sklearn.metrics import classification_report
from keras.utils.np_utils import to_categorical
df = pd.read_csv('data.csv')
Our first task is to import all the required libraries for our problem. We are using Keras library to build our sequential model and we can see I have imported the required packages in Keras.
2. Remove all null values from position:
# Remove Missing Values na = pd.notnull(df["Position"]) df = df[na]
When we are using Keras’s sequential model, our dataset mustn’t contain any null value. If we get a null value we will encounter an error. As we are predicting the position feature we drop all possible null values in this column.
3. Get the required features for our classification problem:
df = df[["Position", 'Finishing', 'HeadingAccuracy', 'ShortPassing', 'Volleys', 'Dribbling',
'Curve', 'FKAccuracy', 'LongPassing', 'BallControl', 'Acceleration',
'SprintSpeed', 'Agility', 'Reactions', 'Balance', 'ShotPower',
'Jumping', 'Stamina', 'Strength', 'LongShots', 'Aggression',
'Interceptions', 'Positioning', 'Vision', 'Penalties', 'Composure',
'Marking', 'StandingTackle', 'SlidingTackle', 'GKDiving', 'GKHandling',
'GKKicking', 'GKPositioning', 'GKReflexes']]
The above are all the required features which we need to take into consideration. The Position feature here is the Y value or target variable and the rests are input variables or X. All other features like Name, Age, etc… are not used for our prediction purpose.
4. Categorizing positions:
forward_player = ["ST", "LW", "RW", "LF", "RF", "RS","LS", "CF"] midfielder_player = ["CM","RCM","LCM", "CDM","RDM","LDM", "CAM", "LAM", "RAM", "RM", "LM"] defender_player = ["CB", "RCB", "LCB", "LWB", "RWB", "LB", "RB"]
df.loc[df["Position"] == "GK", "Position"] = 0 df.loc[df["Position"].isin(defender_player), "Position"] = 1 df.loc[df["Position"].isin(midfielder_player), "Position"] = 2 df.loc[df["Position"].isin(forward_player), "Position"] = 3
As we discussed earlier, we categorize the position in this step.
5. Standard Scaling of features:
x = df.drop("Position", axis = 1)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
x = pd.DataFrame(sc.fit_transform(x))
y = df["Position"]
Before passing the data into the neural network, we use StandardScalar to scale all values using the fit_transform function.
6. Converting prediction to categorical:
y_cat = to_categorical(y)
Just convert y into categorical type for encoding.
7. Test Train Split:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x.values, y_cat, test_size=0.2)
We split the dataset into 20% of test data and 80% of training data.
8. Build the model:
model = Sequential() model.add(Dense(60, input_shape = (33,), activation = "relu")) model.add(Dense(15, activation = "relu")) model.add(Dropout(0.2)) model.add(Dense(4, activation = "softmax")) model.compile(Adam(lr = 0.01), "categorical_crossentropy", metrics = ["accuracy"]) model.summary()

The above diagram explains the neural network model we have build. The model has two reLU units and the final layer which is a dense layer that has softmax activation for predicting multi-class probability output. We use a dropout of 0.2 in between for regularization. We have also used the categorical cross-entropy as our loss function with the Adam optimizer.
9. Fit the model and run for 10 epochs:
model.fit(x_train, y_train, verbose=1, epochs=10)
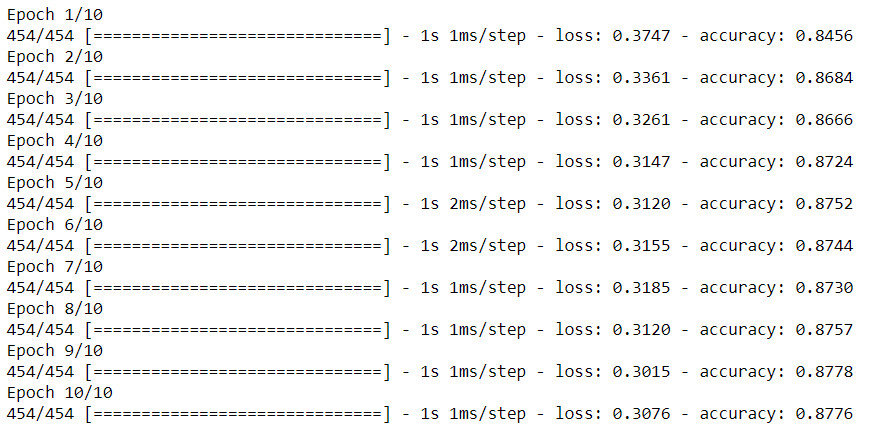
We could achieve around 87.7% accuracy within the first 10 epochs.
10. Confusion Matrix:
y_pred_class = model.predict_classes(x_test) from sklearn.metrics import confusion_matrix y_pred = model.predict(x_test) y_test_class = np.argmax(y_test, axis=1) confusion_matrix(y_test_class, y_pred_class)
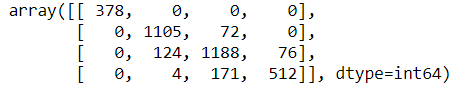
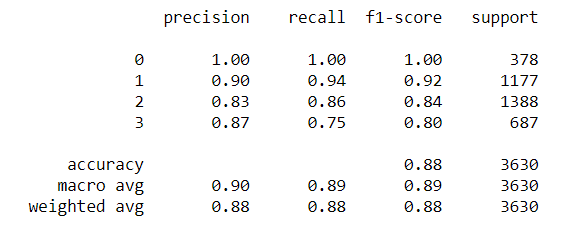
11. Classification Report:
from sklearn.metrics import classification_report print(classification_report(y_test_class, y_pred_class))
References:
1. https://keras.io/guides/sequential_model/
2. https://www.kaggle.com/karangadiya/fifa19
3. https://www.kaggle.com/ekrembayar
4. Image: https://unsplash.com/photos/eCktzGjC-iU
Conclusion:

Source:https://www.insidesport.co/euro-2020-paul-pogba-scores-wonder-goal-during-france-vs-switzerland-match-celebrates-with-unique-dance-watch/
In this article, we saw how we can use a simple neural network in a multi-class classification problem using FIFA – 19 players dataset. You can find complete code implementation here
About Me: I am a Research Student interested in the field of Deep Learning and Natural Language Processing and currently pursuing post-graduation in Artificial Intelligence.
Feel free to connect with me on:
1. Linkedin:https://www.linkedin.com/in/siddharth-m-426a9614a/
2. Github:https://github.com/Siddharth1698
Passionate about artificial intelligence, I am dedicated to advancing research in Generative AI and Large Language Models (LLMs). My work focuses on exploring innovative solutions and pushing the boundaries of what's possible in this dynamic and transformative field.





Hello, Thank you very much. Really helpful. There is one missing import from Keras under (1): 'from keras.layers import Dropout' and if I am not wrong, a deprecated call with the newer version of keras I am using under (10): 'model.predict_classes(x_test)' should be replaced by 'np.argmax(model.predict(x), axis=-1)'