This article was published as a part of the Data Science Blogathon
Introduction
Language is a structured medium we humans use to communicate with each other. Language can be in the form of speech or text. “Blah blah”, “Meh”, “zzzz…” Yup, we can understand these words. But the question is, “Can computers understand these?” Nop, machines can’t understand
these. In fact, machines can’t understand any text data at all, be it the word “blah” or the word “machine”. They only understand numbers. So, over the decades scientists have been researching how to make machines understand our language. And thus they developed all the Natural Language Processing or NLP Techniques.
What is Natural Language processing?
Natural language processing or NLP is a branch of Artificial Intelligence that deals with computer and human language interactions. NLP combines computational linguistics with statistical, machine learning, and deep learning models, allowing computers to understand languages. NLP helps computers to extract useful information from text data. Some of the real-world applications of NLP are,
- Speech recognition – The task of converting voice data to text data.
- Sentiment analysis- The task of extracting qualities like attitudes, emotions, etc. The most basic task in sentiment analysis is to classify the polarity of a sentence that is positive, negative, or neutral.
- Natural language generation – The task of producing text data from some structured data.
- Part-of-speech (POS) tagging – The task of tagging the Part of Speech of a particular word in a sentence based on its definition and context.
Some of the approaches to
process text data are Count Vectorization, Tf-Idf Vectorization, etc. These techniques help to convert our text sentences into numeric vectors. Now, the question arises, ‘Aren’t we processing the data using these techniques? So why do we need to pre-process it?’ This article gives an explanation for that doubt of yours. Instances of python code are also provided.
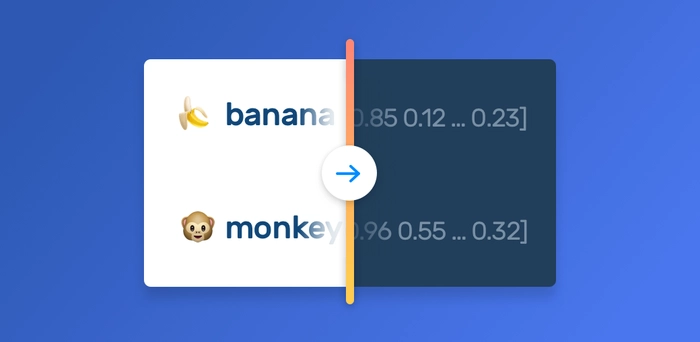
https://monkeylearn.com/blog/word-embeddings-transform-text-numbers/
Need for Pre-Processing
Raw text data might contain unwanted or unimportant text due to which our results might not give efficient accuracy, and might make it hard to understand and analyze. So, proper pre-processing must be done on raw data.
Consider that you scraped some tweets from Twitter. For example,
” I am wayyyy too lazyyy!!! Never got out of bed for the whole 2 days. #lazy_days “
The sentences “I am wayyyy too lazyyy!!!” and “I am way too lazy”, both have the same semantic meaning, but gives us a totally different vibe, right. Depending on how these data get pre-processed, the results also differ. Pre-processing is therefore the most important task in NLP. It helps us remove all the unimportant things from our data and make our data ready for further processing.
Some Python libraries for text pre-processing
Natural Language ToolKit (NLTK) :
NLTK is a wonderful open-source Python library that provides modules for classification, tokenization, stemming, tagging, etc.
Gensim:
Gensim is also an open-source Python library that mainly focuses on statistical semantics— estimation of the meanings of words using statistical methods, by looking at patterns of words in huge collections of texts. gensim.parsing.preprocessing module provides different methods for parsing and preprocessing strings.
Sci-kit Learn:
Some modules in sci-kit learn also provide some text preprocessing tools. sklearn.feature_extraction.text provides a module for count vectorization, CountVectorizer() that includes text preprocessing, tokenizing, and filtering of stop words. CountVectorizer() module contains preprocessor (it strip_accents and lowercase letters), tokenizer, stop_words as attributes. If set, this module does these for you along with count vectorizing- converting the text documents to a matrix of token counts.
