Introduction:
Before we get started, let me just tell you what the Python Collection Module actually means. We can say that a file containing python statements and definitions is known as a module. It can also contain runnable code. Creating a group of all the related modules makes the code easier to understand and use as well as making it organized.
This article was published as a part of the Data Science Blogathon.
*Feel free to skip this portion if you are already aware of what the module is.
from math import sqrt
print(sqrt(4))Output: 2.0In this example, math is a module from which we are importing a specific attribute sqrt() square root function. So now that you are aware of what the Python Collection Module actually means, let’s understand some modules.
Collections Module

This is a module that comprises some different types of containers. And we know that Containers helps us in storing different type of objects and provide a way to access them and iterate over them.
The containers that will be understanding in this article are:
- Counters.
- Default Dictionary.
- Chain Maps
- Named Tuple.
Counters Module

Suppose you want to count the number of occurrences of each element in the container, you can use the counter function. Let’s see an example for this:
Importing counter from the collections module
from collections import CounterThen let’s initialize a list with random numbers and print the count of occurrences of each element.
random_list =[1,2,2,3,32,25,2,423,43,3432,3,52,54,5,5345,344,3344,5,54354,34,454]
Counter(random_list)
Let’s take another example of string
string = "I am going to count the number of words in this sentence: Analytics Vidhya brings you the power of a community that comprises data practitioners, thought leaders, and corporates leveraging data to generate value for their businesses."
word = string.split()
Counter(word)
Also Read: Python Interview Questions to Ace Your Next Job Interview in 2024
Default Dictionary Module

We know that Dictionary helps us in storing our elements in key-value pairs just like maps and keys need to be unique and are immutable. What we’re going to do here is see what happens in a normal dictionary and then what happens with the default dictionary.
Let’s create a simple dictionary and print it:
normal_dict = {'A':1,'B':2,'C':3,'D':4,'E':5}
normal_dict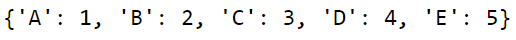
Now let’s call a key A:
normal_dict['A']We get output 1 as expected.
But now, what if we try to call a key that is not present?
normal_dict['F']
It says hey we have a key Error, this key doesn’t exist in the dictionary. In certain situations, especially when you’re doing something like a for loop that you want to quickly add keys that are not already present in your dictionary for whatever particular reason, you can use a default dictionary and what a default dictionary does, the way it gets its name default dictionary is it will assign a default value if there is an instance where a key error could have occurred.
So essentially, if try to ask for a key that isn’t present in a default dictionary, it will assign it with some default value.
Let me show how we create a default dictionary:
from collections import defaultdict
default_d={'A':1,'B':2,'C':3,'D':4,'E':5}
default_d = defaultdict(lambda: 0)
default_d['F']
So here we can see that we don’t get that error anymore. Instead, it automatically assigns a default value.
Also Read: A Complete Python Tutorial to Learn Data Science from Scratch
Chain Module

