This article was published as a part of the Data Science Blogathon
“IF YOU ARE NOT TAKING CARE OF YOUR CUSTOMERS, YOUR COMPETITOR WILL” – Bob Hooey
Overview:
Customer Lifetime Value is the profit that a business will make from a specific customer over the period of their association with the business. Every industry has its own set of metrics that are tracked and measured to help businesses target the right customer and forecast their customer base for the future. The CLV enables various departments in marketing, sales, etc to plan their strategies and offer specific products or customized services to the most valuable customers. It also provides insights to customer service teams with a framework for knowing the effort that needs to be put into nurturing and retaining customers.
The CLV is most effective and adds immense value when it is applied along with other tools such as customer segmentation, pricing & marketing strategy meaning it tells us who are our most profitable customers but it doesn’t tell us which product needs to be sold at what price and quantity. Hence, CLV should be applied judiciously and shouldn’t be the sole criteria for making business decisions. The CLV may change depending on the business model and its objective which means the definition and calculation need to be revisited regularly.
Here is how various industries use CLV:
Insurance: The marketing team would be interested in knowing which customers are most likely to pay high premiums and not claim which in turn helps them acquire new customers and also grows their business.
Telecom: The predicted CLV is used to understand the probability of current customers’ loyalty and the likelihood of them continuing with plans or subscriptions.
Retail: CLV is used to understand the purchase behavior and spend to target specific customers with customized offers/discounts.
Benefits of CLV:
- Cost of Acquisition: Helps in determining the acceptable cost of acquisition and where to put the marketing effort
- Potential Customers: Helps in identifying the future value of current customers and potential new customers
- Customer Relationship: Enables in building stronger and effective relations with customers
- Brand Loyalty: Good relation fosters in building brand loyalty
Objective:
We will explore the below steps and by the end of this blog, build the Customer Lifetime Value simulator app with plotly dash.
- Overview of Customer Lifetime Value (CLV)
- Benefits of CLV
- Data exploration
- CLV calculations
- App development with Plotly dash
- Closing note
Getting Started:
We will be using a retail dataset(CSV) from UCI machine learning repository to build the python app. The attribute description can be found in the above URL.
Let us load our dataset and take a look at the data.
data = pd.read_excel("./data/Online_Retail.xlsx")
data.head(10)
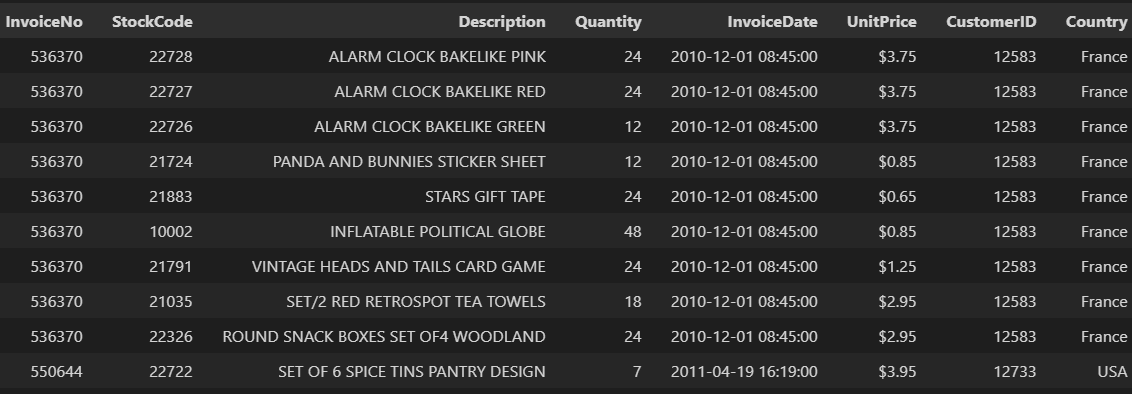
data.info()
Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 InvoiceNo 40 non-null int64 1 StockCode 40 non-null object 2 Description 40 non-null object 3 Quantity 40 non-null int64 4 InvoiceDate 40 non-null datetime64[ns] 5 UnitPrice 40 non-null float64 6 CustomerID 40 non-null int64 7 Country 40 non-null object dtypes: datetime64[ns](1), float64(1), int64(3), object(3)
Data pre-processing:
Let us clean the data and also create new features that we will need in later stages for calculating the CLV.
- Data cleaning: Remove duplicate records
- Quantity: We will consider only positive quantities. Any negative value indicates that the product was returned for some reason.
- Total Purchase: This will be a product of UnitPrice x Quantity
- Aggregation: As the data is at the transaction level, let’s aggregate data by CustomerID and Country. We will do this by using a group by function.
- Avg order value: This will be a ratio of money spent to the number of transactions
- Purchase Frequency: This is the ratio of the sum of transactions to the total number of transactions. It is the average number of orders from each customer.
