Introduction
Welcome back to my series of articles related to Data Science. Data Science has now become a very popular as well as an important field. Many big techies look for Data Scientists these days because data is a very crucial part of any organization and has to be handled very efficiently. One of the important aspects of Data Science is Image Processing. Organizations may have data in the form of text or images. For example, you must have used Google Lens which allows you to capture the photo and find similar images or articles closely related to that image in google search. How are they able to do all that? All these things require image processing and extracting data from it. Let’s see some aspects of image processing using Python:
1. How do machines look at images?
Before you move on, you need to know how images are actually processed by machines. Machines don’t look at the images the way humans look at them. Images are nothing but pixels. Image is represented in a 2-dimensional matrix where the x-axis is the width and the y-axis is the height of an image. The matrix consists of pixel values where each pixel has a range from 0 to 255. Here pixel value equal to 0 means black colour whereas 255 means white colour. Usually, each entry in the matrix is represented in RGB form. For example, we read an image as ‘img’, then
img[x, y] = (0,0,0)
The above example shows that x and y coordinates of ‘img’ are assigned values as (0,0,0) which is in (r,g,b) format.
Don’t worry things will become more clear as we move ahead. We will look at the basics of image processing in the next section. Before that just have a look at the image below and its pixel representation:
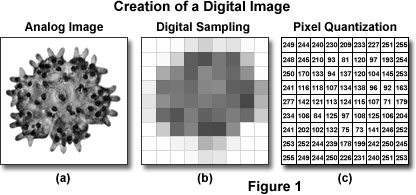
2. How to read images?
Images in python can be read as a 2-D matrix using python library OpenCV. Firstly, we will look at the introduction to OpenCV.
2.1 Introduction to OpenCV
OpenCV which stands for Open Source Computer Vision Library is an open-source computer vision and machine learning software library available in languages C++, Python, MATLAB, and Java. It is the most popular library used by Data scientists for image processing. It offers a variety of algorithms and techniques that could be applied to images. So throughout this article, we will be using the OpenCV library in python and sometimes sklearn library which can be equally useful as OpenCV.

Let’s install and import the OpenCV library with the help of the following code below:
!pip install cv2 import cv2 as cv
2.2 Read Images using OpenCV
Once you have installed the cv2 library and imported it into your python code, the next step is to read the image using the cv2 library.
import cv2 as cv
img=cv.imread('sample.jpg')
3. Image Resizing
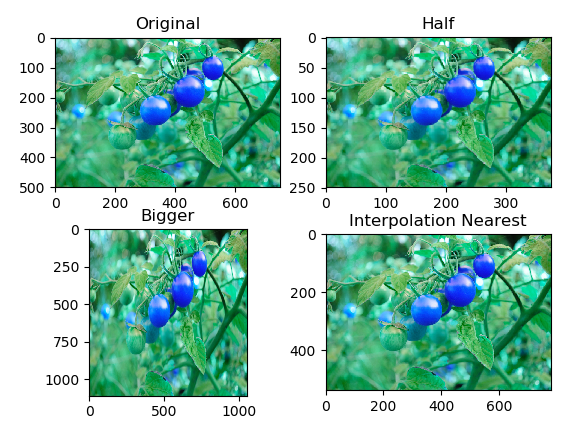
When you are trying to build your model and require image processing, then one of the important things that have to be kept in mind is that all images should be of the same size. This means that you have to rescale all your images to get uniformity in your dataset. Rescaling (or resizing) of images should be done in such a way that the original aspect ratio of the image is maintained.
It can be implemented using the cv2 library as follows:
image=cv2.imread('image.jpg')down_width=300down_height=200down_points=(down_width, down_height)resized_down=cv2.resize(image, down_points, interpolation=cv2.INTER_LINEAR)
4. Binarization of Images
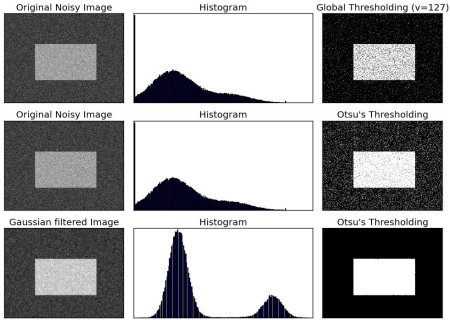
Now I am going to introduce you to one of the most important and interesting topics i.e. binarization. Binarization is of the image is converting a grayscale image into a black and white image (i.e. 0 and 255 pixels respectively). This can be achieved with the help of a process called thresholding. So, with the help of thresholding, we can get binary images. Now, thresholding can be defined as a process in which each pixel is converted to either 0 or 255 depending on whether its value is greater than or less than a threshold value. If the value of the pixel is greater than the threshold value, then it is converted to 255 otherwise it is converted to 1. This is how thresholding works.
Now there are 3 different types of thresholding techniques:
1. Simple Thresholding
In the simple thresholding method, we have to pass the parameter of threshold value to the function. So the threshold value is manually decided by the programmer after a lot of hits and trials whether the particular value is suitable for the image processing. This threshold value remains the same for every pixel and it is converted to 0 if its value is lesser than the threshold value and to 255 otherwise. This can be implemented with the cv2 library as follows:
import cv2 as cv
img = cv.imread('sample.png',) #reading the image
ret,thresh1 = cv,threshold(img,127, 255, cv.THRESH_BINARY)
The above code implements the function cv. threshold. It accepts the first argument as an image that should be grayscale. The second argument should be the threshold value that is used for converting the pixel. The third value is a maximum value which is 255 used in the above example. The fourth parameter is the type of thresholding used.

