Introduction
Data- a world-changing gamer is a key component for all companies and organizations. Data is a crucial and most effective part of any business. Dealing with the raw data which has no longer been accessible and cannot be utilized should be processed to use efficiently. Then here comes data-wrangling which helps to turn non-resourceful (raw) data into valuable data which in turn returns valuable information. Each step in the process of wrangling the data is to the best possible analysis. The outcome is expected to generate a robust and reliable analysis of the data.
This article was published as a part of the Data Science Blogathon
WHAT IS DATA WRANGLING?
Data Munging, commonly referred to as Data Wrangling, is the cleaning and transforming of one type of data to another type to make it more appropriate into a processed format. Data wrangling involves processing the data in various formats and analyzes and get them to be used with another set of data and bringing them together into valuable insights. It further includes data aggregation, data visualization, and training statistical models for prediction. data wrangling is one of the most important steps of the data science process. The quality of data analysis is only as good as the quality of data itself, so it is very important to maintain data quality. Wrangling isn’t just about wrangling, but it’s as important as the actual analysis process is done in the process of analyzing your data, it’s a key part of your analysis.
NEED FOR WRANGLING :
Wrangling the data is crucial, yet it is considered as a backbone to the entire analysis part. The main purpose of data wrangling is to make raw data usable. In other words, getting data into a shape. 0n average, data scientists spend 75% of their time wrangling the data, which is not a surprise at all. The important needs of data wrangling include,
- The quality of the data is ensured.
- Supports timely decision-making and fastens data insights.
- Noisy, flawed, and missing data are cleaned.
- It makes sense to the resultant dataset, as it gathers data that acts as a preparation stage for the data mining process.
- Helps to make concrete and take a decision by cleaning and structuring raw data into the required format.
- Raw data are pieced together to the required format.
- To create a transparent and efficient system for data management, the best solution is to have all data in a centralized location so it can be used in improving compliance.
- Wrangling the data helps make decisions promptly and helps the wrangler clean, enrich, and transform the data into a perfect picture.
DATA WRANGLING STEPS :