- Churn Rate: This is the percentage of customers who have not ordered again.
- CLTV: (Average Order Value x Purchase Frequency) / Churn Rate)
- Also, let’s rename some of the column names to make them easy to track.
The data would look as below after completing the above steps. We will process this further as we go along.

Complete code can be accessed from pre-processing.py
App Development with Plotly Dash:
We’ll develop our app with Plotly Dash, which is a python framework for building data applications. Let us create a file by name app.py and start with loading libraries.
Step 1: Loading Libraries
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import datetime as dt import numpy as np import dash import dash_table import dash_core_components as dcc import dash_html_components as html from dash.dependencies import Input, Output, State
Step 2: Designing the Layout (UI)
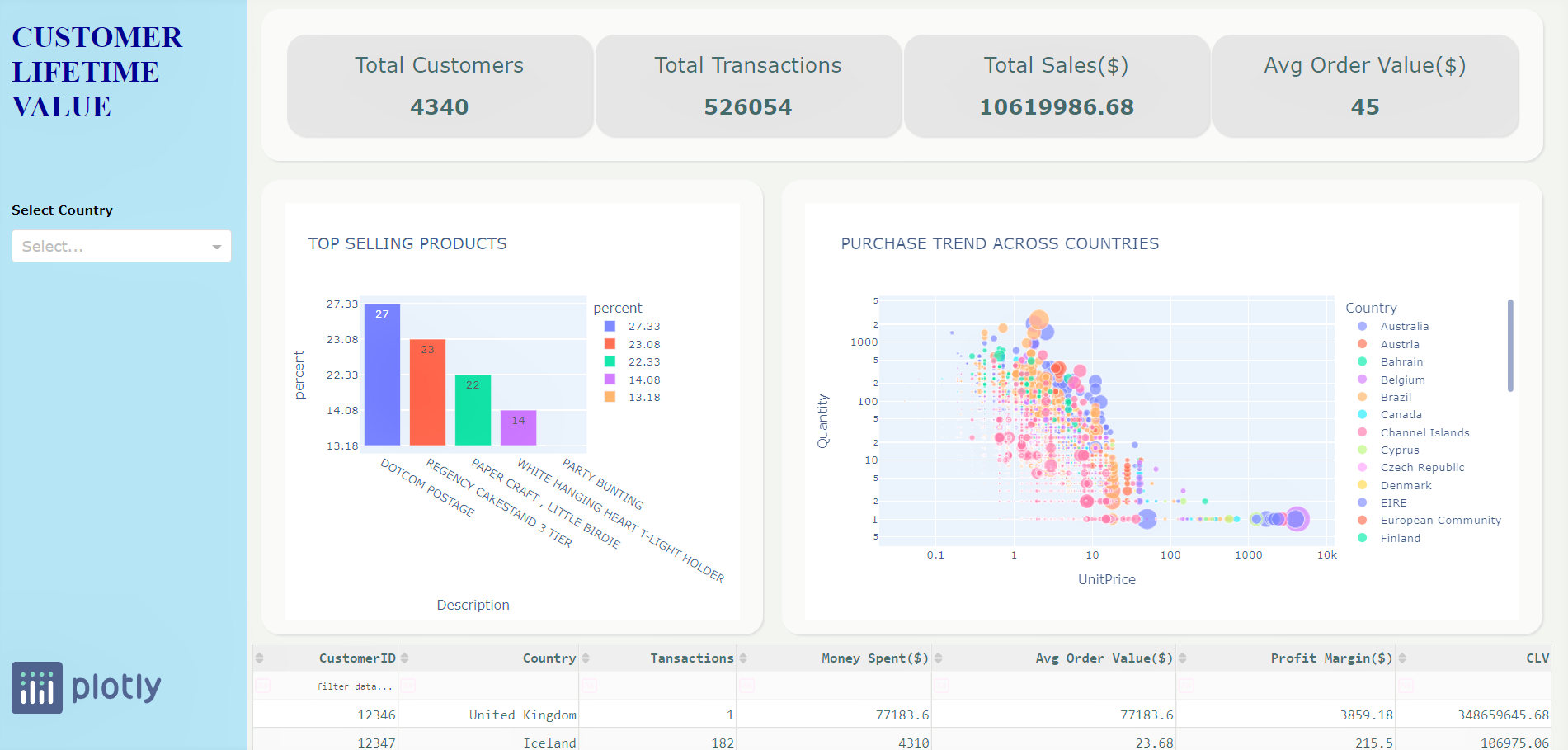
Cards: All the 4 KPI’s that we are tracking will be at the top of the page. The aesthetics like font size and color are defined. Also, a unique ID for each of the card which will be used later to populate the values.
html.H2('Total Customers', style={
'font-weight': 'normal'}),
html.H2(id='id_total_customer', style = {'color': 'DarkSlateGray'}),
], className='box_emissions'),
html.Div([
html.H2('Total Transactions', style={
'font-weight': 'normal'}),
html.H2(id='id_total_transactions', style = {'color': 'DarkSlateGray'}),
], className='box_emissions'),
html.Div([
html.H2('Total Sales($)', style={
'font-weight': 'normal'}),
html.H2(id='id_total_sales', style = {'color': 'DarkSlateGray'}),
], className='box_emissions'),
html.Div([
html.H2('Avg Order Value($)', style={
'font-weight': 'normal'}),
html.H2(id='id_order_value', style = {'color': 'DarkSlateGray'}),
], className='box_emissions'),
Plots: We have 2 plots, one bar chart showcasing the top-selling products and the second with purchase trends for countries.
