Introduction
The need for deeper networks emerges while handling complex tasks. However, training a deep neural net has a lot of complications not only limited to overfitting and high computation costs but also has some non-trivial problems. In this article, we will solve some complex deep learning problems using skip connections.
Table of contents
Why Skip Connections?
The beauty of deep neural networks is that they can learn complex functions more efficiently than their shallow counterparts. While training deep neural nets, the performance of the model drops down with the increase in depth of the architecture. This is known as the degradation problem. But, what could be the reasons for the saturation inaccuracy with the increase in network depth? Let us try to understand the reasons behind the degradation problem.
Deeper Network Performance Analysis: Overfitting Discarded
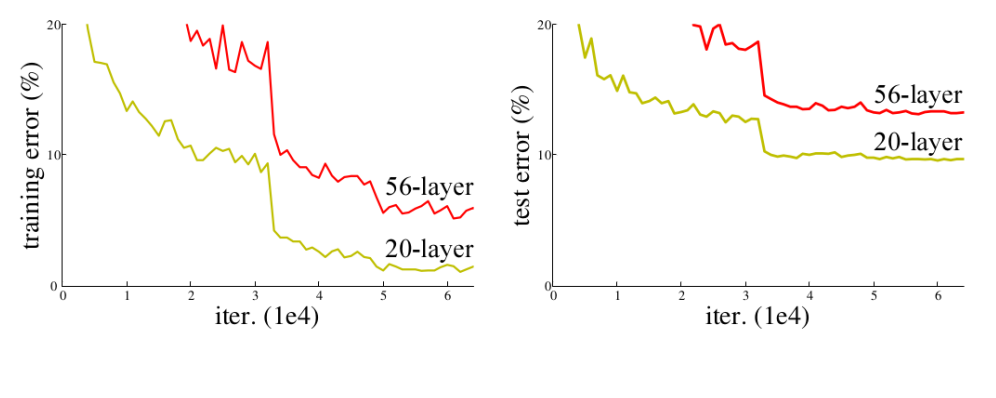
One of the possible reasons could be overfitting. The model tends to overfit with the increase in depth but that’s not the case here. As you can infer from the below figure, the deeper network with 56 layers has more training error than the shallow one with 20 layers. The deeper model doesn’t perform as well as the shallow one. Clearly, overfitting is not the problem here.
Gradient Issues in ResNet Construction
Another possible reason can be vanishing gradient and/or exploding gradient problems. However, the authors of ResNet (He et al.) argued that the use of Batch Normalization and proper initialization of weights through normalization ensures that the gradients have healthy norms. But, what went wrong here? Let’s understand this by construction.
Consider a shallow neural network that was trained on a dataset. Also, consider a deeper one in which the initial layers have the same weight matrices as the shallow network (the blue colored layers in the below diagram) with added some extra layers (green colored layers). We set the weight matrices of the added layers as identity matrices (identity mappings).
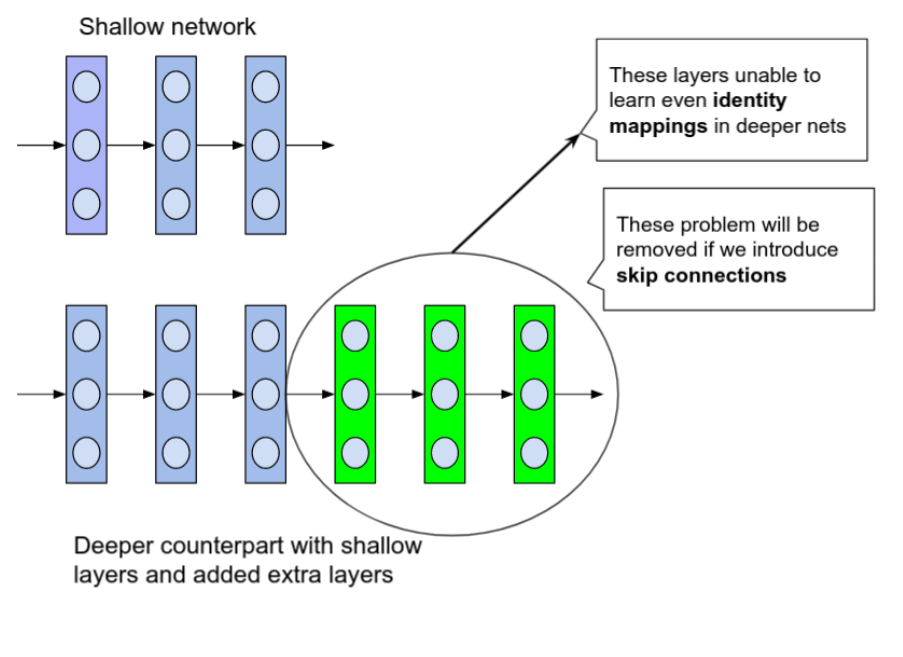
From this construction, the deeper network should not produce any higher training error than its shallow counterpart because we are actually using the shallow model’s weight in the deeper network with added identity layers. But experiments prove that the deeper network produces high training error comparing to the shallow one. This states the inability of deeper layers to learn even identity mappings.