How to pre-process text data?
Each data and task requires different pre-processing. For example, consider the sentence, “I am wayyy too lazyyy!!!”. If your task is to extract the emotion of the sentence, the exclamation marks, and how the words “wayyy” and “lazyyy” are written, all these become important. But if your task is just to classify the polarity of the sentence, these do not become important. So you can remove the exclamation marks and stem the words “wayyy” to way and “lazyyy” too lazy, to make further processing easier. Depending on the task you want to achieve, the steps for pre-processing must also be carefully chosen.
Some simple steps to pre-process the given example tweet for the basic sentiment analysis task of classifying the polarity are given below. Here I have used the gensim library.
- The first step of data pre-processing is, encoding in the proper format. utils.to_unicode module in the gensim library can be used for this. It converts a string (bytestring in encoding or Unicode), to unicode.
import gensim from gensim import utils s=" I am wayyyy too lazyyy!!! Never got out of bed for the whole 2 days. #lazy_days " s = utils.to_unicode(s) print(s)
Output:
I am wayyyy too lazyyy!!! Never got out of bed for the whole 2 days. #lazy_days
- Then convert all the uppercase letters to lowercase. “Never” and “never” are the same word, but the computer processes both as different words.
s = s.lower() print(s)
Output:
i am wayyyy too lazyyy!!! never got out of bed for the whole 2 days. #lazy_days
- Remove the tags and punctuations. They behave like noise in the text data since they have no semantic meaning.
import gensim.parsing.preprocessing as gp s=gp.strip_punctuation(s) s=gp.strip_tags(s) print(s)
Output:
i am wayyyy too lazyyy never got out of bed for the whole 2 days lazy days
- Remove all the numbers, because we are preparing the data for basic sentiment analysis (positive, negative, or neutral classification), where numbers are not important.
s=gp.strip_numeric(s) print(s)
Output:
i am wayyyy too lazyyy never got out of bed for the whole days lazy days
- Also, get rid of the multiple white spaces.
s=gp.strip_multiple_whitespaces(s) print(s)
Output:
i am wayyyy too lazyyy never got out of bed for the whole days lazy days
- Removing stop words is very important. Stop words refer to the most common words in a
language. ‘Is’, ‘and’, ‘the’, etc are some stop words in English. It can improve accuracy a lot.
s=gp.remove_stopwords(s) print(s)
Output:
wayyyy lazyyy got bed days lazy days
Stemming is also a very important step. Stemming is the process of reducing the words to their roots. For example, ‘stemming’ to ‘stem’. The stem_text() function returns porter stemmed version of the string. Porter stemmer is known for its speed and simplicity.
s=gp.stem_text(s)
These output strings can be used for further processing to convert into numeric vectors using techniques like Count Vectorization.
For our task of basic sentiment analysis, we have seen how to pre-process a single tweet till now. Hope you have understood each step clearly. The above processes can be done to a dataset of tweets.
import pandas as pd
import gensim
from gensim import utils
import gensim.parsing.preprocessing as gp
df = pd.read_csv(folderpath) #consider that df['tweets'] column contains tweets.
def preprocess_text(s):
s = utils.to_unicode(s)
s = s.lower()
s=gp.strip_punctuation(s)
s=gp.strip_tags(s)
s=gp.strip_numeric(s)
s=gp.strip_multiple_whitespaces(s)
s=gp.remove_stopwords(s)
s=gp.stem_text(s)
return s
df['tweets']=df['tweets'].apply(str) #to convert each row of tweets column to string type
df['tweets']=df['tweets'].apply(preprocess_text) #pass each row of tweets column to preprocess_text()
Thus, we have preprocessed our dataset of tweets.
Conclusion
Preprocessing text data is one of the most difficult tasks in Natural Language processing because there are no specific statistical guidelines available. It is also extremely important at the same time. Follow the steps that you feel are necessary to process the data depending on the task that you want to achieve.
Hope you enjoyed this article and learned something new. Thank you for reading. Feel free to share with your study buddies, if you liked this article.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.