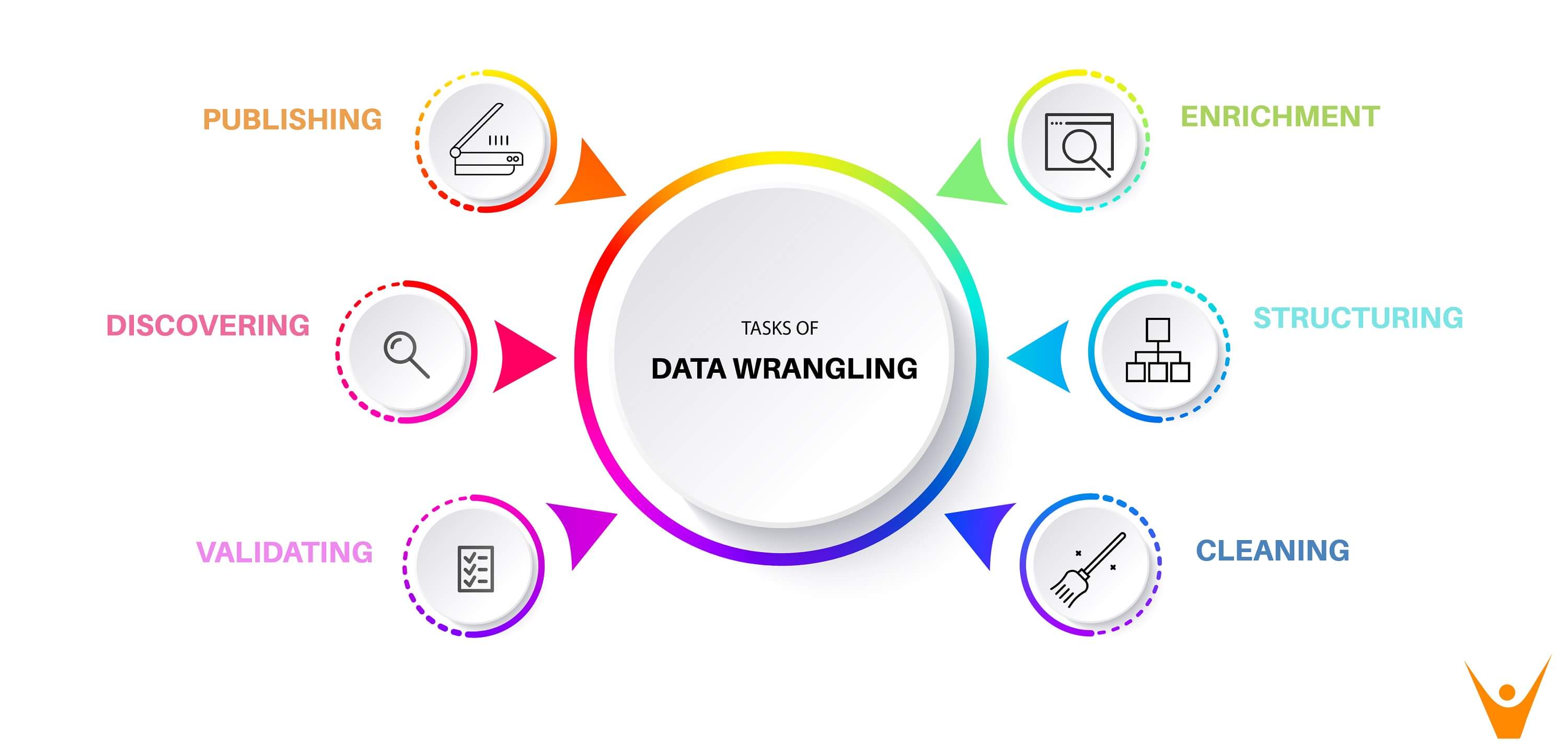
IMAGE SOURCE: https://favtutor.com
1. DISCOVERING :
Discovering is a term for an entire analytic process, and it’s a good way to learn how to use the data to explore and it brings out the best approach for analytics explorations. It is a step in which the data is to be understood more deeply. Based on some criteria, wrangling must be done, in which it divides the data accordingly. In the world of datum, learning to figure out the Holy Grail is pivotal.
2. STRUCTURING :
Raw data is given haphazardly. There will not be any structure to it in most cases because raw data comes from many formats of different shapes and sizes. One cannot look for a needle in a haystack, hence the data needs to be restructured properly. The data must be organized in such a manner where the analytics attempt to use it in his analysis part.
3. CLEANING :
High-quality analysis happens here where every piece of data is checked carefully and redundancies are removed that don’t fit the data for analysis. Data containing the Null values have to be changed either to an empty string or zero and the formatting will be standardized to make the data of higher quality. The goal of data cleaning or remediation is to ensure that there are no possible ways that the final data could be influenced that is to be taken for final analysis.
4. ENRICHING :
Enriching is like adding some sense to the data. In this step, the data is derived into new kinds of data from the data which already exits from cleaning into the formatted manner. This is where the data need to strategize that you have in your hand and to make sure that you have is the best-enriched data. The best way to get the refined data is to downsample, upscale it, and finally augur the data.
5. VALIDATING :
For analysis and evaluation of the quality of specific data set data quality rules are used. After processing the data, the quality and consistency are verified which establish a strong surface to the security issues. These are to be conducted along multiple dimensions and to adhere to syntactic constraints.
6. PUBLISHING :
The final part of the data wrangling is Publishing which gives the sole purpose of the entire wrangling process. Analysts prepare the wrangled data that use further down the line that is its purpose after all. The finalized data must match its format for the eventual data’s target. Now the cooked data can be used for analytics.
DATA WRANGLING IN PYTHON :
We use Pandas Framework in the below codes for data wrangling. Pandas is an open-source mainly used for Data Analysis. Data wrangling deals with the following functionalities.
