This article was published as a part of the Data Science Blogathon
This article is focused on Apache Pig. It is a high-level platform for processing and analyzing a huge amount of data.
OVERVIEW
If we see the top-level overview of Pig, then Pig is an abstraction over MapReduce. Pig runs on Hadoop. So, it makes use of both the Hadoop Distributed File System (HDFS) and Hadoop’s processing system, MapReduce. Data flows are executed
by an engine. It is used to analyze data sets as data flows. It includes a high-level language called Pig Latin for expressing these data flows.
The input for Pig is Pig Latin which will be converted into MapReduce jobs. Pig uses MapReduce tricks to do all of its data processing. It combines Pig Latin scripts into a series of one or more MapReduce jobs that in turn executes.
Apache Pig was designed by Yahoo as it is easy to learn and work with. So, Pig makes Hadoop quite easy. Apache Pig was developed because MapReduce programming was getting quite difficult and many MapReduce users are not comfortable with declarative languages. Now, Pig is an open-source project under Apache.
TABLE OF CONTENTS
- Features of Pig
- Pig vs MapReduce
- Pig Architecture
- Pig Execution Options
- Pig Basic Execution Commands
- Pig Data Types
- Pig Operators
- Pig Latin Script Example
1. FEATURES OF PIG
Let’s look at some of the features of Pig.
- It has a rich set of operators such as join, sort, etc.
- It is easy to program as it is similar to SQL.
- The tasks in Apache Pig have been converted into MapReduce jobs automatically. The programmers need to focus only on the semantics of the language and not on MapReduce.
- Own functions can be created using Pig.
- Functions in other programming languages such as java can be embedded in Pig Latin scripts.
- Apache Pig can handle
all kinds of data such as structured, unstructured, and semi-structured data and
stores the result in HDFS.
2. PIG VS MAPREDUCE
Let’s see the difference between Pig and MapReduce.
Pig has several advantages over MapReduce.
Apache Pig is a data flow language. It means that it allows users to describe how data from one or more inputs should be read, processed, and then stored to one or more outputs in parallel. While MapReduce on the other hand is a programming style.
Apache Pig is a high-level language while MapReduce is a compiled java code.
The syntax for Pig for performing join and multiple files is very intuitive and quite simple like SQL. MapReduce code
becomes complex if you want to write joining operations.
The learning curve for Apache Pig is very small. Expertise in Java and MapReduce libraries is a must
to run MapReduce code.
Apache Pig scripts can do the equivalent of multiple lines of MapReduce code and MapReduce code takes more lines of codes to perform the same operations.
Apache Pig is easy to debug and test while MapReduce programs take a lot of time for coding, testing, etc. Pig Latin is less costly than MapReduce.
3. PIG ARCHITECTURE
Now let’s see Pig architecture.
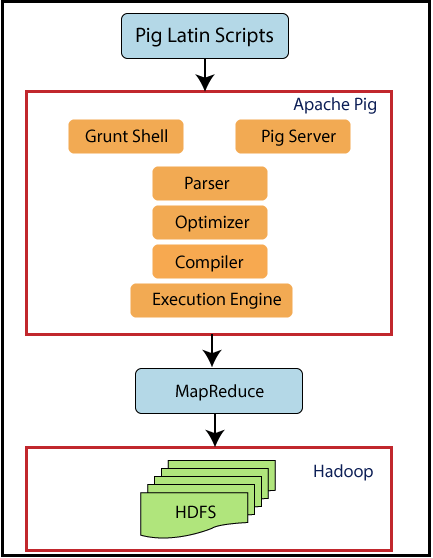
Pig sits on top of Hadoop. Pig scripts can be run either on Grunt shell or on the Pig server. Execution engine of Pig the passes optimizes and compiles the script and finally converts into MapReduce jobs. It uses HDFS to store intermediate data between MapReduce jobs and then writes its output to HDFS.
4. PIG EXECUTION OPTIONS
Apache Pig can run two run modes. Both of them produce the same results.
4.1. Local mode
Command on gateways
pig -x local
4.2. Hadoop mode
Command on gateways
pig -exectype mapreduce
Apache Pig can be run in three ways in the above two modes.
- Interactive mode / Grunt shell: enter Pig commands manually by using the grunt shell
- Batch mode / Script file: Place Pig commands in a script file and run the script
- Embedded program/UDF: embed Pig commands in java and run the scripts
5. PIG GRUNT SHELL COMMANDS
Grunt shells can be used to write Pig Latin scripts. The shell commands can be invoked by using fs and sh commands. Let’s see some basic
Pig commands.
5.1. fs command
fs command lets you run HDFS commands from Pig
5.1.1 To list all directories in HDFS
grunt> fs -ls;
Now, all the files in HDFS will be displayed.
