This article was published as a part of the Data Science Blogathon
Text Generation
The Text Generation is a Natural Language Processing task that involves automatically generating meaningful texts. We can also utilize the Text Generation process for Autocomplete. Initially, we provide a prompt, which is a text that is used as the base to generate texts. The model will generate texts based on the prompt, the predicted text will be added to the base prompt and it is fed again to the model. In this way, we can generate many texts using the prompt text.

Text generation is also called Natural Language Generation. Text generation can be used in chatbots creation and autocomplete. The quality of the Text Generation depends on the quality of the corpus. A corpus is a set of documents that are used to train the model for text generation. If the quality of the data is not good then the model’s quality is not good as well (Garbage in, Garbage out). In order to feed the quality data, we need to preprocess the data. To train a text generation model you need to follow the following steps,
- Prepare the data by preprocessing it.
- Generate n-gram sequences
- Pre-pad the sequences
- Use the last word in the padded sequences as the target
- Train the model
- Utilize it for predictions
Hang tight, we are going to explore the above-mentioned steps in this post. We are gonna see how text generation works in detail.
Text Generation in Tensorflow
We require spaCy for preprocessing. Follow the instructions on this webpage to install spaCy. We are gonna be using TensorFlow for modeling, so install TensorFlow if you don’t have it installed. To install TensorFlow, follow the instructions on this webpage.
python -m spacy download en_core_web_sm
Execute the above command after installing spaCy. It is the trained pipeline package of spaCy. We are going to utilize it for preprocessing.
We are going to use the Irish Lyrics Eof dataset for training. You can download the dataset using the following command.
wget --no-check-certificate
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/irish-lyrics-eof.txt
-O /home/data/irish-lyrics-eof.txt
After executing the above command the data will be stored in the following path, /home/data/irish-lyrics-eof.txt
Import the required libraries
import re
import spacy
import numpy as np
import pandas as pd
import en_core_web_sm
import tensorflow as tf
from nltk.stem import WordNetLemmatizer
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.models import Sequential
from spacy.lang.en.stop_words import STOP_WORDS
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional, Dropout
# load the data
data = open('/home/data/irish-lyrics-eof.txt').read()
nlp = en_core_web_sm.load()
lemmatizer = WordNetLemmatizer()
DISABLE_PIPELINES = ["tok2vec", "parser", "ner", "textcat", "custom", "lemmatizer"]
stopwords = STOP_WORDS
We can load the spaCy’s trained pipeline using the command en_core_web_sm.load(). We are also initializing the lemmatizer for preprocessing.
class TextPreprocessor:
def __init__(self, filters):
self.filters = filters
def preprocess_text(self, doc):
tokens = [
token
for token in doc
if not token.is_space and
not token.like_email and
not token.like_url and
not token.is_stop and
not token.is_punct and
not token.like_num
]
translation_table = str.maketrans('', '', self.filters)
translated_tokens = [
token.text.lower().translate(translation_table)
for token in tokens
]
lemmatized_tokens = [
lemmatizer.lemmatize(token)
for token in translated_tokens
if len(token) > 1
]
return lemmatized_tokens
# spaCy preprocessing
tp = TextPreprocessor(filters=FILTERS)
splitted_data = data.split('n')
texts = [
tp.preprocess_text(doc)
for doc in nlp.pipe(splitted_data, disable=DISABLE_PIPELINES)
]
The class TextPreprocessor does the following steps,
- Removes the white spaces in the text
- Removes the text with email
- Removes the text with URL
- Removes the text with stopwords, this also removes the contractions
- Removes the punctuations in the text
- Removes the text that contains numbers
- Lemmatization
First of all, the spaCy breaks down all the list of sentences into a list of docs. A doc in spaCy is a sequence of token objects. The disabled pipelines mentioned above are the ones that we are not going to use, by disabling them we could speed up the process. As mentioned above each doc is a sequence of token objects, we iterate through them and remove white spaces, email, URL, stopwords, punctuations, and numbers.
