This article was published as a part of the Data Science Blogathon
Hello readers!
In this article, I am going to discuss one of the most essential parts of Apache Spark called RDD.
Before getting into Spark RDD, I strongly recommend you to read this article, Understand the internal working of Apache Spark to get an overview of the working of Apache Spark.
Table of contents
What is RDD in Spark?
An RDD (Resilient Distributed Dataset) is a core data structure in Apache Spark, forming its backbone since its inception. It represents an immutable, fault-tolerant collection of elements that can be processed in parallel across a cluster of machines. RDDs serve as the fundamental building blocks in Spark, upon which newer data structures like datasets and data frames are constructed.
RDDs are designed for distributed computing, dividing the dataset into logical partitions. This logical partitioning enables efficient and scalable processing by distributing different data segments across different nodes within the cluster. RDDs can be created from various data sources, such as Hadoop Distributed File System (HDFS) or local file systems, and can also be derived from existing RDDs through transformations.
Being the core abstraction in Spark, RDDs encompass a wide range of operations, including transformations (such as map, filter, and reduce) and actions (like count and collect). These operations allow users to perform complex data manipulations and computations on RDDs. RDDs provide fault tolerance by keeping track of the lineage information necessary to reconstruct lost partitions.
In summary, RDDs serve as the foundational data structure in Spark, enabling distributed processing and fault tolerance. They are integral to achieving efficient and scalable data processing in Apache Spark.
Features of Spark RDD
Spark RDD possesses the following features.
Immutability
The important fact about RDD is, it is immutable. You cannot change the state of RDD. If you want to change the state of RDD, you need to create a copy of the existing RDD and perform your required operations. Hence, the required RDD can be retrieved at any time.
In-memory computation
Data stored in a disk takes much time to load and process. Spark supports in-memory computation which stores data in RAM instead of disk. Hence, the computation power of Spark is highly increased.
Lazy evaluation
Transformations in RDDs are implemented using lazy operations. In lazy evaluation, the results are not computed immediately. It will generate the results, only when the action is triggered. Thus, the performance of the program is increased.
Fault-tolerant
As I said earlier, once you perform any operations in an existing RDD, a new copy of that RDD is created, and the operations are performed on the newly created RDD. Thus, any lost data can be recovered easily and recreated. This feature makes Spark RDD fault-tolerant.
Partitioning
Data items in RDDs are usually huge. This data is partitioned and send across different nodes for distributed computing.
Persistence
Intermediate results generated by RDD are stored to make the computation easy. It makes the process optimized.
Grained operation
Spark RDD offers two types of grained operations namely coarse-grained and fine-grained. The coarse-grained operation allows us to transform the whole dataset while the fine-grained operation allows us to transform individual elements in the dataset.
How to create RDD?
In Apache Spark, RDDs can be created in three ways.
- Parallelize method by which already existing collection can be used in the driver program.
- By referencing a dataset that is present in an external storage system such as HDFS, HBase.
- New RDDs can be created from an existing RDD.
Operations of RDD
Two operations can be applied in RDD. One is transformation. And another one in action.
Transformations
Transformations are the processes that you perform on an RDD to get a result which is also an RDD. The example would be applying functions such as filter(), union(), map(), flatMap(), distinct(), reduceByKey(), mapPartitions(), sortBy() that would create an another resultant RDD. Lazy evaluation is applied in the creation of RDD.
Actions
Actions return results to the driver program or write it in a storage and kick off a computation. Some examples are count(), first(), collect(), take(), countByKey(), collectAsMap(), and reduce().
Transformations will always return RDD whereas actions return some other data type.
Practical demo of RDD operations
Let’s take a practical look at some of the RDD operations. To practice Apache Spark, you need to install Cloudera virtual environment. You can find a detailed guide to install Cloudera VM here.
Create RDD
First, let’s create an RDD using parallelize() method which is the simplest method.
val rdd1 = sc.parallelize(List(23, 45, 67, 86, 78, 27, 82, 45, 67, 86))
Here, sc denotes SparkContext
and each element is copied to form RDD.

Read result
We can read the result generated by RDD by using the collect operation.
rdd1.collect
The results are shown
here.

Count
The count action is used to get the total number of elements present in the particular RDD.
rdd1.count

There are 10 elements in rdd1.
Distinct
Distinct is a type of transformation that is used to get the unique elements in the RDD.
rdd1.distinct.collect

The distinct elements are displayed.
Filter
Filter transformation creates a new dataset by selecting the elements according to the given condition.
rdd1.filter(x => x < 50).collect

Here, the elements which are less than 50 are displayed.
sortBy
sortBy operation is used to arrange the elements in ascending order when the condition is true and in descending order when the condition is false.
rdd1.sortBy(x => x, true).collect rdd1.sortBy(x => x, false).collect

Reduce
Reduce action is used to summarize the RDD based on the given formula.
rdd1.reduce((x, y) => x + y)
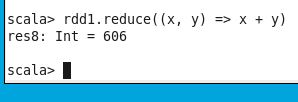
Here, each element is added and the total sum is printed.
Map
Map transformation processes each element in the RDD according to the given condition and creates a new RDD.
rdd1.map(x => x + 1).collect

Here, each element is incremented once.
Union, intersection, and cartesian
Let’s create another RDD.
val rdd2 = sc.parallelize(List(25,73, 97, 78, 27, 82))

Union operation combines all the elements of the given two RDDs.
Intersection operation forms a new RDD by taking the common elements in the given RDDs.
Cartesian operation is used to create a cartesian product of the required RDDs.
rdd1.union(rdd2).collect rdd1.intersection(rdd2).collect rdd1.cartesian(rdd2).collect

First
First is a type of action that always returns the first element of the RDD.
rdd1.first()
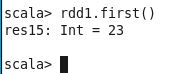
Here, the first element in rdd1 is 23.
Take
Take action returns the first n elements in the RDD.
rdd1.take(5)

Here, the first 5 elements are displayed.
Now, you may have noticed that when you do any transformations, only copies of existing RDDs are created and the initially created RDD doesn’t change. This is because RDDs are immutable. This feature makes RDDs fault-tolerant and the lost data can also be recovered easily.
When to use RDDs?
RDD is preferred to use when you want to apply low-level transformations and actions. It gives you a greater handle and control over your data. RDDs can be used when the data is highly unstructured such as media or text streams. RDDs are used when you want to add functional programming constructs rather than domain-specific expressions. RDDs are used in the situation where the schema is not applied.
Frequently Asked Questions
Q1. What is the purpose of RDD?
A. The purpose of RDD (Resilient Distributed Dataset) in Apache Spark is to provide a fault-tolerant and parallelized data structure for distributed computing. RDDs allow for the efficient processing of large-scale data across a cluster of machines by dividing the dataset into logical partitions and enabling transformations and actions on those partitions in parallel, achieving high-performance and scalable data processing.
Q2. What is spark context?
A. Spark Context, often referred to as sc, is the entry point and the main interface between a Spark application and the underlying Spark cluster. It represents the connection to a Spark cluster and serves as the driver program’s control and communication hub. Spark Context provides access to various Spark functionalities and resources, such as distributed datasets (RDDs), distributed variables, and cluster managers. It coordinates the execution of Spark tasks, manages the cluster resources, and handles the distribution of data and computations across the nodes in the cluster.
Endnote
I hope now you have a basic idea about the RDDs and their role in Apache Spark.
Thanks for reading, cheers!
Please take a look at my other articles on dhanya_thailappan, Author at Analytics Vidhya.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.


