This article was published as a part of the Data Science Blogathon
Introduction
Imagine walking into a bookstore to buy a book on world economics and not being able to figure out the section of the store that has this book, assuming the bookstore has simply stacked all types of books together. You then realize how important it is to divide the bookstore into different sections based on the type of book.
Topic Modelling is similar to dividing a bookstore based on the content of the books as it refers to the process of discovering themes in a text corpus and annotating the documents based on the identified topics.
When you need to segment, understand, and summarize a large collection of documents, topic modelling can be useful.
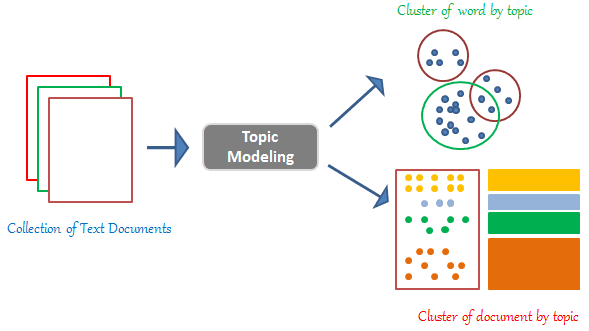
Topic Modelling using LDA:
Latent Dirichlet Allocation (LDA) is one of the ways to implement Topic Modelling. It is a generative probabilistic model in which each document is assumed to be consisting of a different proportion of topics.
How does the LDA algorithm work?
The following steps are carried out in LDA to assign topics to each of the documents:
1) For each document, randomly initialize each word to a topic amongst the K topics where K is the number of pre-defined topics.
2) For each document d:
For each word w in the document, compute:
- P(topic t| document d): Proportion of words in document d that are assigned to topic t
- P(word w| topic t): Proportion of assignments to topic t across all documents from words that come from w
3) Reassign topic T’ to word w with probability p(t’|d)*p(w|t’) considering all other words and their topic assignments
The last step is repeated multiple times till we reach a steady state where the topic assignments do not change further. The proportion of topics for each document is then determined from these topic assignments.
Illustrative Example of LDA:
Let us say that we have the following 4 documents as the corpus and we wish to carry out topic modelling on these documents.
Document 1: We watch a lot of videos on YouTube.
Document 2: YouTube videos are very informative.
Document 3: Reading a technical blog makes me understand things easily.
Document 4: I prefer blogs to YouTube videos.
LDA modelling helps us in discovering topics in the above corpus and assigning topic mixtures for each of the documents. As an example, the model might output something as given below:
Topic 1: 40% videos, 60% YouTube
Topic 2: 95% blogs, 5% YouTube
Document 1 and 2 would then belong 100% to Topic 1. Document 3 would belong 100% to Topic 2. Document 4 would belong 80% to Topic 2 and 20% to Topic 1.
This assignment of topics to documents is carried out by LDA modelling using the steps that we discussed in the previous section. Let us now apply LDA to some text data and analyze the actual outputs in Python.
Topic Modelling using LDA in Python:
We have taken the ‘Amazon Fine Food Reviews’ data from Kaggle (https://www.kaggle.com/snap/amazon-fine-food-reviews) here to illustrate how we can implement topic modelling using LDA in Python.
Reading the Data:
We start by importing the Pandas library to read the CSV and save it in a data frame.
Python Code:
import pandas as pd
import nltk
from nltk.corpus import stopwords #stopwords
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import word_tokenize
#from sklearn.feature_extraction.text import TfidfVectorizer
rev = pd.read_csv(r"Reviews.csv")
print(rev.head())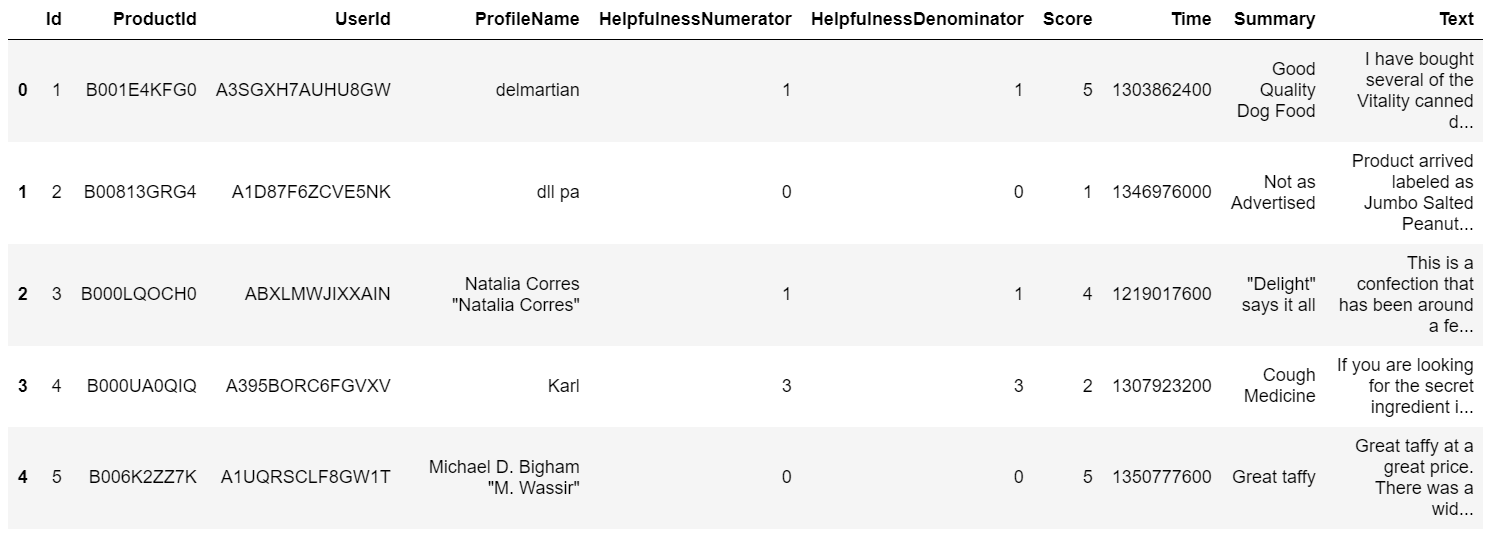
We are interested in carrying out topic modelling for the ‘Text’ column in this dataset.
