This article was published as a part of the Data Science Blogathon
Introduction
This is the first post of the NLP tutorial series. This guide will let you understand step by step how to work with text data, clean it, create new features using state-of-art methods and then make predictions or other types of analysis.
In this post, I want to focus on this task, because I remember the efforts I did in my Data Science project for my master’s degree. I still didn’t have any previous knowledge about Machine Learning and Deep Learning. Only after much research on the web and comparisons with classmates, I was able to solve the problem.
Table of Content:
- Import libraries and dataset
- Remove links
- Remove punctuations
- Remove numbers
- Remove emojis
- Remove stop words
- Tokenization
- Normalize words
1. Import libraries and dataset
Let’s import the libraries and the dataset from Kaggle, which contains the tweets collected using the Twitter API from July 2020. A filter was applied: only the tweets with #covid19 were extracted.
We can easily see the fields of the dataset, printing the information:
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
import re
df = pd.read_csv('../input/covid19-tweets/covid19_tweets.csv')
df.info()
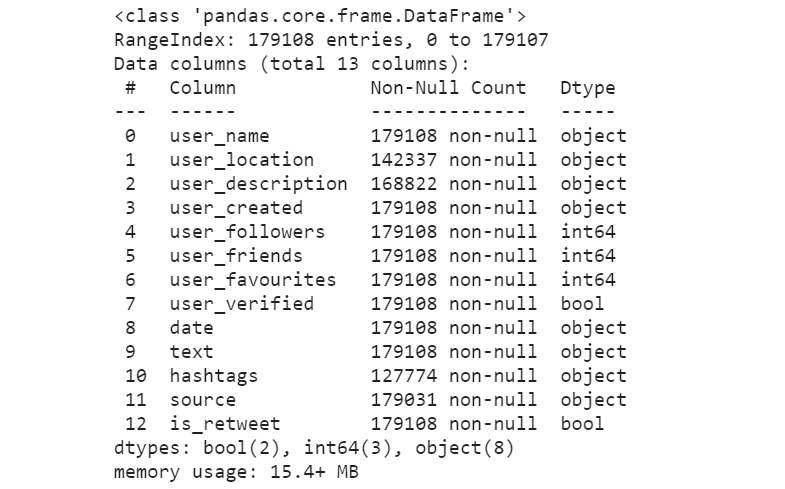
Most of the columns won’t be used in this post. We are only interested in working with the text field.
df.text

We can fastly notice that the text contains much redundant and unsuitable information. We need to clean it in the following steps.
2. Remove links
The first operation is to remove all the links since they don’t have any predicting significance:
df["clean_text"] = df["text"].apply(lambda s: ' '.join(re.sub("(w+://S+)", " ", s).split()))
df[['text','clean_text']].iloc[94807]

From the row extracted, we can easily see the difference between the original text and the resulting text after the cleaning.
3. Remove punctuations
Characters like “?”, “. “ and “,” need to be deleted. This is possible using the sub() function of the re module. It replaces a regular expression with white space.
You are probably wondering what is a regular expression. It’s used to specify a set of strings that matches it. You can find other information about the re library on the w3school website.
df["clean_text"] = df["clean_text"].apply(lambda s: ' '.join(re.sub("[.,!?:;-='..."@#_]", " ", s).split()))
df[["text","clean_text"]]
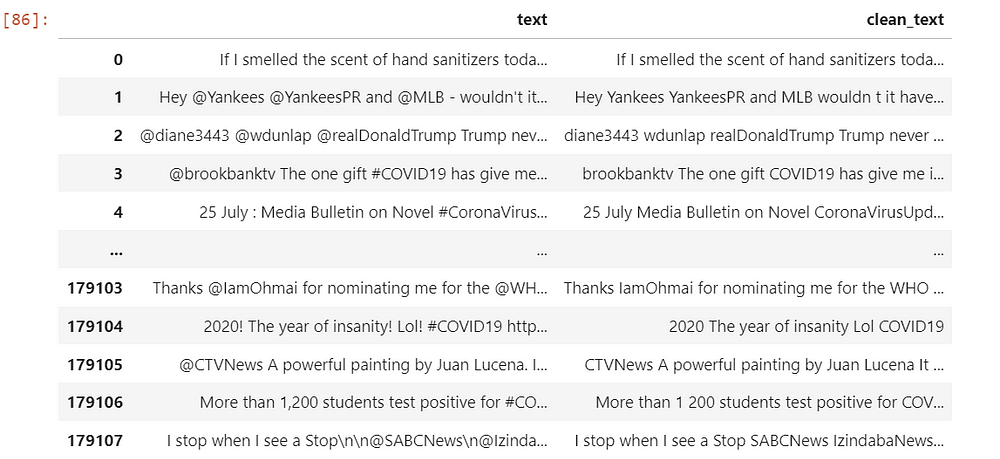
We compare again the tweets with the corresponding cleaned texts. We don’t see any more punctuations.
4. Remove numbers
We also need to remove numerical characters in the text. They don’t use information by themselves. These characters can be easily deleted using the replace function.
df["clean_text"].replace('d+', '', regex=True, inplace=True)
df[["text","clean_text"]]

