Ref :https://www.dropbox.com/app-integrations/slack
Introduction:
Slack is a communication platform. Users send messages inside of channels. Channel is a self-selected group of people who have the same– who are interested in the same topic. Users send messages, upload files, search for content, and interact with apps inside of Slack. In the beginning, Slack customers are small teams with a few dozen and hundreds of users. Today, Slack has gigantic organizations with hundreds and thousands of users. The height of the tree is proportional to the size of our biggest team. In 2015, that’s 8,000 users. In 2016, that’s three times bigger than the year before. Today, Slack has 366,000 users on our biggest team. That is 33 times more than three years ago. The design decision showed their limitations.
Challenges:
The first challenge slack had is slowness connecting to Slack. As they onboarded larger and larger teams, users reported slowness in connecting to Slack. They had to investigate. To understand why that’s a challenge, let’s look at the connect flow.
Ref: https://slack.engineering/how-slack-built-shared-channels/
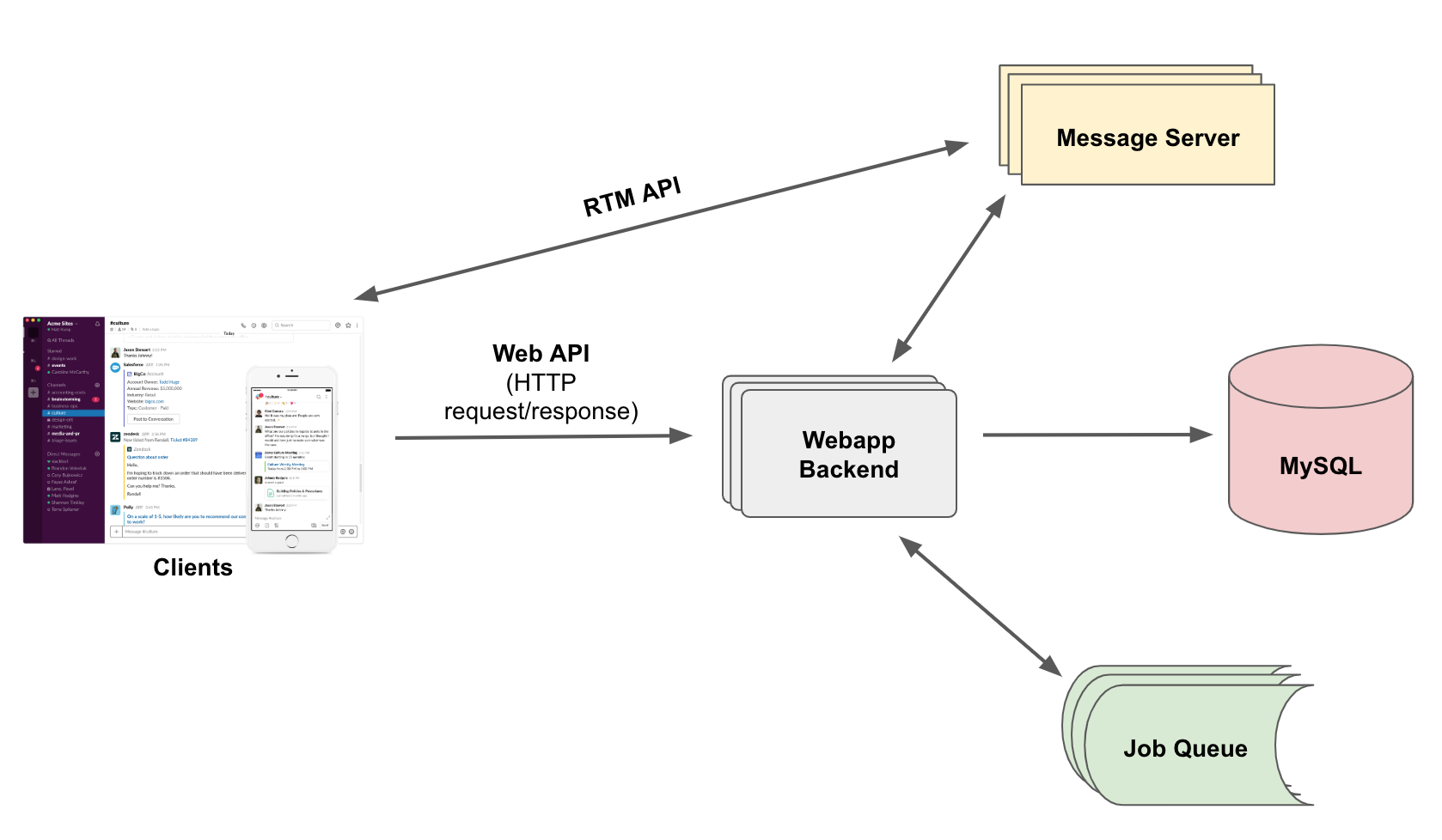
When you launch Slack, the client sends an HTTP request to the server. The server validates your token and it sends a snapshot of your team. Then a WebSocket connection is established. On that connection, real-time events are sent to the client. That’s how the client is up to date with what’s happening on your team. And the WebSocket connection is a dual-class communication protocol based on TCP. The user connect time is from when the first HTTP request is sent till the WebSocket connection is established. That it’s when the client is ready to use.