Lemmatization is the process of finding the base of the word. For example, the lemma of the word ‘running’ is run. There is another technique called stemming which is very similar to lemmatization, but the difference between the two is that lemmatization produces a meaningful word according to the dictionary whereas stemming would not produce meaningful words. The purpose of using lemmatization is to reduce the vocabulary size.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
total_words = len(tokenizer.word_index) + 1
# convert data into ngram sequences
input_sequences = []
for sentence in texts:
token_list = tokenizer.texts_to_sequences([sentence])[0]
for i in range(1, len(token_list)):
input_sequences.append(token_list[:i+1])
max_sequence_len = max([len(x) for x in input_sequences])
# pad the data
input_sequences = np.array(
pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre')
)
# split data into features and target
features, labels = input_sequences[:,:-1], input_sequences[:,-1]
target = tf.keras.utils.to_categorical(labels, num_classes=total_words)
After preprocessing the texts using spaCy, we are going to convert the preprocessed texts into a sequence of numbers. For example, the sentence [‘I’, ‘am’, ‘happy’] would be converted to [1, 2, 3]. For training a text generation model we need to generate n-gram sequences out of one sentence. Let’s take the example above, the sentence [‘I’, ‘am’, ‘happy’] would be used to generate following n-gram sequences [‘I’, ‘am’], [‘I’, ‘am’, ‘happy’]. These n-gram sequences will be generated and appended to the variable input_sequences. After converting the texts to n-grams we will pad the entire texts. For example, let’s say the maximum length of a sentence in a corpus is 5 and if we pre pad the text used in the above example it would be [0, 0, 1, 2, 3].
The input sequences would look like this,

After pre-padding the sequences we are going to utilize the last word in a sentence as the target. Now that we have prepared the dataset we can now proceed to train the model. We are going to use Bidirectional LSTM (Long Short Term Memory) to train the model. Do you want to know what is LSTM? Have a look at this blog.
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150)))
model.add(Dense(total_words, activation='softmax'))
adam = Adam(learning_rate=0.01)
model.compile(
loss='categorical_crossentropy',
optimizer=adam,
metrics=['accuracy']
)
history = model.fit(
features,
target,
epochs=10,
batch_size=64
)

The first layer of the model is the Embedding layer. The Embedding layer is used to convert the text to vectors. The purpose of converting the text to vectors is that we can find similarities between the words better than using one-hot encoding. For example, the word ‘orange’ might be embedded as [1.5, 4.5, 6.6] which is a three-dimensional vector. The number of dimensions you need to produce is the hyperparameter, you can choose any positive value for embedding dimension.
The next layer is the bidirectional LSTM (Long Short Term Memory) with 150 units. After that layer, we have used a dense layer with the total number of words in the corpus. We have used the softmax activation function as it produces multi-class output. We have used Adam optimizer for loss function optimation. The loss function that we have used is categorical cross-entropy and the metric we used is the accuracy. The difference between the loss function and the metric is that the loss function is used to optimize the model whereas the metrics are used for the comparison and not used for optimization. We have used a batch size of 64 and 10 epochs.
The training results are as follows,
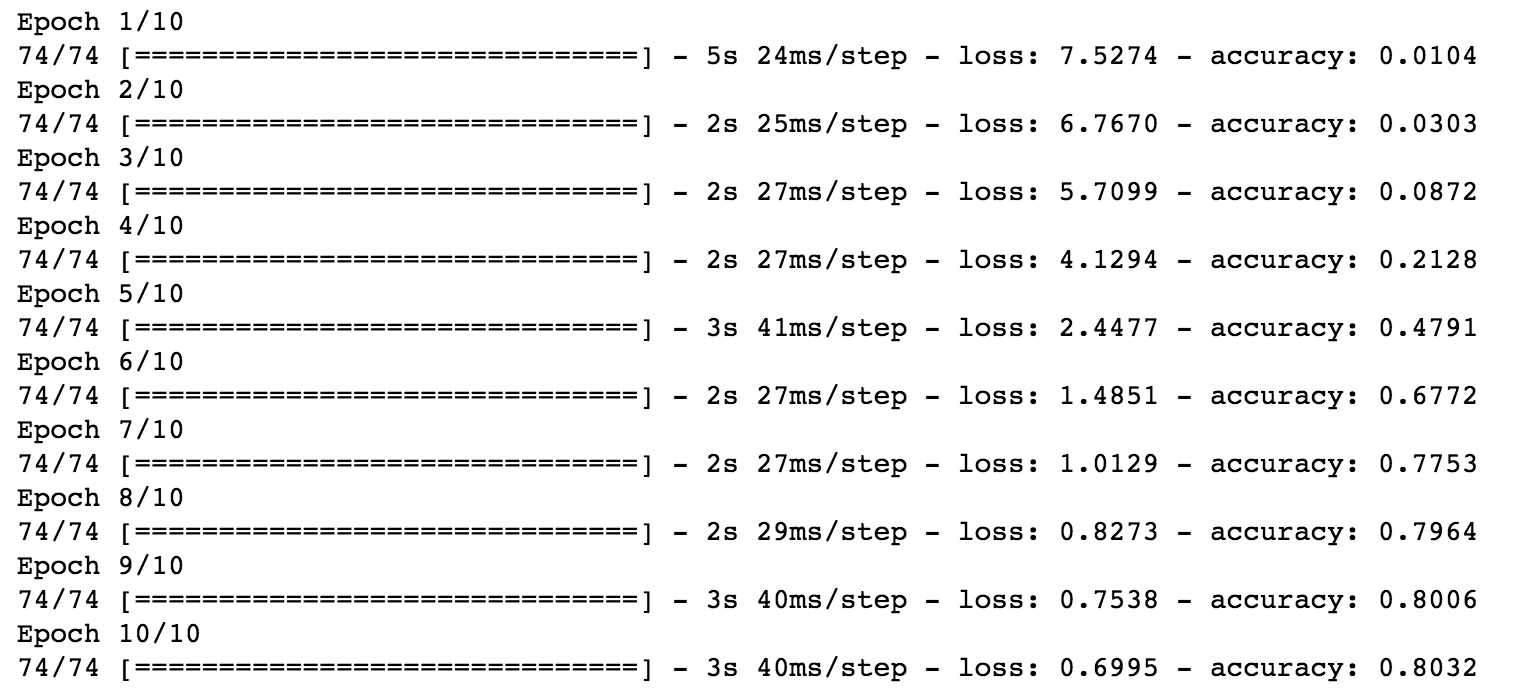
Image Source: Author’s Jupyter Notebook
With just 10 epochs, the model has produced 80 percent of accuracy. Try changing the number of epochs to increase the accuracy. Now that we have trained our model, let us plot the history.