Chain Map is that one data structure in Python Collection Module that people tend to ignore.
It is a data structure that allows us to treat multiple dictionaries as one. The times when you can use a chain map are: whenever you want to searches anything through multiple dictionaries, whenever you might need a chain of default values, and in some applications where you might need to compute a subset of a dictionary quite often.
For Example, let’s consider a menu of Dominos. The menu contains pizzas, Drinks, and side orders. We will store all of the items with their prices in item-price pairs.
Let’s go ahead and create 3 dictionaries:
Pizza = {'Farmhouse': 300, 'Chessy-7': 250}
Drinks = {'Coca-Cola':80,'Pepsi':80,'Red-bull':100}
SideOrders= {'Garlic Bread':120,'Tacos':90}Now we can use a chain map to build a single dictionary over these different dictionaries.
from collections import ChainMap
Menu = ChainMap(Pizza,Drinks,SideOrders)Now we can use the Menu dictionary as it was a single dictionary:
Menu['Pepsi']
So while building a Chain map what we are doing is we are just building a chain of dictionaries. When looking up an item in the menu, pizzas are looked up first, then drinks, and finally side-orders.
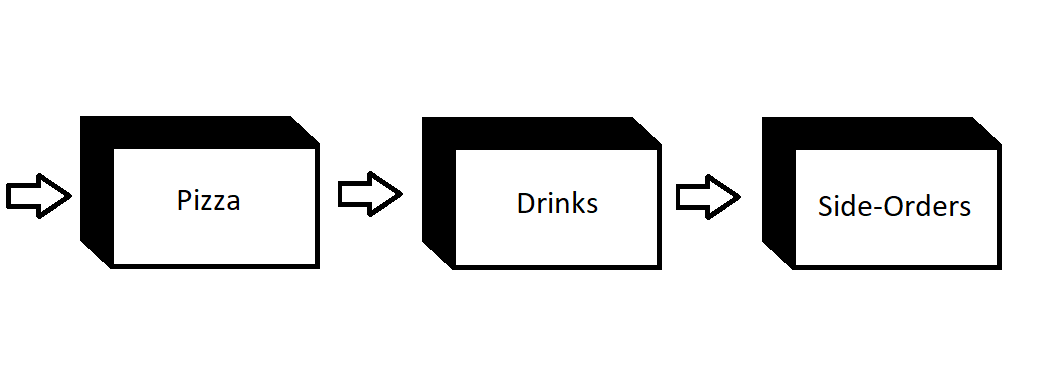
Image Source: Author
In Chain Maps official documentation, it states that it supports all the methods that are available for dictionary.
Now suppose if we want to add a new pizza we can just write:
Pizza['Margherita]=100
Menu['Margherita']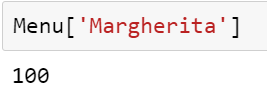
This is the updateable functionality of Chain Maps!
It also has a great String representation:
ChainMap({'Farmhouse': 300, 'Chessy-7': 250, 'Margherita': 100}, {'Coca-Cola': 80, 'Pepsi': 80, 'Red-bull': 100}, {'Garlic Bread': 120, 'Tacos': 90})Hence, using a chain map will definitely make your code much more elegant.
Named tuple Module
The last specialized containers objects that I want to show you from the collections module is called a named tuple.
So similar to the way that default dictionary tries to improve a standard/regular dictionary by getting rid of the key error.
The named tuple tries to expand on a normal tuple object by actually having named indices. So let me show you what I mean by that:
Creating a normal tuple and adding values to it:
normal_tuple = (10,20,30)
normal_tuple[1]output: 20So this is a very small tuple, which means if I wanted to grab, let’s say 20, we can see that it’s at index 1 and then we have 10 returned to us.
So we just need to look up at the index pass it in and we’re good.
Now, in certain situations, you may have a large tuple or you may not remember which value is at which index. So named tuple is going to have not just a numeric connection to the values, but it will also have essentially a named index for that value. So instead of calling it with a 1, we could call it by some sort of string code.
Let me show you how we can construct a named tuple.
normal_dict = {‘A’:1,’B’:2,’C’:3,’D’:4,’E’:5}
normal_dict
Named_tuple = namedtuple()There are two main parameters here which are,
- typename – what type this will be reported as.
- fieldname – passed in as a list.
from collections import namedtuple
Article = namedtuple('Article',['title','domain','number_of_words'])Sentimental_analysis = Article('Sentimental_analysis','NLP','1000')
Sentimental_analysis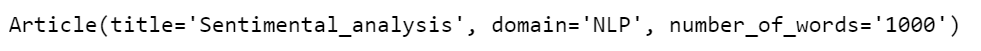
Now if we take look at the Article notice, it looks kind of like a mix between an object you would create in oop and tuple itself.
So essentially, it’s kind of like a tuple we created before where we had 10,20,30. But notice how there’s essentially an association with each value.
Now we call this
Sentimental_analysis.domain
as if they were just attributes.
We can even call by using indices if we want,
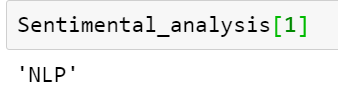
So that’s it for the collections module.
Conclusion
Alright, So we wrap it up here. To sum up, we have seen together several build-in modules that are available in python. With respect to each container, we have seen some concrete usage examples, how they can be used in real life and implemented practically. Now go ahead tinker with all the stuff you have learned today and also check the official documentation to get a tighter grip on the collections module.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.