- Data exploration: Visualization of data is made to analyze and understand the data.
- Dealing with missing values: Having Missing values in the data set has been a common issue when dealing with large data set and care must be taken to replace them. It can be replaced either by mean, mode or just labelling them as NaN value.
- Reshaping data: Here the data is either modified from the addressing of pre-existing data or the data is modified and manipulated according to the requirements.
- Filtering data: The unwanted rows and columns are filtered and removed which makes the data into a compressed format.
- Others: After making the raw data into an efficient dataset, it is bought into useful for data visualization, data analyzing, training the model, etc.
EXECUTION OF DATA WRANGLING STEPS IN PYTHON :
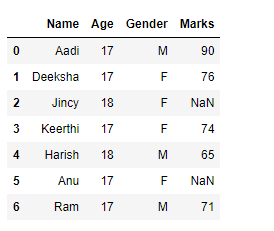
1. DATA EXPLORATION,
Here, the visualization of data is done in a tabular format.
Python Code:
import pandas as pd
# Import pandas package
import pandas as pd
# Assign data
data = {'Name': ['Aadi', 'Deeksha', 'Jincy',
'Keerthi', 'Harish', 'Anu', 'Ram'],
'Age': [17, 17, 18, 17, 18, 17, 17],
'Gender': ['M', 'F', 'F', 'F', 'M', 'F', 'M'],
'Marks': [90, 76, 'NaN', 74, 65, 'NaN', 71]}
# Convert into DataFrame
df = pd.DataFrame(data)
# Display data
print(df)OUTPUT :
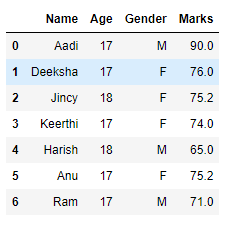
2. DEALING WITH MISSING VALUES,
Here, the null values present in the data in the marks column are removed and replaced with the mean value.
# Compute average
c = avg = 0
for ele in df['Marks']:
if str(ele).isnumeric():
c += 1
avg += ele
avg /= c
# Replace missing values
df = df.replace(to_replace="NaN",
value=avg)
# Display data
df
OUTPUT :
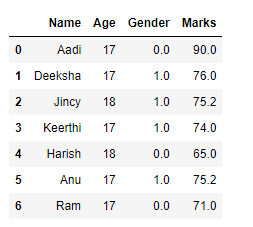
3. RESHAPING THE DATA,
The categorical values can be represented by a numerical value. As the data contain categorical values in the gender column, it can be reshaped by categorizing them into numbers.
# Categorize gender
df['Gender'] = df['Gender'].map({'M': 0,
'F': 1, }).astype(float)
# Display data
df
OUTPUT :
4. FILTERING,
Here the data is restructured to the specific format by removing the unwanted data in a table.
# Filter top scoring students df = df[df['Marks'] >= 75] # Remove age row df = df.drop(['Age'], axis=1) # Display data df
OUTPUT :
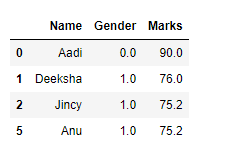
Now the data is refined into efficient data by doing some basic data wrangling steps, which can be next used for various purposes.
IS DATA-WRANGLING WORTH THE EFFORT?
It may daunt a lot amount of time and work to get proper data. There must be hard labour to show that cascading the results in the processing phase. The process of wrangling the data extremely turns the data into different insights, redirecting the entire project into valuable outcomes. A solid foundation is needed to keep the building process alive and serve a better purpose for future generations. Results may be driven quickly once the data is placed with a proper code and infrastructure. Skipping it will drop down the entire process ridiculously and that brings a major flop to the analytics reputation within the organization.
CONCLUSION :
To this end, It is understood how important data wrangling for data, and its potential to change the whole process upside down. The foundation of data science comes from good data. Hence optimized results can be obtained from optimized data to get optimized outcomes. Hence wrangle the data, before processing it for analysis.