5.1.2. To create a new directory mydir in HDFS
grunt> fs -mkdir mydir/;
The above command will create a new directory called mydir in HDFS.
5.1.3. To remove a directory
grunt> fs -rmdir mydir;
The above command will remove the created directory mydir.
5.1.4. To copy a file to HDFS
grant> fs -put sales.txt sales/;
Here, the file named sales.txt is the source file that will be copied to the destination directory in HDFS i.e. sales.
5.1.5. To quit from grunt shell
grunt> quit;
The above command will exit the grunt shell.
5.2. sh command
sh command lets you run Unix statement from Pig
5.2.1. To display the current date
grunt> sh date;
This command will show the current date.
5.2.2. To lists local files
grunt> sh ls;
This command will display all the files in the local system.
5.2.3. To execute Pig Latin from grunt shell
grunt> run salesreport.pig;
The above command will execute a Pig Latin script file “salesreport.pig” from the grunt shell.
5.2.4. To execute Pig Latin from Unix prompt
$pig salesreport.pig;
The above command will execute a Pig Latin script file “salesreport.pig” from Unix prompt.
6. PIG DATA TYPES
Pig Latin consists of the following datatypes.
6.1. Data Atom
It is a single value. It can be a string or a number. They are of scalar types such as int, float, double, etc.
For example, “john”, 9.0
6.2. Tuple
A tuple is similar to a record with a sequence of fields. It can be of any data type.
For example, (‘john’, ‘james’) is a tuple.
6.3. Data bag
It consists of a collection of tuples which is equivalent to a “table” in SQL. The tuples are non-unique and can have an arbitrary number of fields, each can be of any type.
For example, {(‘john’, ‘James), (‘king’, ‘mark’)} is a data bag which is equivalent to the below table in SQL.
| john | James |
| king | mark |
6.4. Data map
This data type
contains a collection of key-value pairs. Here, the key must be a chararray and unique. The values can be of any type.
For example, [name#(‘john’, ‘james’), age#22] is a data map where name, age are keys and (‘john, ‘james’), 22 are values.
7. PIG OPERATORS
Below is the contents of student.txt file.
John,23,Hyderabad James,45,Hyderabad Sam,33,Chennai ,56,Delhi ,43,Mumbai
7.1. LOAD
It loads data from the given file system.
A = LOAD 'student.txt' AS (name: chararray, age: int, city: chararray);
The data from the student file with column names as ‘name’, ‘age’, ‘city’ will be loaded into a variable A.
7.2. DUMP
DUMP operator is used to displaying the contents of a relation. Here, the contents of A will be displayed.
DUMP A //results (John,23,Hyderabad) (James,45,Hyderabad) (Sam,33,Chennai) (,56,Delhi) (,43,Mumbai)
7.3. STORE
The store function saves the results to the file system.
STORE A into ‘myoutput’ using PigStorage(‘*’);
Here, the data present in A will be stored into myoutput separated by ‘*’.
DUMP myoutput; //results John*23*Hyderabad James*45*Hyderabad Sam*33*Chennai *56*Delhi *43*Mumbai
7.4. FILTER
B = FILTER A by name is not null;
The FILTER operator will filter a table with some conditions. Here, the name is the column in A. Non-empty values in the name will be stored in variable B.
DUMP B; //results (John,23,Hyderabad) (James,45,Hyderabad) (Sam,33,Chennai)
7.5. FOREACH GENERATE
C = FOREACH A GENERATE name, city;
FOREACH operator is used to accessing individual records. Here, the rows present in name and city will be fetched from A and stored into C.
DUMP C //results (John,Hyderabad) (James,Hyderabad) (Sam,Chennai) (,Delhi) (,Mumbai)
8. PIG LATIN SCRIPT EXAMPLE
We have a people file that has employee id, name, and hours as fields.
001,Rajiv,21 002,siddarth,12 003,Rajesh,22
First, load this data into a variable employee. Filter it by hours less than 20 and store in parttime. Order parttime by descending order and store it in another file called part_time. Display the contents.
The script will be
employee = Load ‘people’ as (empid, name, hours); parttime = FILTER employee BY Hours < 20; sorted = ORDER parttime by hours DESC; STORE sorted INTO ‘part_time’; DUMP sorted; DESCRIBE sorted; //results (003,Rajesh,22) (001,Rajiv,21)
ENDNOTES
These are some of the basic concepts of Apache Pig. I hope you enjoyed reading this article. Start practising
with Cloudera environment.






{kind=link}
Good job.... Congrats 👍
Thanks for sharing very useful Keep rocking wish you all the best