5. Remove emojis
The emojis are removed since they can’t be analyzed. The apply function takes the deEmojify function, which is applied to every row of the data frame. In the function, we first encode the string using the ASCII encoding, and then we decode it. In this way, we are able to delete the emojis.
def deEmojify(inputString):
return inputString.encode('ascii', 'ignore').decode('ascii')
df["clean_text"] = df["clean_text"].apply(lambda s: deEmojify(s))
df[['text','clean_text']].iloc[12]

6. Remove stop words
The stop words are terms used for the sake of correct sentence formations but don’t have any significant insights. Examples of these words are “why”, “what”,” how”. So, these words are more noisy than informative. For this reason, we need to remove them. Luckily, we don’t need to specify manually the stop words, but they are already provided by the nltk module.
import nltk
from nltk.corpus import stopword
snltk.download('stopwords')
stop = set(stopwords.words('english'))
print(stop)

def rem_en(input_txt):
words = input_txt.lower().split()
noise_free_words = [word for word in words if word not in stop]
noise_free_text = " ".join(noise_free_words)
return noise_free_text
df["clean_text"] = df["clean_text"].apply(lambda s: rem_en(s)) df[["text","clean_text"]]

The function apply takes the rem_en function, which is applied to all the rows of the data frame df. At the same time, we convert all the text to the lower case.
7. Tokenization
We simply split the text into tokens. In other words, the string is converted into a list, where each element corresponds to a word. The module nltk provides tokenize function to tokenize the tweets.
from nltk.tokenize import RegexpTokenizer tokeniser = RegexpTokenizer(r'w+') df["clean_text"] = df["clean_text"].apply(lambda x: tokeniser.tokenize(x)) df[["text","clean_text"]]

8. Normalize words
The last step consists in normalizing the text. What does it mean? We want to convert a word to its base form. For example, playing, plays and play can seem different to the computer, but they are the same thing. We need to produce the root forms of these words. The nltk module plays a relevant role this time too. It provides the WordNetLemmatizer function, which looks for the lemmas of the words using a database, called WordNet.
from nltk.stem import WordNetLemmatizer lemmatiser = WordNetLemmatizer() df["clean_text"] = df["clean_text"].apply(lambda tokens: [lemmatiser.lemmatize(token, pos='v') for token in tokens]) df[["text","clean_text"]]
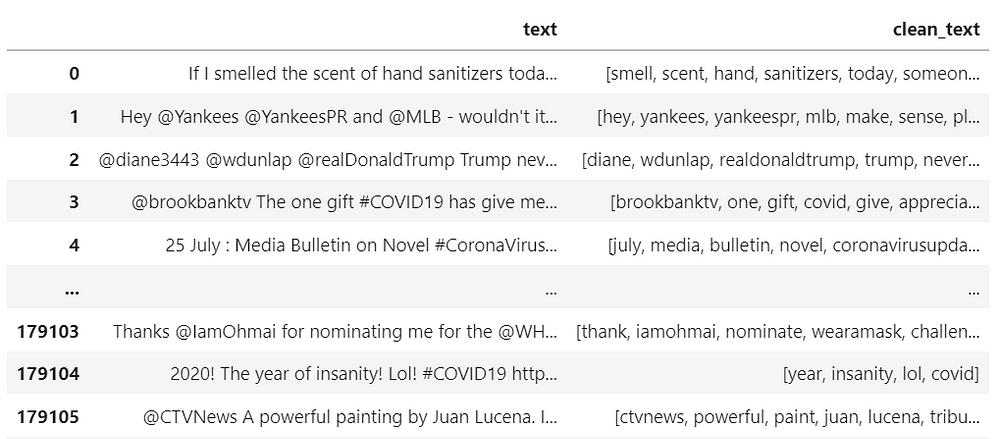
From the output, we can check the final text. Words, like “smelled” and “nominating”, were transformed into their corresponding root forms, “smell” and “nominate”.
Final thoughts
Congratulations! You reached the end of this tutorial! I hope you found it useful in some ways. There are surely other operations that can be done, like transform emojis into words. Or you can remove one step, like the one to delete numbers. At first, they could seem not informative, but numbers like “2020”, which is the year of Covid, can be instead useful. I presented the most fundamental steps to pre-process text data. The next posts of these series will focus on extracting features from the already cleaned text. Thanks for reading. Have a nice day!
Author Bio:
Eugenia Anello has a statistics background and is pursuing a master’s degree in Data Science at the University of Padova. She enjoys writing data science posts on Medium and on other platforms. Her purpose is to share the knowledge acquired in a simple and understandable way.




that was quite comprehensive guide to text preprocessing