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
plt.title("History")
plt.xlabel("Epochs")
plt.ylabel('accuracy')
plt.show()
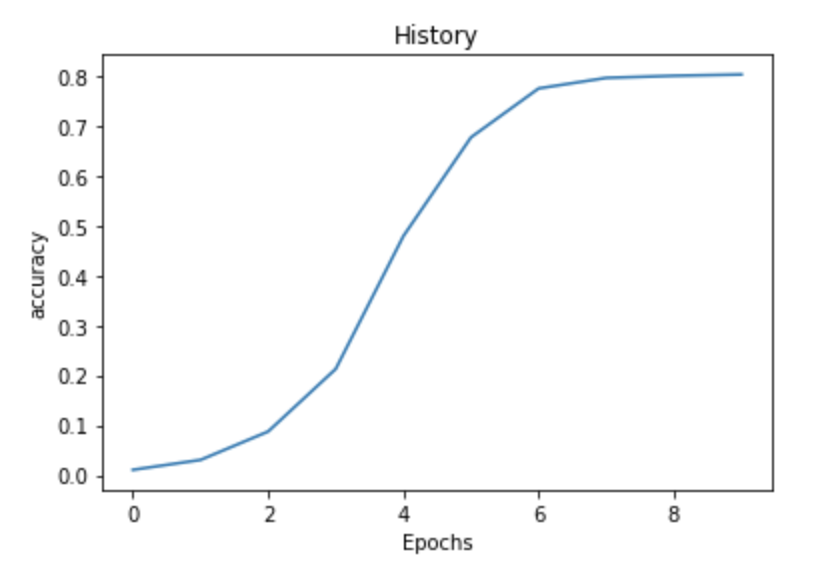
By looking at the plot we can say that as the epochs increase there is an increase in the accuracy. In other words, the accuracy of the model increases as the number of epochs increases, which is a good sign of progress. Now that we have trained a model, we can use it to predict the next words and generate texts.
inverted_word_index = {v: k for k, v in tokenizer.word_index.items()}
seed_text = "This is the good day of my life"
processed_text = tp.preprocess_text(nlp(seed_text))
processed_sentence = " ".join(processed_text)
next_words = 100
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([processed_sentence])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = model.predict_classes(token_list, verbose=0)
processed_sentence += " " + inverted_word_index[predicted[0]]
print(processed_sentence)
In the code above the prompt sentence is “This is the good day of my life”. We will preprocess it, convert it to sequences, and pad the sentence. After that, we feed it to the model which predicts a word. We append this word to the prompt sentence itself and again do the same process. We iteratively perform these operations until the specified number of words are attained. In this way, you can utilize Bidirectional LSTM for Text Generation.
Summary
- Preprocess the text data
- Convert the preprocessed text data into sequences of numbers
- Pad those sequences
- Generate n-gram sequences and use the last word as the target
- Train the Bidirectional LSTM model with appropriate parameters
- Utilize the model to make predictions
Don’t hold yourself back from experimenting with the hyperparameters of the model. You can tune these hyperparameters to get better results. The tunable parameters are the number of layers, activation function, epochs, batch size, and etc. You can play with these parameters and find the optimal parameters.
Happy Deep Learning!
Connect with me on LinkedIn.
Machine Learning Engineer @ Zoho Corporation