The degradation of training accuracy indicates that not all systems are similarly easy to optimize.
One of the primary reasons is due to random initialization of weights with a mean around zero, L1, and L2 regularization. As a result, the weights in the model would always be around zero and thus the deeper layers can’t learn identity mappings as well.
Here comes the concept of skip connections which would enable us to train very deep neural networks. Let’s learn this awesome concept now.
What are Skip Connections?
Skip Connections (or Shortcut Connections) as the name suggests skips some of the layers in the neural network and feeds the output of one layer as the input to the next layers.
Skip Connections were introduced to solve different problems in different architectures. In the case of ResNets, skip connections solved the degradation problem that we addressed earlier whereas, in the case of DenseNets, it ensured feature reusability. We’ll discuss them in detail in the following sections.
How do Skip Connections Work?
Skip connections were introduced in literature even before residual networks. For example, Highway Networks (Srivastava et al.) had skip connections with gates that controlled and learned the flow of information to deeper layers. This concept is similar to the gating mechanism in LSTM. Although ResNets is actually a special case of Highway networks, the performance isn’t up to the mark comparing to ResNets. This suggests that it’s better to keep the gradient highways clear than to go for any gates – simplicity wins here!
Neural networks can learn any functions of arbitrary complexity, which could be high-dimensional and non-convex. Visualizations have the potential to help us answer several important questions about why neural networks work. And there is actually some nice work done by Li et al. which enables us to visualize the complex loss surfaces. The results from the networks with skip connections are even more surprising! Take a look at them.
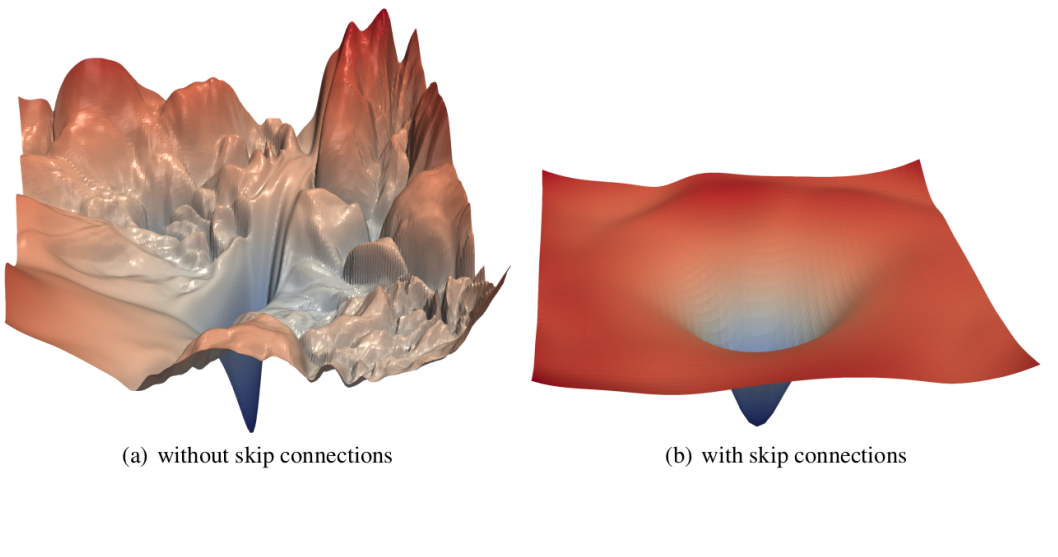
As you can see here, the loss surface of the neural network with skip connections is smoother and thus leading to faster convergence than the network without any skip connections. Let’s see the variants of skip connections in the next section.