2. Adaptive thresholding
This method is sometimes more useful for binarization when the image has different lighting conditions. In the simple thresholding, we used a global threshold value for all pixels. In the case of adaptive thresholding, the algorithm divides the image into smaller regions and automatically determines the threshold value for each smaller region. This gives much better results than the global thresholding. It can be implemented using the cv2 library as follows:
import cv2 as cv
img = cv.imread('sample.png',)
th2 =cv.adaptiveThreshold(img, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY, 11, 2)
In the adaptive thresholding method, the first parameter is the image. The second parameter is the maximum value of the pixel. In the third argument, there can be 2 parameters that can be passed i.e. cv.ADAPTIVE_THRESH_MEAN_C and cv.ADAPTIVE_THRESH_GAUSSIAN_C. The fifth argument is the block size of the image i.e the size of the smaller region of the image. The last argument is the constant C.

3. Otsu’s Thresholding
This technique of Otsu’s thresholding is similar to the technique of simple thresholding. The only major difference is that here we don’t have to choose the global value of the threshold, unlike simple thresholding which explicitly requires the value of the threshold. This algorithm determines the threshold value automatically and applies it to get the best result. It is also implemented similarly, just cv.THRESH_OTSU is passed as an extra parameter.
ret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)
I hope you enjoyed my article. This article covered the most important part of image processing which is required in ML/AI projects.
About the Author:
Hi! I am Sarvagya Agrawal. I am pursuing B.Tech. from the Netaji Subhas University Of Technology. ML is my passion and feels proud to contribute to the community of ML learners through this platform. Feel free to contact me by visiting my website: sarvagyaagrawal.github.io
Hi, I'm Sarvagya Agrawal, Software Engineer, with a strong passion for utilizing technology to drive positive change in society. I believe that technology is not just a skill, but an art form that can be leveraged to transform the world.
My primary focus lies in machine learning and web development, with strong programming skills in Python. I have worked on innovative projects, including developing an AI model to calculate cardiovascular risk factors from OCTA scans using computer vision algorithms and creating an AI-based web application for calculating financial risk based on an individual's spending trends.