Barchart:
df_plot_bar = pp.filtered_data.groupby('Description').agg({'TotalPurchase':'sum'}).sort_values(by = 'TotalPurchase', ascending=False).reset_index().head(5)
df_plot_bar['percent'] = round((df_plot_bar['TotalPurchase'] / df_plot_bar['TotalPurchase'].sum()) * 100,2).apply(lambda x : "{:,}".format(x))
fir_plotbar = px.bar(df_plot_bar, y='percent', x='Description', title='TOP SELLING PRODUCTS', text='percent', color='percent',)
fir_plotbar.update_traces(texttemplate='%{text:.2s}', textposition='inside')
fir_plotbar.update_layout(uniformtext_minsize=8, uniformtext_mode='hide', showlegend=False)
Scatter Plot:
df_plot = df.groupby(['Country','Description','UnitPrice','Quantity']).agg({'TotalPurchase': 'sum'},{'Quantity':'sum'}).reset_index()
fig_UnitPriceVsQuantity = px.scatter(df_plot[:25000], x="UnitPrice", y="Quantity", color = 'Country',
size='TotalPurchase', size_max=20, log_y= True, log_x= True, title= "PURCHASE TREND ACROSS COUNTRIES")
Note: Similar to the cards and the plots, the rest of the UI components like the sidebar, the table for displaying the results are designed. Please access the completed layout.py code from Github
Step 3: Defining Interactivity (callback)
We define a function update_output_All() which takes the values from the controls as inputs, executes the logic, meaning generated the visuals and the data table, which will be populated on the UI. The interactivity is denied at 2 levels –
- App load: All the cards, plots, KPI’s and the table will have numbers from all the countries.
- User selection: Once the user selects a particular country, all the cards, plots, and tables will have data specific to the selected country.
def update_output_All(country_selected):
try:
if (country_selected != 'All' and country_selected != None):
df_selectedCountry = pp.filtered_data.loc[pp.filtered_data['Country'] == country_selected]
df_selectedCountry_p = pp.filtered_data_group.loc[pp.filtered_data_group['Country'] == country_selected]
cnt_transactions = df_selectedCountry.Country.shape[0]
cnt_customers = len(df_selectedCountry.CustomerID.unique())
cnt_sales = round(df_selectedCountry.groupby('Country').agg({'TotalPurchase':'sum'})['TotalPurchase'].sum(),2)
.........
return [cnt_customers, cnt_transactions, cnt_sales, cnt_avgsales, df_selectedCountry_p.drop(['num_days','num_units'], axis = 1).to_dict('records'),
fig_UnitPriceVsQuantity_country, fir_plotbar]
else:
cnt_transactions = pp.filtered_data.shape[0]
cnt_customers = len(pp.filtered_data.CustomerID.unique())
cnt_sales = round(pp.filtered_data.groupby('Country').agg({'TotalPurchase':'sum'})['TotalPurchase'].sum(),2)
cnt_avgsales = round(pp.filtered_data_group.groupby('Country').agg({'avg_order_value': 'mean'})['avg_order_value'].mean())
........
return [cnt_customers, cnt_transactions, cnt_sales,cnt_avgsales, pp.filtered_data_group.drop(['num_days','num_units'], axis = 1).to_dict('records'),
pp.fig_UnitPriceVsQuantity, fir_plotbar]
except Exception as e:
logging.exception('Something went wrong with interaction logic:', e)
Complete code can be accessed from app.py
Closing Note:
The objective of the blog was to introduce a formula approach to calculating the customer lifetime value (CLV) with python and build a dashboard/web app that can help business users make decisions on the fly. We also touched upon various aspects of building a data app right from data exploration to formulae and also touched upon some industry cases where CLV can be leveraged.
- This project setup can be used as a template to quickly replicate it for other use cases.
- you can build a more complex predictive model to calculate the CLV.
- Add more controls and plots relevant to your case with more interactivity.
Hope you liked the blog. Happy Learnings !!!!
You can connect with me – Linkedin
You can find the code for reference – Github
Reference:
https://unsplash.com/
I am a Data Science enthusiast with experience in building predictive models, data processing, and data mining algorithms to solve challenging business problems. Involved in open source community and passionate about building data apps.