The bottleneck here is the client wants to download the snapshot of your team before it’ll be ready to use.
The snapshot, including who’s on your team, what channels you are in, and who is in those channels. The exact number does not matter. But the takeaway is it can grow easily to a few dozen megabytes with a few thousand users or channels. Why client needs those users and channels information at boot time? That was a decision made early in the early days. It made various features easy to implement and made the user experience seamless. Fast forward to now. That design decision is no longer suitable for big teams. Slack did some incremental changes to squeeze the size, like remove some fields out of the initial payload or change the field’s format to make it more compressed. At some point, slack reached the limit no matter how hard they try. The snapshot is still a big chunk of data. So we need an architectural change.
Architecture Change:
The idea is simple, current lazy loading. Load fewer data at boot time and load more data on demand. This means for clients need to rewrite their data access layer. It cannot make an assumption that all data is available locally. Still, we want the user experience to be seamless.
When data is fetched remotely, there is networking round trip time. So slack decided– that they will set up a service that answers client queries. It is backed by cache and deployed at locations. So it guarantees fast data access. We called this service Flannel. You may ask why the name Flannel. Any guesses? Naming, as we all know, is very difficult in computer science. On the day when the project was kicked off, the lead engineer happened to wear a flannel shirt. That’s why. In summary, Flannel is a query engine backed by cache. It is deployed on edge locations for fast data access. Slack engineers went through two stages to roll out Flannel. The goal of stage one is to deploy lazy loading as fast as possible with minimum dependency on other parts of the backend system. And then we take stage two to optimize for performance. I will go into detail on these two stages.
Optimization Stages:
Stage one, a man in the middle– remember, the client establishes a WebSocket connection to the server. That is the real-time message API. Real-time events flow onto this connection. That’s how slack keeps the clients up to date. Slack places Flannel on this WebSocket connection. Flannel receives all the events. It passes along all of them to the clients and uses some of those events to update its cache. The client sends queries to Flannel. Flannel answers those queries by data in its cache. The cache is organized by team. When the first user on the team connects, Flannel loads the team data to its cache. As long as there is one user on the team staying connected, Flannel will keep the cache up to date. When the last user disconnects, then Flannel unloads the cache. The charm of this design is it requires no change on other parts of the backend system. In this stage, we also roll out a just-in-time annotation. That is an optimization for clients. Flannel predicts what object clients might query next and pushes the object to the clients proactively.
Let me give you an example.
Say user Alice on the team sends a message. The message is broadcast to all channel members. Each client needs the user Alice to render the message. Flannel maintains an ARU cache to track for each client what are the recent queried objects. It detects client A did not recently query Alice. So it probably does not have the data. So it pushes the user Alice object with the message to the client. For clients B and C, they recently queried user Alice, so Flannel just sends a message. After this stage, the bottleneck in user connect flow was eliminated. The user connects time for our biggest team dropped to 1/10. The flannel cache is in process memory. Flannel is deployed to multiple Agile locations. It is close to users, so the proximity provides faster data access. Clients use geo-based DNS to figure out which region they should connect to.
Inside each region, there is team affinity meaning all users on the same team connect to the same Flannel host. Proxy is sitting in front of the flannel. It routes traffic based on team ID using consistent hashing– using a consistent hash. There are several areas for improvement for improvements after stage one. First, as a man in the middle, Flannel stays on every WebSocket connection. For many events, they are broadcast to all members of the team or all members in the channel, so there’s a lot of duplicated events. It costs a lot of CPU to read and process this message. Second, cache update is tied to WebSocket connections. When the first user comes, Flannel loads the cache. When the last user leaves, it unloads the cache. This means for the first user on the team it will always hit a code cache. This is not an ideal experience for the first user on the team. So we did stage two to improve this. The key is to introduce a Pub/Sub into the system. We architected our real-time message API so that Flannel can subscribe to the list of teams and channels based on who is connected. And through Pub/Sub, it can receive events only once. Not only that, but also it provides flexibility in how Flannel manages its cache. Now, cache update is no longer tied to the WebSocket connection. Flannel can pre-warm the cache even before the first user comes online.