Variants of Skip Connections
In this section, we will see the variants of skip connections in different architectures. Skip Connections can be used in 2 fundamental ways in Neural Networks: Addition and Concatenation.
Residual Networks (ResNets)
Residual Networks were proposed by He et al. in 2015 to solve the image classification problem. In ResNets, the information from the initial layers is passed to deeper layers by matrix addition. This operation doesn’t have any additional parameters as the output from the previous layer is added to the layer ahead. A single residual block with skip connection looks like this:

Thanks to the deeper layer representation of ResNets as pre-trained weights from this network can be used to solve multiple tasks. It’s not only limited to image classification but also can solve a wide range of problems on image segmentation, keypoint detection & object detection. Hence, ResNet is one of the most influential architectures in the deep learning community.
Next, we’ll learn about another variant of skip connections in DenseNets which is inspired by ResNets.
I would recommend you to go through the below resources for an in-detailed understanding of ResNets–
Densely Connected Convolutional Networks (DenseNets)
DenseNets were proposed by Huang et al. in 2017. The primary difference between ResNets and DenseNets is that DenseNets concatenates the output feature maps of the layer with the next layer rather than a summation.
Coming to Skip Connections, DenseNets uses Concatenation whereas ResNets uses Summation

The idea behind the concatenation is to use features that are learned from earlier layers in deeper layers as well. This concept is known as Feature Reusability. So, DenseNets can learn mapping with fewer parameters than a traditional CNN as there is no need to learn redundant maps.
U-Net: Convolutional Networks for Biomedical Image Segmentation
The use of skip connections influences the field of biomedical too. U-Nets were proposed by Ronneberger et al. for biomedical image segmentation. It has an encoder-decoder part including Skip Connections. The overall architecture looks like the English letter “U”, thus the name U-Nets.

The layers in the encoder part are skip connected and concatenated with layers in the decoder part (those are mentioned as grey lines in the above diagram). This makes the U-Nets use fine-grained details learned in the encoder part to construct an image in the decoder part.
These kinds of connections are long skip connections whereas the ones we saw in ResNets were short skip connections. More about U-Nets here.
Okay! Enough of theory, let’s implement a block of the discussed architectures and how to load and use them in PyTorch!
Implementation of Skip Connections
In this section, we will build ResNets and DesNets using Skip Connections from the scratch. Are you excited? Let’s go!
ResNet – A Residual Block
First, we will implement a residual block using skip connections. PyTorch is preferred because of its super cool feature – object-oriented structure.
As we have a Residual block in our hand, we can build a ResNet model of arbitrary depth! Let’s quickly build the first five layers of ResNet-34 to get an idea of how to connect the residual blocks.
PyTorch provides us an easy way to load ResNet models with pretrained weights trained on the ImageNet dataset.
DenseNet – A Dense Block
Implementing the complete densenet would be a little bit complex. Let’s grab it step by step.
- Implement a DenseNet layer
- Build a dense block
- Connect multiple dense blocks to obtain a densenet model
Next, we’ll implement a dense block that consists of an arbitrary number of DenseNet layers.
From the dense block, let’s build DenseNet. Here, I’ve omitted the transition layers of DenseNet architecture (which acts as downsampling) for simplicity.
Conclusion
In this article, we’ve discussed the importance of skip connections for the training of deep neural nets and how skip connections were used in ResNet, DenseNet, and U-Net with its implementation. I know, this article covers many theoretical aspects which are not easy to grasp in one go. So, feel free to leave comments if you have any.
Frequently Asked Question
Q1. Why skip connections in ResNet?
A. Skip connections in ResNet prevent the vanishing gradient problem during deep neural network training. These connections enable the direct flow of information from earlier layers to later layers, aiding in preserving gradient and promoting better convergence.
Q2. Why do we use skip connections in unet?
A. Skip connections in U-Net are employed to address the challenge of information loss during down-sampling and up-sampling in image segmentation tasks. These connections help merge features from different resolution levels, enhancing the model’s ability to capture fine details.
Q3. What are the different types of skip connections?
A. Types of skip connections include short and long skip connections. Short skips connect immediately adjacent layers, while long skips connect layers with larger spatial distances between them. These connections contribute to multi-scale feature extraction.
Q5. What is the difference between skip and residual connections?
A. Both skip and residual connections enable gradients to flow better, but skip connections directly concatenate or merge features from different layers, while residual connections add the original input to the transformed output, aiding in better gradient propagation and network training.