Importing the necessary libraries:
We will need the NLTK library to be imported as we will use lemmatization for pre-processing. Additionally, we would also remove the stop-words before carrying out the LDA. To carry out topic modelling, we need to convert our text column into a vectorized form and therefore we import the TfidfVectorizer.
import nltk
from nltk.corpus import stopwords #stopwords
from nltk.stem import WordNetLemmatizer
from sklearn.feature_extraction.text import TfidfVectorizer
stop_words=set(nltk.corpus.stopwords.words('english'))
Pre-processing the text:
We will apply lemmatization to the words so that the root words of all derived words are used. Furthermore, the stop-words are removed and words with lengths greater than 3 are used.
def clean_text(headline): le=WordNetLemmatizer() word_tokens=word_tokenize(headline) tokens=[le.lemmatize(w) for w in word_tokens if w not in stop_words and len(w)>3] cleaned_text=" ".join(tokens) return cleaned_text rev['cleaned_text']=rev['Text'].apply(clean_text)
TFIDF vectorization on the text column:
Carrying out a TFIDF vectorization on the text column gives us a document term matrix on which we can carry out the topic modelling. TFIDF refers to Term Frequency Inverse Document Frequency – as this vectorization compares the number of times a word appears in a document with the number of documents that contain the word.
vect =TfidfVectorizer(stop_words=stop_words,max_features=1000) vect_text=vect.fit_transform(rev['cleaned_text'])
LDA on the vectorized text:
The parameters that we have given to the LDA model, as shown below, include the number of topics, the learning method (which is the way the algorithm updates the assignments of the topics to the documents), the maximum number of iterations to be carried out and the random state. The parameters that we have given to the LDA model, as shown below, include the number of topics, the learning method (which is the way the algorithm updates the assignments of the topics to the documents), the maximum number of iterations to be carried out and the random state.
from sklearn.decomposition import LatentDirichletAllocation lda_model=LatentDirichletAllocation(n_components=10, learning_method='online',random_state=42,max_iter=1) lda_top=lda_model.fit_transform(vect_text)
Checking the results:
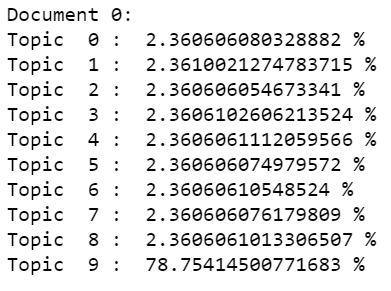
We can check the proportion of topics that have been assigned to the first document using the lines of code given below.
print("Document 0: ")
for i,topic in enumerate(lda_top[0]):
print("Topic ",i,": ",topic*100,"%")
Analyzing the Topics:
Let us check what are the top words that comprise the topics. This would give us a view of what defines each of these topics.
vocab = vect.get_feature_names()
for i, comp in enumerate(lda_model.components_):
vocab_comp = zip(vocab, comp)
sorted_words = sorted(vocab_comp, key= lambda x:x[1], reverse=True)[:10]
print("Topic "+str(i)+": ")
for t in sorted_words:
print(t[0],end=" ")
print("n")

In addition to LDA, other algorithms can be leveraged to carry out topic modelling. Latent Semantic Indexing (LSI), Non-negative matrix factorization are some of the other algorithms one could try to carry out topic modelling. All these algorithms, like LDA, involve feature extraction from document term matrices and generating a group of terms that are differentiating from each other, which eventually lead to the creation of topics. These topics can help in assessing the main themes of a corpus and hence organizing large collections of textual data.
About Author
Nibedita
completed her master’s in Chemical Engineering from IIT Kharagpur in 2014 and
is currently working as a Senior Consultant at AbsolutData Analytics. In her
current capacity, she works on building AI/ML-based solutions for clients from
an array of industries.
Nibedita completed her master’s in Chemical Engineering from IIT Kharagpur in 2014 and is currently working as a Senior Data Scientist. In her current capacity, she works on building intelligent ML-based solutions to improve business processes.







Very nice article, I miss the end of the story, how to get the topic of each document into the original file ?