I will share with you some results. The graph shows user change events on one of our biggest teams. Before Pub/Sub, it peaks to 500,000 per 10 seconds. And after Pub/Sub, it merely hit 1,000. There’s a 500 times reduction. By the way, a user change event is just one type of event that goes on the WebSocket connection and is used by Flannel to update the cache, the user object. We also moved some queries from the web tier, which are hosted in US East, our main region, to Flannel. This graph shows the latency of the channel membership query. The green-yellow, blue felines are P50, P90, P99 latency. P99 latency dropped from 2,000 milliseconds to 200 milliseconds after it migrated to Flannel. First, why not use Memcache? The reasoning is Flannel needs to serve to autocomplete queries. Autocomplete, for example, is used in QuickSwitcher. When you open QuickSwitcher and then start to type, it populates you with users and channel suggestions that you can navigate to. In order to serve to autocomplete queries, the Flannel keeps the index in memory, and the index does not really fit into Memcache’s key-value pattern.
Second question– how is Pub/Sub implemented?
It is built in-house. A follow-up question nominee is why not use Kafka? In the early days, we built our own messaging system. It is very stable and performant. Over time, it evolved to where it is today. If we had switched to Kafka, it would have cost us more effort and operational cost. Third question– how do you deal with reconnect storm? This actually leads to the second challenge I am going to talk about. I don’t have a perfect answer yet. This is something we’re actively working on. Reconnect storm– it can be triggered by either a regional networking problem or a bug in our software. We lost thousands and hundreds of thousands of connections within minutes or even seconds. And the client reconnects and keeps retrying in the background. The traffic overloaded the backend system. We want a way for our backend system to be able to sustain huge spikes of traffic and to be able to serve them within a short amount of time.
At this point, it is not only about Flannel, it is the whole Slack system that needs to be engineered accordingly. Actually, we had an incident last year the day before Hollywood. Within two minutes, we lost 1.6 million WebSocket connections due to a bug in Flannel. Some Flannel hosts crashed. The reconnect traffic goes to the healthy ones. They get overloaded, they crash, and then the failure cascaded to the whole cluster. It took us 135 minutes to recover traffic to its normal level. This instant exposed several bottlenecks in our system. The first thing that went down was EOB, the load balancer. It is the front end of our web tier hosted on AWS. The reconnect traffic overwhelmed that EOB cluster.
The whole cluster becomes unreachable, became unreachable. It took us 45 minutes. We had to scale it fast enough. It took us 45 minutes to scale another EOB cluster and point traffic to it. In the meanwhile, we heavily rate limit the incoming traffic that hit our own services. Here is a configuration file of the rate limits we have. There are several different types. They’re all added with time when the new constraint was found in the system. However, it is very hard to figure out what the numbers should be set to. We can only get a number after we do a thorough dot testing, but the number can go stale very quickly with new features being developed, new servers being provisioned, and new traffic patterns in production. And you see, there are many knobs that we can tune. It is really hard to get it right. It is even harder in the incident. So when that incident happened, we did it very conservatively. That is also one of the contributing factors to why it took us so long to recover. In the postmortem meeting, everyone agrees that we need to handle the thunderhead problem more gracefully.
Distributed System:
Failures are inevitable in a distributed system. This time, it is due to a bug. Next time, it may be something new. The question we need to answer is how to avoid cascading failures, and second how to minimize recovery time. One solution to avoid cascading failures is admission control. So the server only serves traffic that it can afford to reject excessive traffic. For example, say, the server can only serve 1,000 requests per second when you send it 10,000 requests. It is still able to serve 1,000 of them or close to 1,000 of them and reject the rest, 9,000. In Flannel, we monitor memory usage. If the memory usage exceeds our threshold, then Flannel starts to reject traffic. It only allows traffic to go through if the memory usage goes down to a normal level. Another thing we adopted is to use a circuit breaker. When Flannel detects the failure rate of these upstream services starts to go up, it starts to reject traffic. It uses a feedback loop to control how many requests it sends to the backend services. So this gave the backend services a chance to recover. With admission control and circuit breaker, we think we no longer need the menu rate limit. The system can shut traffic automatically.
Our next step is to scale the Flannel up automatically. We believe for success in scaling up policy, two things are very important– one, the metric used to scaling up and scaling down, second, the speed of scaling up. It is not easy to scale up a service that has a cache component in it. Slack has a few ideas that we are experimenting with. Hopefully, I can share with you more next time. Another thing we’re looking at right now is the regional failover. Regional failover does not really help with the thunderhead problem, but it is important for resiliency. Flannel is deployed to 10 different Agile locations. When failures happen in one of the locations and if the failure is isolated to that Agile location, then we should failover traffic to other nearby regions. The question we need to answer is how much traffic to route to other nearby– to each of the nearby regions and how to capacity planning for each of those regions. I don’t have an answer yet. Our goal is to be able to reconnect one WebSocket connection within five minutes. We believe with admission control, circuit breaker, and auto-scaling we are going to get there.
New things might pop up along the way. If you are interested in these problems, you’re welcome to talk to Slack Engineers or read some blogs. Slack embraces innovative solutions and we push them out incrementally. There’s not more to build to improve resiliency, reliability, and performance.
Hope you liked the high-level overview of Slack Data Engineering more of a Platform Engineering.






It's amazing! Thanks